
はじめに
DATA FLUCTのYamaguchiです。今回は、回帰分析の初歩として、最もベーシックな2変数の回帰分析(単回帰分析)について分かりやすく説明したいと思います。
まず、世の中にある様々なデータのうち、互いに何らかの関係を持っているデータの種類の組み合わせがあります。身近な例でいうと
- 身長と体重
- 血圧と年齢
- 気温とアイスの売上
などでしょうか。例えば、「身長と体重」と聞くと、身長が高い人は体重が重いと想像するのは自然なことでしょう。「年齢と血圧」、「気温とアイスの売上」なども同様ですね。もちろん、「身長が高くて体重が軽い人」や「高齢なのに血圧が低い人」など例外も存在します。
全てのケースにおいて何らかの厳密な関係を当てはめることは出来ないですが、それでも何らかの「傾向」は認められ、それらを定量的に表現出来るのではないでしょうか。
相関関係とは
あるデータが持つ2つの変数に対して、片方が増減すればもう片方もある程度、規則的に増減するような関係のことを「相関関係」と言います。
ここで、注意が必要な点は相関関係があるからといって直ちに「因果関係」を認めないことです。以下で具体的な例を見てみましょう。
相関関係と因果関係
まずは相関関係と因果関係の両者が確認できる例をみてみましょう。
例えば、上の例で示したように「気温とアイスの売上」を考えてみましょう。日常的にアイスを食べる人もいると思いますが、特に暑い日では、普段に増して食べたくなるという人が大勢いると思います。
その結果、「暑い日が続くとアイスの売上も増える」ということが推測されます。逆に、寒い日ではどうでしょうか?暑い日に比べると食べたいという方は少数派でしょう。この場合、「気温」と「アイスの売上」には正の相関関係がみられると同時に、気温が上昇すればアイスの売上が増えることは明確です。よって、因果関係もみられることがわかりました。
続いて「年収」と「血圧」の関係ではどうでしょうか?
データをとってみると血圧が高い人は年収も高い傾向があることが分かりました。この時、「血圧を上げれば年収が上がる」、または「年収を上げれば血圧が上がる」という因果を導くことは正しい推論でしょうか?
普通に考えると正しいとは言えない、つまり、データを集めると「相関関係」はみられるが「因果関係」はなさそうです。
実は、このケースでは、3つ目の変数として年齢というものが隠れています。つまり「年収」と「年齢」、「血圧」と「年齢」の両ケースにおいて正の相関関係がみられた結果、「年収」と「血圧」にも正の相関関係がみられたという訳です。
このように、2つの変数間に相関関係があるからといって直ちに因果関係を導くことは誤りです。確かに、2つの変数の間に存在する何らかの「関係」を調べるために、2変数の相関関係を調べることは意義があります。もちろん、因果関係の存在を疑っている場合でも、とりあえず相関を調べることは役に立つでしょう。
しかし、繰り返しますが相関関係があることは、背後にある種の「関係」が存在している可能性を示唆しているに過ぎないのです。
さて、前置きが長くなりましたが、ここからは2つの変数を持つデータを回帰分析という手法を通じて分析してみましょう。
回帰分析
今、手元にn組のデータ

があるとしましょう。このとき、2つの変数の間にどれくらい相関があるかは相関係数-1≦r≦1を用いて説明できます。rが0に近い場合は、「相関なし」の状態です。
そして、rが-1に近いほど2つの変数は「負の相関関係がある」といい、rが1に近いほど「正の相関関係がある」といいます。(画像中のR^2は決定係数と呼ばれるもので、後半部分で説明します。)
 相関なし
相関なし 正の相関
正の相関
さて、与えられたデータ分布の最も良い近似直線(回帰直線)を求める方法をみてみましょう。
最小二乗法
データの全体の傾向を「最もよく表す」直線y=ax+bを求めてみます。この直線のことを回帰直線と言います。
「最もよく表す」という表現はやや曖昧なため、「直線と各データの垂直方向の距離の2乗和が最小となるような直線」とはっきり定義しておきましょう。(実際、距離の測り方は他にも幾つかありますが、ここでは最も一般的な方法を述べました。)

求める回帰直線とあるデータ(x_i,y_i), 1≦i≦nの垂直方向の距離をe_iとします。(e_iのことを残差変動と言います)

これを2乗したものの総和を次のように書きます。

e_iを見るとx,yにはそれぞれ実際のデータの値が代入されているのでe_iは(a,b)を変数にもつことに注意しましょう。E(a,b)を最小にする(a,b)を求める方法
![]()
を解くことですが、計算がやや複雑なので結果だけまとめます。
回帰直線の公式

決定係数
ここでは、先ほど求めた直線が「どれほどデータの分布をよく近似できているか」を知る方法を説明します。この近似の具合は決定係数と呼ばれ

と記述されます。値が1に近いほど回帰直線がデータの分布をうまく近似している状態です。
式をみてみると、分母が実際のデータy_iとその平均の差の2乗和(全変動と言います)、分子が回帰直線の式y=ax+bにデータの値x_iを代入したものとy_iの平均との差の2乗和(回帰変動と言います)になっています。
つまり、回帰直線の式y=ax+bにデータの値x_iを代入した数値がデータの値y_iに近いほど、分子と分母の値が近くなっていき、結果としてR^2が1に近づくという訳ですね。
注意点(発展)
上記では、決定係数R^2が1に近いほど回帰直線がデータの分布をうまく近似していると説明しましたが実は、これはやや不正確な説明です。例えば、回帰直線の傾きが0付近の場合を考えてみましょう。
回帰直線の傾きが0に近い場合、R^2の式の右辺の分子が0に近づいていきます。bの式を見たときに右辺の傾きaが0に近づくことを踏まえると明らかですね。
補足


右のように、データの分布と回帰直線がプロットされたグラフをみたときに、仮にデータが直線の近辺のみに分布していた(=回帰直線としてよく近似できている)としても、傾きが小さい場合は決定係数が0に近くなってしまいます。
そのため、決定係数の値だけをみて回帰直線の精度を判断しないようにしましょう。
回帰分析の実例
最後に実例として、回帰分析を使って株式が持つリスクの分析、特に個別株の市場インデックスに対するリスクの可視化、いわゆるベータの導出を行なってみましょう。(参考:ベータとは)
今回用いる株価データの期間は2021年とし、対象銘柄は市場インデックスとしてTOPIX、個別株としてトヨタ自動車を例とします。

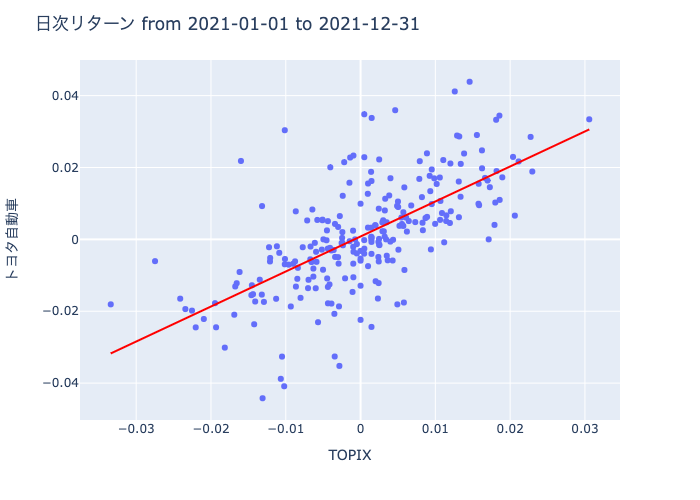
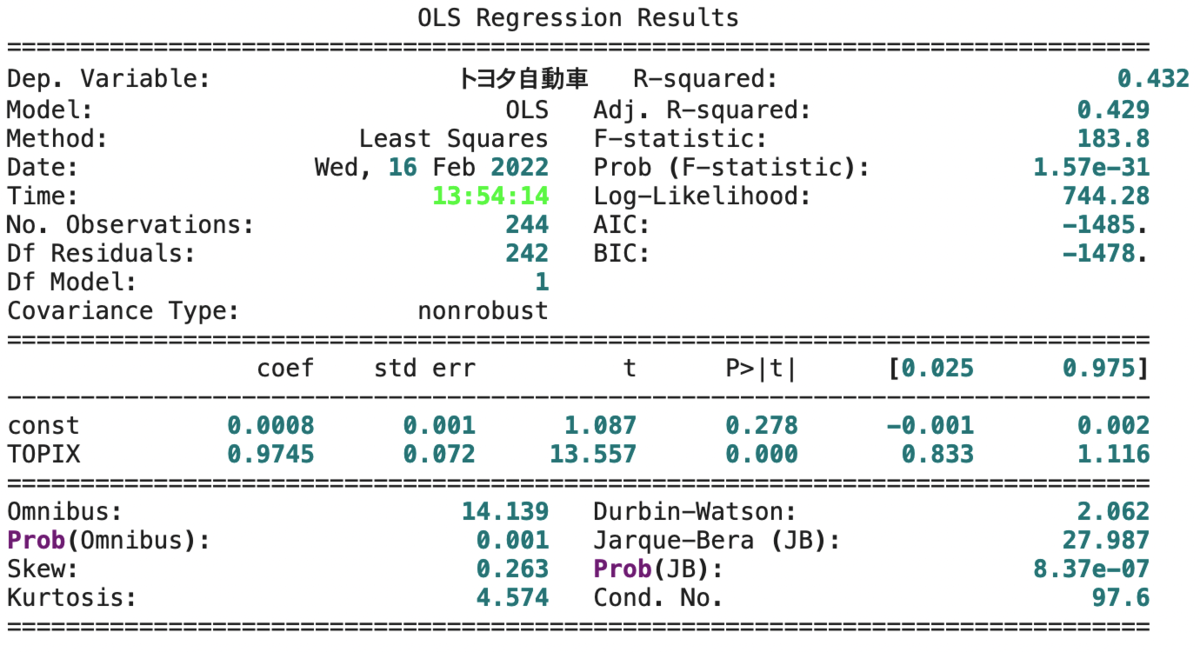
まとめの部分で示した数式に代入して計算することも出来ますが、回帰分析のライブラリーが用意されている場合はそれを使うと素早く計算を行えます。
上の表は、Python上のライブラリーを使って回帰分析を行った結果です。coefのところをみると回帰直線の切片の値が0.0008、傾きの値が0.9745。また、決定係数R^2の値が0.432とわかります。
その他にもt値やp値といった回帰分析のモデルを作る上で確認すべきポイントは幾つかありますので、興味のある方は調べてみてください。ひとまず、この株価データの例をもとに作った回帰直線の式は以下のようになります。
![]()
まとめ
回帰直線を求めることで、あるデータXに対応するデータYの最も良い推定値を求めることが可能になります。上で紹介した例で言えば、回帰直線を導出したことでTOPIXの収益率が〜%の時のトヨタの収益率を大まかに予想、分析することが出来ました。
もちろん、回帰直線から得られる推定値は過去のデータや一部のサンプルから計算した推定値ですので、その精度や信頼性については紹介した決定係数やt値、p値といった統計量に基づいて判断することになります。
また今回は「単回帰分析」を取り扱いましたが、その発展として「重回帰分析」も存在します。重回帰分析では複数のファクターを用いた回帰分析を行うことで単回帰分析のときと比べ、より精緻な分析を行える場合があります。単回帰分析の場合と比べ少し複雑ですが、基本的なアイディアは同じになります。
以上のように、今回は回帰分析の初歩である単回帰分析を紹介しました。あるデータが持つ2つの変数の関係を調べたいときに最も手軽な方法は散布図を表示したり相関係数を計算することです。しかし、回帰直線を調べることでもう一歩踏み込んだ分析を行うことが出来ます。
