
こんにちは!nakamura(@naka957)です。今回はPyCaretとMLflowを用いたAutoMLと実験記録を連携した活用方法をご紹介します。
今回は様々な機械学習アルゴリズムの比較・モデル実装に加えて、行った実験記録の管理を簡単に行う方法をご紹介します。実施事項がたくさんありますが、PyCaretとMLflowの活用で少ないコード行数で簡単に実施できます。
PyCaretは機械学習モデルの実装を簡単に行えるOSSですが、PyCaretからMLflowを呼び出すこともでき、実験記録の管理も同時に行えます。
【PyCaret】
■ AutoMLライブラリPyCaretを使ってみた〜モデル実装から予測まで〜
■【続き】 AutoMLライブラリPyCaretを使ってみた 〜結果の描画〜
【MLflow】
■ MLflowの使い方 - 機械学習初心者にもできる実験記録の管理 -
■ MLflowの環境構築を解説〜Docker Composeを用いてデータ分析環境と実験記録の保存場所を分けて構築〜
PyCaretとは
PyCaretは人気が高いAutoML(Auto Machine Learning)のPythonライブラリの1つです。オープンソースのため誰でも無料で利用できます。
大きな特徴として、少ないコード行数で、データの前処理から機械学習アルゴリズムの比較・パラメーター調整・実装までを行うことできます。
モデル実装以外にも、機械学習を行う上で便利なツールを持つ高機能なライブラリです。例えば、探索的データ分析(EDA)を簡単に行えるAutoVizや、Web APIを作成するFastAPI、ドリフト検知を行うEvidentlyを含んでいます。また、本記事で紹介もする、実験記録を管理するMLflowも含んでいます。
AutoViz, FastAPI, Evidentlyの紹介記事も発信してますので、参考にしてみてください。
【AutoViz:探索的データ分析】
■PyCaretからAutoVizを使用して探索的データ分析(EDA)を簡単に行ってみる
【FastAPI:Web API】
■お手軽で高速なFastAPIでCloudRunに推論APIを公開するまで
【Evidently:ドリフト検知】
■データドリフトを簡単検知!PythonライブラリEvidentlyを使ってみた
MLflowとは
MLflowはコードの実行ごとに実験記録を作成してくれる便利なライブラリで、OSSのため、誰でも無料で使用することができます。実験記録の管理は、機械学習プロジェクトの効率的な推進と、結果の再現性の確保に欠かせない要素です。
また、MLflowは実験管理だけでなく、機械学習プロジェクト全体で使用できる機能を提供しています。主要な機能(コンポーネント)は次の4つで構成されています。
- MLflow Tracking: 実験記録の管理
- MLflow Projects: 再利用可能な形でコードをパッケージ化
- MLflow Models: 本番環境へ機械学習モデルを提供するための機能
- Model Registry: 運用管理のための、モデル登録・API・UIの提供
データ分析や機械学習モデル作成時ではMLflow Trackingの活用が特に盛んです。例えば、機械学習モデルのハイパーパラメータの水準とその評価指標の実験記録の管理が挙げられます。
他の大きな特徴として、実験記録をUIで可視化し、確認できる点があります。UIで確認できることで、開発者が実験記録を簡単に参照できるだけでなく、他メンバーと共有することもできます。
環境準備:ライブラリのインストール
以降で紹介するコード例は、Jupyter Notebookでの実行を想定しています。また、本記事のサンプルコードでは、PyCaretとMLflowのバージョンは次で動作確認をしています。
pycaret==2.3.10 mlflow==1.26.1
インストールが未実施の人は、事前にインストールが必要です。
# まとめてPyCaretとMLflowをインストール $ pip install pycaret[full] # 個別にインストール $ pip install pycaret $ pip install mlflow # バージョンを指定する場合 $ pip install pycaret==2.3.10 $ pip install mlflow==1.26.1
PyCaretによる回帰分析の例
PyCaretを用いた回帰分析モデルの実装プロセスは、次の手順で行います。
- ライブラリとデータセットの読み込み
- 実験環境の設定
- 機械学習アルゴリズムの比較
- モデルの定義
- ハイパーパラメーターの調整
ライブラリとデータセットの読み込み
使用するライブラリを事前に読み込んでおきます。
from pycaret.datasets import get_data from pycaret.regression import setup from pycaret.regression import compare_models from pycaret.regression import create_model from pycaret.regression import tune_model
また、使用するデータセットも読み込みます。PyCaretは様々なデータセットを用意しています。今回は、ダイヤモンド価格予測のデータセットを使用します。
datasetモジュールのget_data関数にデータセット名の’diamond’を渡すと、pandasのDataFrame型で受け取ることができます。
df = get_data('diamond')
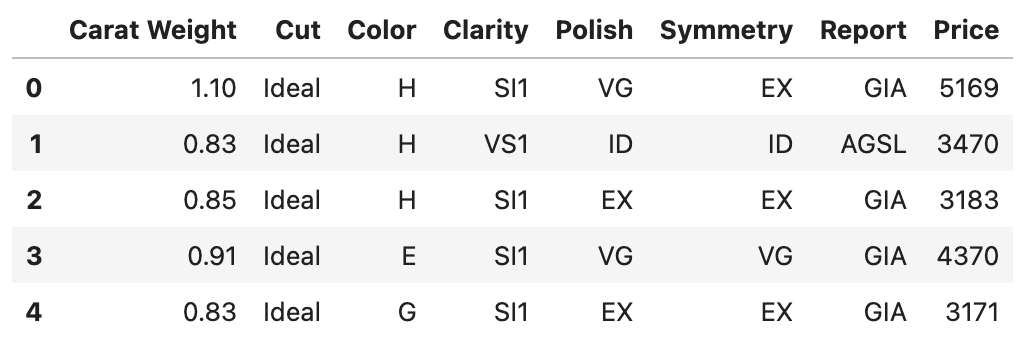
データセットの各列の説明は次の通りです。
- Carat Weight: カラット単位の重量(1 carat = 0.2 g)
- Cut: 5段階のカット性評価
- Color: 6段階の色性評価
- Clarity: 7段階の透明度評価
- Polish: 4段階の磨き度評価
- Symmetry: 4段階の対称性評価
- Report: 品質等級評価機関による2段階評価(“AGSL” or “GIA”)
- Price: USD単位での価格
実験環境の設定
PyCaretでは実験環境の設定を最初に行う必要があります。主な目的は次の通りです。
- 目的変数の指定
- 入力変数の型推定を行い、必要に応じて明示的に変数型を指定
- 乱数シード値の指定し、再現性の確保
今回は目的変数に変数Priceを指定し、再現性確保のために乱数シード値に0を渡して実行しましょう。ただし、MLflowで実験記録を保存するため、次の2つの引数も指定します。
- log_experiment: 実験記録を保存
- expariment_name: 実験記録名
s = setup( data=df, # データセット target='Price', # 目的変数名 log_experiment=True, # 実験記録を保存 experiment_name='diamond', # 実験記録の名前 categorical_features=[], # カテゴリカル変数列を指定 numeric_features=[], # 数値変数列を指定 session_id=0, # 再現性確保のため、シード値を固定 silent=True, # 結果確認の省略 )
なお、PyCaretは自動で入力変数の型を推定してくれますが、推定結果と異なる指定をする場合は、引数categorical_featuresもしくは引数numeric_featuresへ明示的に指定してください。
機械学習アルゴリズムの比較
PyCaretは機械学習アルゴリズムを一度に比較する機能があります。compare_model関数で比較ができ、各引数の詳細は公式ドキュメントを参照頂きたいのですが、単純な比較のみであれば次の3つの引数の指定で十分です。
- sort: 評価指標の指定(指定の指標でモデル候補がソートされる)
- fold: クロスバリデーションのフォールド数
- exclude: 比較で除外するアルゴリズム名
次のコードのみで様々なアルゴリズムを一度に比較できます。今回は実行時間を短縮するため、引数のexclude=['et', 'rf', 'lr', 'knn', 'ada']で指定したアルゴリズムの比較を省略しています。なお、各モデルの略称は公式ドキュメントで確認できます。
compare_models( sort='RMSE', # 指定した評価指標でソート, default = 'R2' fold=4, # クロスバリデーションのfold数 exclude=['et', 'rf', 'lr', 'knn', 'ada'], # 比較から除外するアルゴリズム名を指定 )
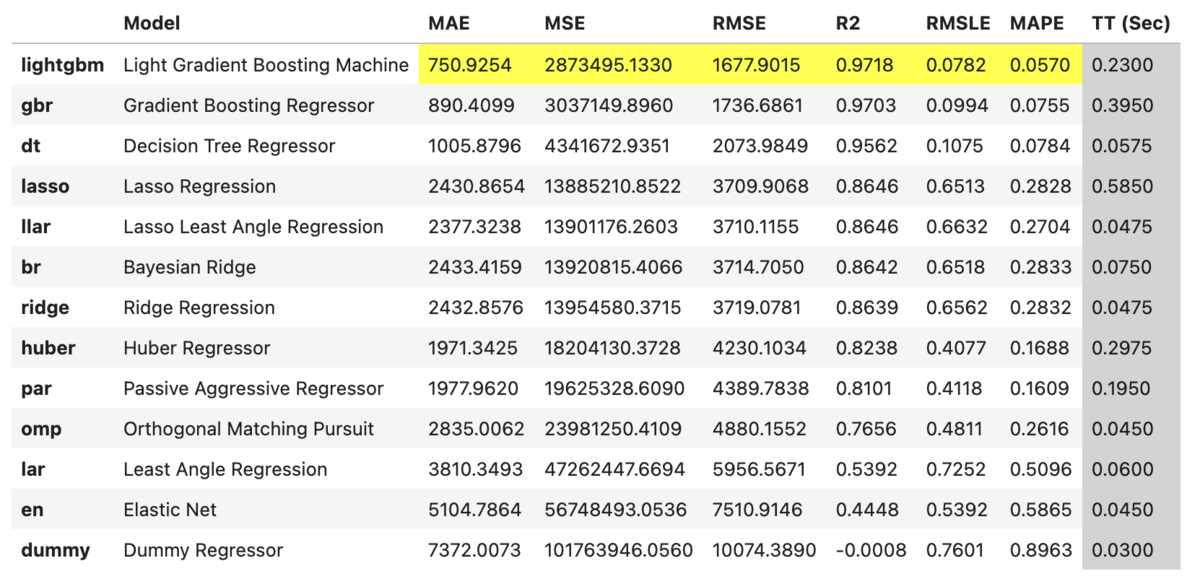
今回の比較では、lightgbmで最も精度が高い結果となりました。そこで以降では、lightgbmモデルの定義とハイパーパラメーター調整を行います。
モデルの定義
モデル定義はcreate_model関数で行えます。
最初の引数にアルゴリズム名を指定します。今回は、’lightgbm’を渡しましょう。また、クロスバリデーションの実施有無と、フォールド数も指定します。
model = create_model( 'lightgbm', # アルゴリズム名を指定 cross_validation=True, # クロスバリデーションの実施有無 fold=4, # クロスバリデーションのfold数 )
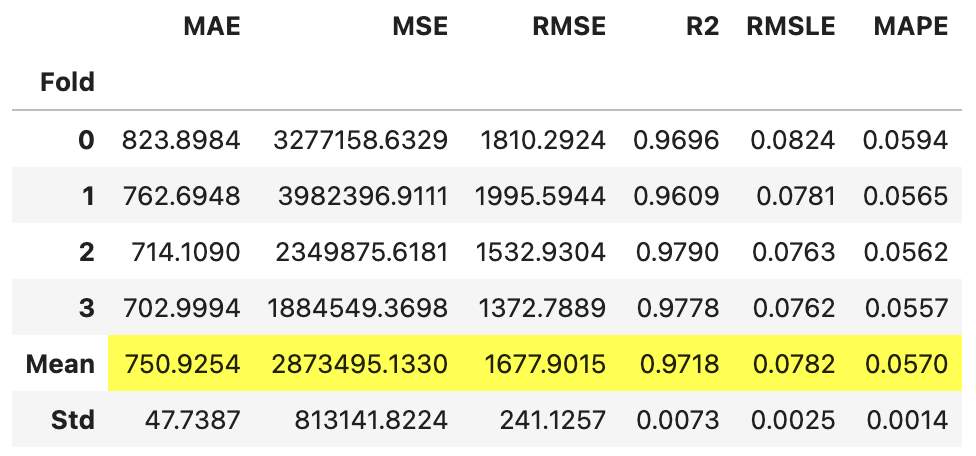
モデル定義は以上です。
ハイパーパラメーターの調整
定義したモデルのハイパーパラメーターを調整しましょう。tune_model関数でグリッドサーチ法を用いた調整を行えます。引数には、定義したモデルのインスタンスと評価指標名、クロスバリデーションのフォールド数を指定します。
tuned_model = tune_model( model, # 定義したモデルを渡す optimize='RMSE', # 評価指標 fold=4, # クロスバリデーションのfold数 )
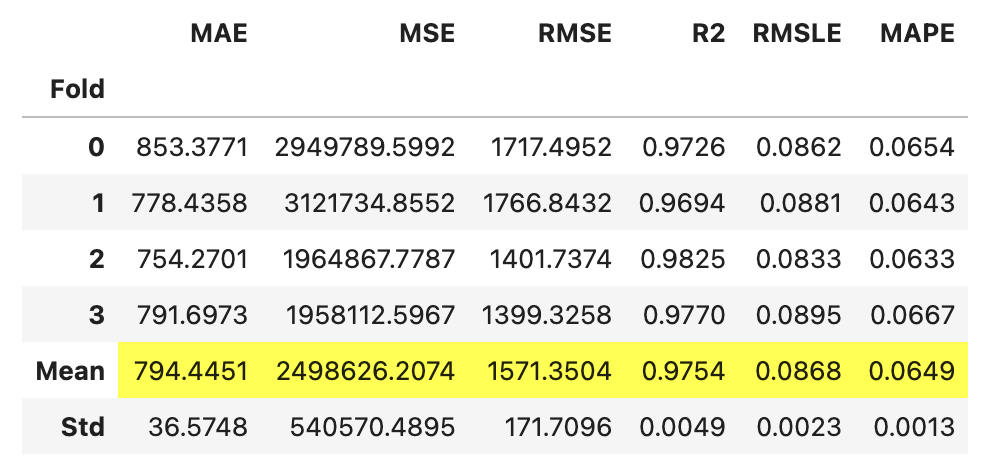
指定した評価指標のRMSEで精度向上が確認できています。
MLflowによる実験記録の確認
これまで、PyCaretで機械学習アルゴリズムの比較、モデル定義、ハイパーパラメーター調整を行いました。本節では、一連の実験記録をMLflowのUIで確認していきます。
MLflowを用いると、実行した実験結果を遡って確認が可能になります。そのため、今回試したlightgbm以外のモデルで検討した場合も、簡単に参照して、比較することができます。
また、通常はMLflowで記録するためにコード追記が必要ですが、PyCaretからMLflowを呼び出して使用すればコード追記が不要です。「実験環境の設定」節で行った、setup関数へ引数”log_experiment=True”を渡すのみで、自動で実験記録が行われます。
そのため、本節で新たにコードを記述する必要はありません。MLflow UIを起動するのみで、実験記録の確認が行えます。
MLflow UIの起動
MLflowのUIはコマンドで起動します。次のコマンドを、Windowsの場合はコマンドプロンプト上で、Macの場合はターミナル上で実行してください。
$ mlflow ui # port番号を指定する場合 ex. port番号5001の場合 $ mlflow ui --port 5001
または、Jupyter Notebookのセル実行で起動する場合は次の通りです。
!mlflow ui
MLflowのUIはWebブラウザ上からアクセスできます。port番号を指定しない場合、デフォルトで5000が割り当てられるため、”http://localhost:5000”でアクセスできます。また、port番号を指定した場合は、指定したport番号でURLにアクセスしてください。
問題なく起動すれば、次のようなUIが立ち上がります。
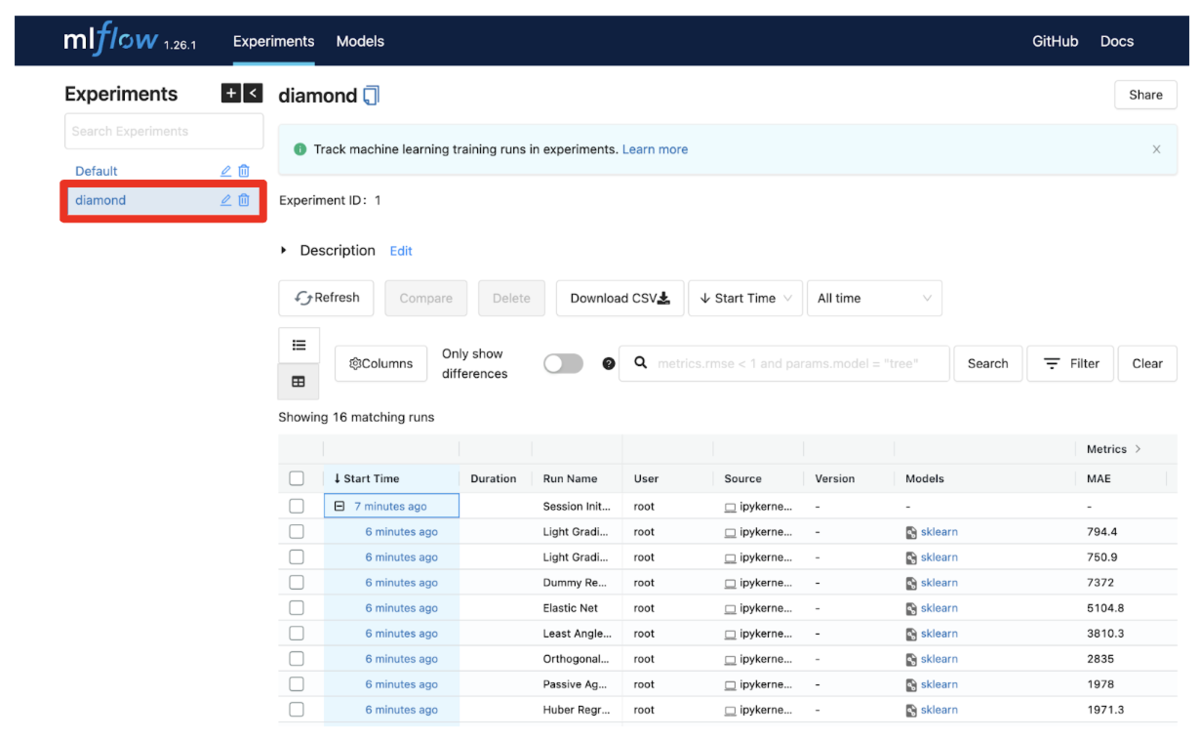
今回は、「実験環境の設定」節で行った、setup関数の引数experiment_name = 'diamond'と指定したため、上図の赤枠のdiamond箇所が該当箇所です。
実験記録の確認1:機械学習アルゴリズムの比較
機械学習アルゴリズム比較時の実験記録は、下図の赤枠が該当箇所となります。”Run Name”の列に各アルゴリズム名が割り当てられています。また、評価指標については、”Metrics”箇所をクリックすると表示が隠れている指標も表示されます。また、特定の評価指標で結果をソートして確認もでき、例えば、MAE列をクリックすれば実行されます。
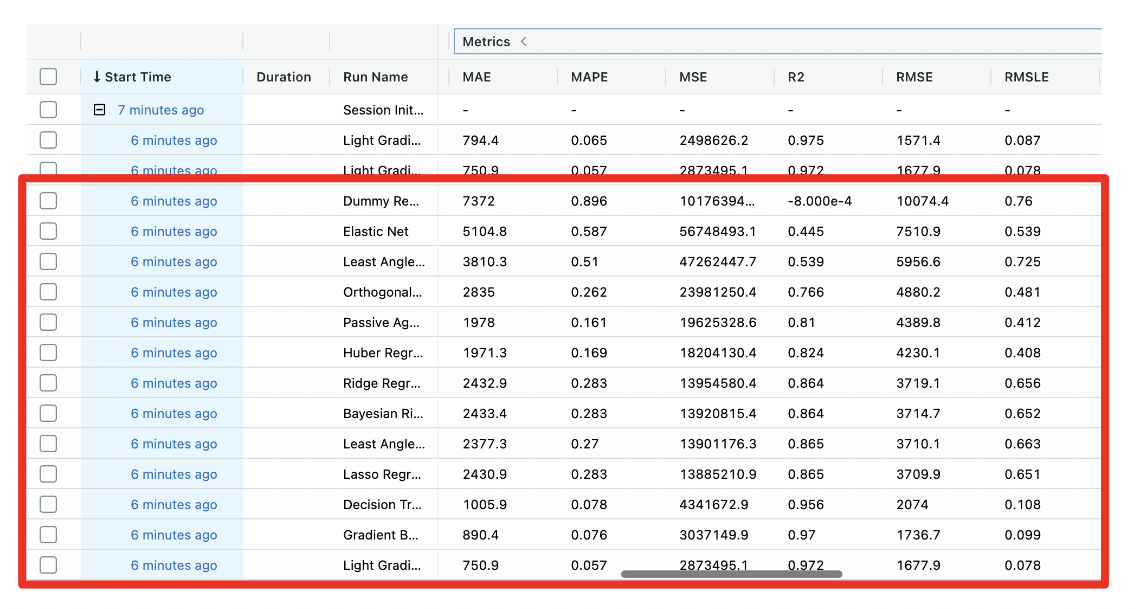
このように、PyCaretで一度アルゴリズム比較を実行すれば、MLflowで実行結果が保存され、実行後でも各アルゴリズムと評価指標の結果を確認ができます。
実験記録の確認2:定義モデル(lightgbm)のハイパーパラメーター調整結果
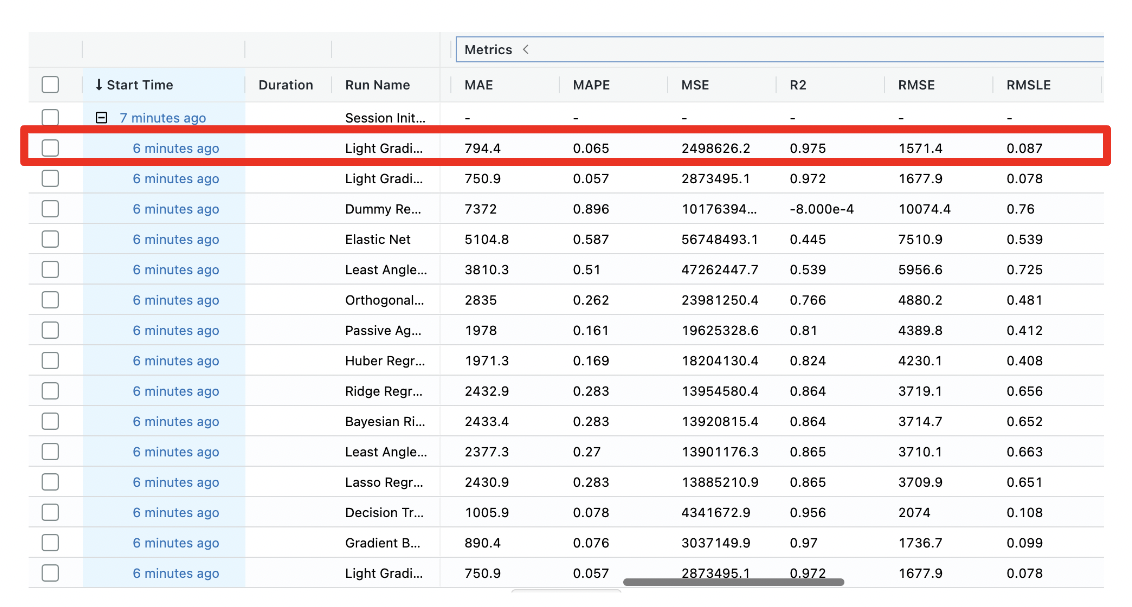
モデル定義したlightgbmのハイパーパラメータ調整後の結果は、下図の赤枠になります。結果の詳細情報は、”Start Time”列の対象行をクリックすれば確認できます。
下図がハイパーパラメータ調整後の詳細結果です。下図の赤枠箇所は、調整後のハイパーパラメータ、各評価指標、学習済みモデルの結果です。詳細はクリックすると確認ができます。
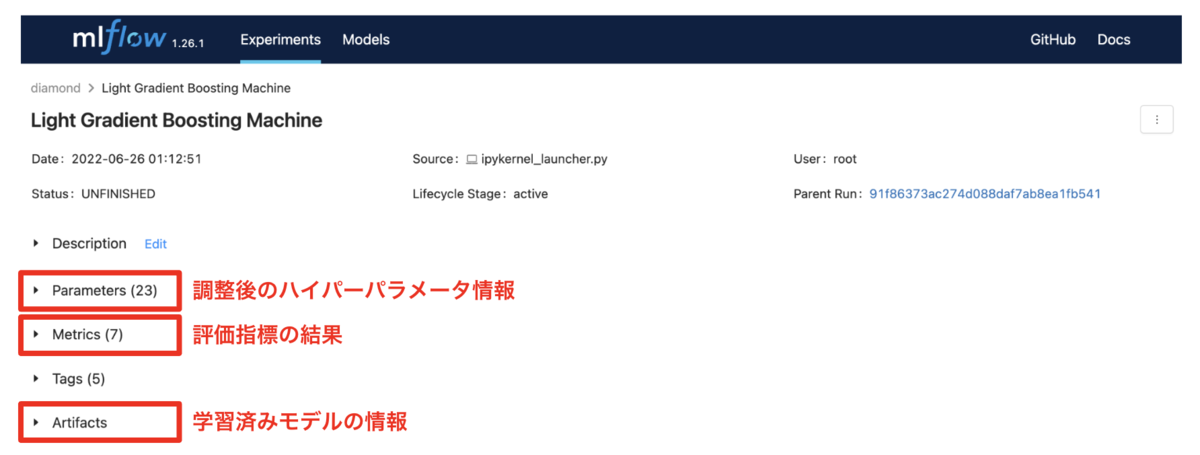
調整後のハイパーパラメータ情報

評価指標の結果

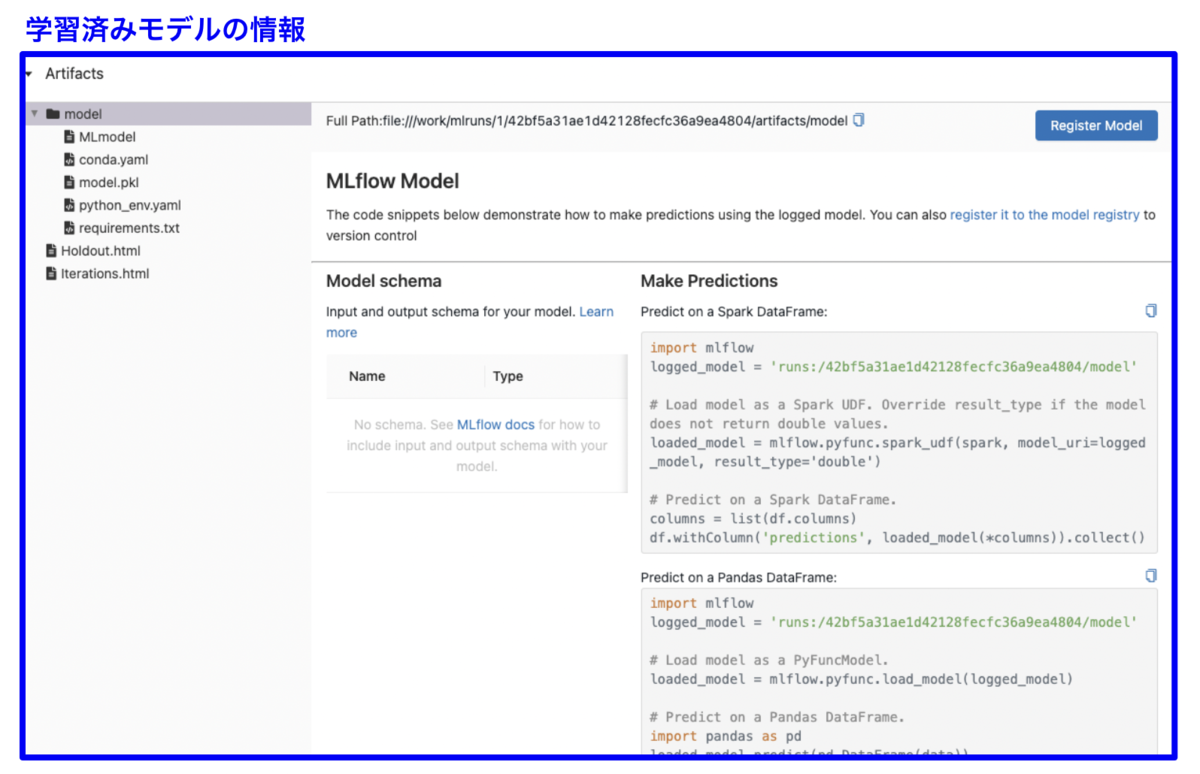
学習済みモデルの情報
MLflowでは学習済みモデルの情報も保存されます。実装用のサンプルコードも下図の通りに掲載され、本番環境で使用する場合でも非常に便利です。
まとめ
ここまで、PyCaretを用いた機械学習アルゴリズム比較、モデル定義、ハイパーパラメータ調整、そして、MLflowによる実験記録の管理方法を紹介してきました。
PyCaretとMLflowを活用することで、AutoMLで効率良く機械学習モデルを実装し、その実験記録の参照と再現性の確保を簡単にできるようになります。
機械学習プロジェクトを進める上で、とても便利なツールであることを実感頂ければ嬉しい限りです。是非、試してみてください。
参考
