
こんにちは!nakamura(@naka957)です。今回はDocker Composeを用いたMLflowの環境構築方法をご説明します。
前回の記事 ではMLflowの初心者向けチュートリアルをご紹介しました。MLflowを用いることで、実験記録の管理を簡単に行えることを解説しています。
MLflowの使い方 - 機械学習初心者にもできる実験記録の管理 -
今回はMLflowの環境構築方法をご紹介します。特に実務を想定し、データ分析環境とMLflow環境を分けて構築します。これにより、異なるプロジェクト間でMLflow環境を共有することが可能になり、毎回のMLflow環境構築と管理の手間を省くことができます。加えて、MLflow環境を外部からアクセス可能にします。それにより、他メンバーもMLflow UIへアクセス可能となり、実験記録の参照と共有をできるようにします。
では、早速始めていきます。
MLflowとは
MLflowはコードの実行ごとに実験記録を作成してくれる便利なライブラリで、OSSのため、誰でも無料で使用することができます。例えば、機械学習モデルのハイパーパラメータ調整において、必要な実験記録を自動保存することができます。
また、前回の記事 では実験管理の機能を紹介しましたが、それ以外にも、機械学習プロジェクト全体で使用できる機能を提供しています。大きくは次の4つの主要な機能で構成されています。
- MLflow Tracking: 実験記録の管理
- MLflow Projects: 再利用可能な形でコードをパッケージ化
- MLflow Models: 本番環境へ機械学習モデルを提供するための機能
- Model Registry: 運用管理のための、モデル登録・API・UIの提供
開発時ではMLflow Trackingの活用が特に盛んです。例えば、機械学習モデルのハイパーパラメータの水準とその評価指標の実験記録の管理が挙げられます。
また、MLflowの他の大きな特徴として、実験記録をUIで可視化して確認できる点があります。そのため、開発者が簡単に実験記録を参照できるだけでなく、他メンバーと共有することもできます。
構築環境の全体像
構築環境は、各々の機能(データ分析・MLflowサーバー・外部公開)をそれぞれのDockerコンテナに分けて構成します。そして、複数のコンテナを同時に実行し、全体の機能を構築します。
複数のDockerコンテナを定義・実行するための便利なツールにDocker Composeがあります。Docker Composeを用いることで、Dockerコンテナそれぞれの定義とDockerイメージの作成、DockerイメージからDockerコンテナを作成し、起動するまでを簡単に行うことができます。
主要な機能を次の3つのコンテナに分け、全体をDocker Composeで構築します。
- データ分析: Jupyter Notebook
- MLflowサーバー: 実験記録の取得と管理
- ngrok: MLflow UIを外部からアクセス可能にするサービス
全体像は下図となります。

上図の構成に基づく、フォルダ構成は次の通りです。
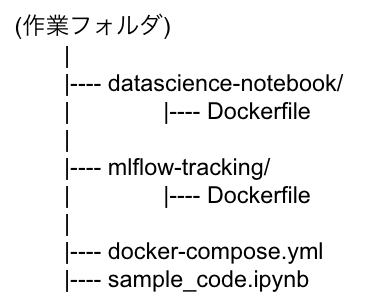
Docker Composeの全体構成はdocker-compose.ymlで定義します。また、各コンテナの定義はDockerfileで定義し、子フォルダ(datascience-notebook, mlflow-tracking)に分けて管理します。ただし、ngrokコンテナはDocker Hubの公開Dockerイメージを変更なしで使用するため、Dockerfileを用いずにdocker-compose.yml内で直接定義します
以上で、全体構成の説明は完了です。以降では、各々のDockerコンテナをDockerfileで定義し、Docker Composeでの構成を定義していきます。
データ分析環境の構築
プロジェクトの主コードを実行する環境になります。例えば、機械学習モデルの構築やデータ分析の実行環境です。今回は有名なJupyter Notebookの環境を構築します。Jupyter Notebookはコードを対話的に作成・実行できるノートブック形式の実行環境です。Pythonを含めた様々なプログラミング言語に対応しており、OSSのため誰でも無料で使用することができます。
Jupyter Notebook用のコンテナ
分析環境の構築はJupyterプロジェクトがDocker Hubで公開しているdatascience-notebookのDockerイメージを使用します。datascience-notebookには、Pythonだけでなく、RやJuliaの環境も含まれており、データ分析者に必要な環境が一通り含まれている便利なDockerイメージです。
Dockerfile
データ分析用のコンテナに必要な内容をDockerfile内に指定します。Dockerfileは子フォルダのdatascience-notebook内に作成してください。1行目で使用するイメージを指定した後は、MLflowを含めた必要なライブラリのインストールを指定します。ただし、データ分析に必要な基本ライブラリはdatascience-notebookのDockerイメージに含まれており、データ分析に必須なnumpy, pandas, scikit-learnなどのインストールは必要ありません。
./datascience-notebook/Dockerfile
FROM jupyter/datascience-notebook RUN pip install --upgrade pip && \ pip install mlflow
docker-compose.yml
親フォルダのdocker-compose.ymlにデータ分析用のコンテナ構築に関する記述を行います。特に重要となる指定箇所の説明は次の通りになります。
- サービス名の指定(構築環境の名称に相当)
- “notebook”
- DockerfileのフォルダPATH
- context: ./datascience-notebook
- ポート指定(ホスト側:コンテナ側)
- - "8888:8888"
./docker-compose.yml
version: '3'
services:
notebook:
build:
context: ./datascience-notebook
dockerfile: Dockerfile
working_dir: '/work'
ports:
- "8888:8888"
volumes:
- ./:/work/
command: jupyter notebook --port 8888 --ip=0.0.0.0 --notebook-dir='/work' --no-browser --allowroot --NotebookApp.token=''
restart: always
環境の構築が問題なく実行されるかは、次のコマンドで確認できます。Docker Composeを用いたDockerコンテナ構築の標準的な手順です。
# imageの作成 $ docker-compose build # コンテナの起動 $ docker-compose up
上記コマンドで無事にコンテナが立ち上がれば、Webブラウザ上から”http://localhost:8888”でJupyter Notebook環境へアクセスできます。
MLflow環境の構築
先ほど構築したデータ分析環境とは別コンテナの形で、MLflow環境を構築します。別コンテナとすることで、複数のプロジェクトでMLflow環境のコンテナを共有して使用が可能になります。
MLflow用のコンテナ
Dockerコンテナに必要な機能は、今回はmlflowのみです。そのため、DockerコンテナのベースとなるDockerイメージはPythonの公式イメージを使用することで、mlflowライブラリを簡単に導入できます。
Dockerfile
必要な環境をDockerfile内に指定します。Dockerfileは子フォルダのmlflow-tracking内に作成してください。
./mlflow-tracking/Dockerfile
FROM python:3.8 RUN pip install --upgrade pip && \ pip install mlflow RUN mkdir ./mlflow # 実験記録の保存フォルダ
docker-compose.yml
親フォルダのdocker-compose.ymlにMLflowの環境構築を追加で記述します。データ分析環境部からの追記箇所は「# 以下、追記箇所」で示しています。また、特に重要となる指定箇所の説明は次の通りになります。
- サービス名の指定(構築環境の名称に相当)
- “mlflow”
- DockerfileのフォルダPATH
- context: ./mlflow-tracking
- ポート指定(ホスト側:コンテナ側)
- - "5000:5000"
./docker-compose.yml
version: '3' services: notebook: build: context: ./datascience-notebook dockerfile: Dockerfile working_dir: '/work' ports: - "8888:8888" volumes: - ./:/work/ # 追記箇所(4行のみ) depends_on: - mlflow environment: MLFLOW_TRACKING_URI: 'http://mlflow:5000' command: jupyter notebook --port 8888 --ip=0.0.0.0 --notebook-dir='/work' --no-browser --allow-root --NotebookApp.token='' restart: always # 追記箇所 mlflow: build: context: ./mlflow-tracking dockerfile: Dockerfile expose: - "5000" ports: - "5000:5000" command: mlflow server --backend-store-uri /work/mlruns --default-artifact-root /work/mlruns --host 0.0.0.0 --port 5000 restart: always
また、以下の4行をデータ分析用コンテナ(サービス名”notebook”)箇所に追加している点に注意してください。Jupyter Notebook(”http://localhost:8888”)の実験結果の保存先をMLflow環境コンテナ(“http://mlflow:5000”)へ指定しています。保存先の指定は、環境変数MLFLOW_TRACKING_URIで行えます。
depends_on: - mlflow environment: MLFLOW_TRACKING_URI: 'http://mlflow:5000'
環境構築の確認は、前回と同様に次のコマンドを実行してください。
# imageの構築 $ docker-compose build # コンテナの起動 $ docker-compose up
無事にコンテナが立ち上がれば、Webブラウザ上から”http://localhost:5000”でMLflowのUIへアクセスできます。
localhost環境での実行確認
構築したデータ分析(Jupyter Notebook)とMLflowの環境の動作確認を行います。
各環境へのアクセスはWebブラウザ上から、Jupyter Notebookへは”http://localhost:8888”で、MLflowへは”http://localhost:5000”でアクセスできます。読者の方でポート番号を変更した場合は、変更番号へ読み替えてアクセスしてください。
次に、サンプルコードを実行し、実験記録がMLflowで自動保存されることを確認しましょう。サンプルコードは前回の記事の内容を使用します。
■前回の記事:MLflowの使い方 - 機械学習初心者にもできる実験記録の管理
実施内容は、カリフォルニア住宅価格のデータセットを用いて回帰モデル(ランダムフォレスト)を作成し、ハイパーパラメータの調整と精度指標の実験結果をMLflowで自動保存することです。
では、以下のコードを”http://localhost:8888”上のJupyter Notebookで実行してください。わかりやすさのため、コード内での機能ごとで各セルに分けて記載しています。
ライブラリの読み込み
from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error as MSE from sklearn.metrics import r2_score from matplotlib import pyplot as plt import seaborn as sns sns.set() import mlflow import mlflow.sklearn
データセットの準備
# データセットの読み込み dataset = fetch_california_housing(as_frame=True) df = dataset['frame'] # データセットを説明変数と目的変数に分ける target_col = 'MedHouseVal' X, y = df.drop(columns=[target_col]), df[target_col] # データセットを訓練と検証データに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
試行関数の定義
実験1回分(モデル定義、訓練、検証データの予測、評価指標の算出)の実行関数
def train(n_estimators, max_depth): # モデルの定義 model = RandomForestRegressor( n_estimators = n_estimators, max_depth = max_depth, criterion = 'squared_error', # 'mse' random_state = 0, ) # 訓練 model.fit(X_train, y_train) # 検証データの予測 y_pred = model.predict(X_test) # MSE誤差, R2値の算出 mse = MSE(y_pred, y_test) R2 = r2_score(y_pred, y_test) return model, mse, R2
複数水準のパラメータで実験を実行し、その条件と結果を記録
# 管理IDを発行(コードの実行に対して) with mlflow.start_run(): # ハイパーパラメータの試行水準 cand_n_estimators = [10, 100, 1000] cand_max_depth = [1, 5, 10] trial = 0 for n_estimators in cand_n_estimators: for max_depth in cand_max_depth: # 管理IDを発行(各パラメータ水準に対して) with mlflow.start_run(nested=True): trial += 1 model, mse, R2 = train(n_estimators, max_depth) # 小数点以下3桁まで出力 print(f"trial {trial}: n_estimators={n_estimators}, max_depth={max_depth}, MSE = {mse:.3}, R2 = {R2:.3}") # 追加箇所 # ハイパーパラメータ, 評価指標, 学習済みモデルをMLflowへ保存 mlflow.log_param("n_estimators", n_estimators) mlflow.log_param("max_depth", max_depth) mlflow.log_metric("mse", mse) mlflow.log_metric("R2", R2) mlflow.sklearn.log_model(model, "model")
実行結果をMLflow UI(”http://localhost:5000”)で確認してみましょう。問題なく実行が完了すれば、下図のように、実験結果が記録されていることを確認できます。

MLflow UIへ外部からアクセスする
ここまで構築した環境はlocalhostでのアクセスに限定されています。言い換えれば、開発者本人のPC以外からはアクセスできません。一方で、実験記録を他人と共有したい場合も多いと思います。そこで、今回は簡単に外部からのアクセスを可能にするngrokを用いた方法をご紹介します。
ngrokとは
クラウドやプライベートネットワークを外部に公開する機能を提供するサービスです。非常に多機能なサービスですが、今回はlocalhostを外部へ公開するために使用します。使用にはユーザー登録が必要ですが、2022年6月現在、無料登録ユーザーに対しても外部へ公開用のURLを1つのみ割り当ててくれます。そのため、割り当てられたURLを用いることで、localhostに立ち上げたMLflow UIを外部へ公開することができます。
ngrokの認証情報の取得
外部アクセスを可能にする手順は以下の3ステップで行えます。
- ngrokサイトのログイン後ページの認証トークンを取得
- docker-compose.ymlにngrokコンテナの追加と、取得した認証トークンを指定
- ngrokサイトのログイン後ページの外部公開URLを確認し、アクセス
ここでは、上記の項目1と3の情報を先に取得しておきます。
ngrokの公式サイトからログインしてください。ユーザー登録がまだの人は事前に登録が必要です。ログイン後は次の手順でngrok側の認証に必要な情報(認証用トークンと外部公開用URL)を取得してください。
1. 認証用のトークン(Authtoken)を取得

2. 外部公開用のURLを確認


以上で、ngrok側の認証で必要な情報は取得完了です。取得した情報を用いて、docker-compose.yml内にngrokの設定をします。
docker-compose.yml
親フォルダのdocker-compose.ymlにngrok用のコンテナを追加し、ngrokログインページから取得した認証情報を指定します。これにより、MLflowコンテナで立ち上げたMLflow UIをngrokコンテナを通して外部公開することが可能となります。使用するDockerイメージは、Docker Hubで公開されている中でよく使用されているwernight/ngrokを使用します。
ngrokコンテナの追記箇所を「# 以下、追記箇所」で示しています。また、特に重要な指定箇所の説明は次の通りになります。
- サービス名の指定(構築環境の名称に相当)
- ngrok
- ポート指定(ホスト側:コンテナ側)
- - 4040:4040
- MLflow環境のサービス名”mlflow”とそのポート番号を指定し、公開用URLと接続
- NGROK_PORT: mlflow:5000
- 認証用のトークン(Authtoken)の指定
- NGROK_AUTH: (認証用トークン)
./docker-compose.yml
version: '3' services: notebook: build: context: ./datascience-notebook dockerfile: Dockerfile working_dir: '/work' ports: - "8888:8888" volumes: - ./:/work/ depends_on: - mlflow environment: MLFLOW_TRACKING_URI: 'http://mlflow:5000' command: jupyter notebook --port 8888 --ip=0.0.0.0 --notebook-dir='/work' --no-browser --allow-root --NotebookApp.token='' restart: always mlflow: build: context: ./mlflow-tracking dockerfile: Dockerfile expose: - "5000" ports: - "5000:5000" command: mlflow server --backend-store-uri /work/mlruns --default-artifact-root /work/mlruns --host 0.0.0.0 --port 5000 restart: always # 以下、追記箇所 ngrok: image: wernight/ngrok:latest ports: - 4040:4040 environment: NGROK_PROTOCOL: http NGROK_PORT: mlflow:5000 NGROK_AUTH: (認証用トークン) depends_on: - mlflow
以上で、docker-compose.ymlの設定は完了です。次のDocker Composeコマンドでイメージを構築し、コンテナを起動します。
# imageの作成 $ docker-compose build # コンテナの起動 $ docker-compose up
外部からのアクセス確認
最後にlocalhostに立ち上げたMLflow UIへ外部からアクセスできるか確認しましょう。ngrokの認証が問題なく通っていればアクセスできるはずです。ngrokサイトのログイン後ページの外部公開用URLからアクセスしてみてください。ローカルホスト環境の”http://localhost:5000”が、外部公開用URLと紐付けられており、MLflow UIを外部からでも参照することが可能となっています。
ただし、セキュリティの観点から、使用しない時はコンテナを停止させ、外部からアクセスできなくすることを強くお勧めします。
まとめ
本記事では、MLflowの環境構築の方法をご紹介しました。
Docker Composeを用いて、コンテナ環境をデータ分析とMLflow環境に分けて構築しました。これにより、複数のプロジェクトでMLflow環境を共有することができ、毎回の環境構築の手間を省くことができます。
また、ngrokを用いたMLflow UIの外部公開方法もご紹介しました。ngrokを用いることで非常に簡単に公開することができることを体感頂けたと思います。
MLflowは本記事で紹介した機能以外にも、機械学習プロジェクトの管理を行うための強力な機能を提供しています。一方で、環境構築でつまずく人も多いと思います。本記事が読者の方に少しでもお役に立てば幸いです。
参考文献
- https://mlflow.org/
- https://mlflow.org/docs/latest/tracking.html
- https://docs.docker.com/compose/
- https://jupyter.org/
- https://hub.docker.com/r/jupyter/datascience-notebook
- https://hub.docker.com/_/python
- https://ngrok.com/
- https://hub.docker.com/r/wernight/ngrok/
