
こんにちは。今回は、データ基盤の構築の一部を実際に体験してみたいと思います。
データ基盤を作成するにあたり、まずは、社内に眠る様々なデータを集めてくる必要があります。
前回の記事では、その機能を「収集」と紹介していました。
データ基盤とは何か? 収集・変換・統制の3つの構成要素に分けて解説
本記事では、データ基盤の収集機能をOSSで構築し、実際に体験してみたいと思います。
これからデータ基盤を開発していく方に、少しでもお役に立てたら幸いです。
- データ連携に必要なELTについて
- データ抽出機能に特化したAirbyteについて
- ELに必要な環境のセットアップ
- Airbyteのセットアップ
- PostgreSQLのセットアップ
- BigQuery のデータセットの作成
- Airbyte上での設定
- AirbtyeによるELの実行
- まとめ
データ連携に必要なELTについて
収集機能を構築していくあたり、大事な考え方が1つあります。
それは「ELT」というプロセス(工程)です。ELTは、Extract(抽出)、Load(書込)、Transform(変換)の3つの頭文字を指しています。
データ基盤は、様々なデータを集めてきて、1つの基盤に集約します。散在するデータを1つに集めてくるのに、大事なプロセスが、この「ELT」になります。
ELTのイメージは、以下の通りです。
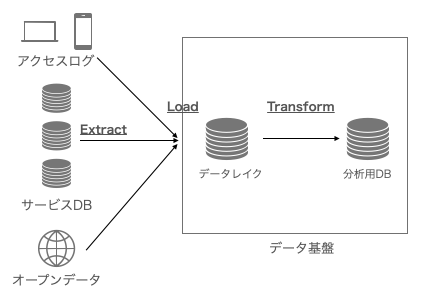
実は、これまでは、ELTではなく、「ETL」の方がよく利用されていました。意図する単語は変わらないのですが、順番が、Extract(抽出) → Transform(変換) → Load(書込) となっています。
この順番が示すように、散在するデータを抽出し、取り込み易さや事前の前処理等を実行してから、データ基盤へ書き込む流れとなっています。
両者の違いは、「各システムから抽出してきたデータを先に変換してからデータ基盤に書き込む」のか、「抽出してきたデータを一旦書き込んでから変換をする」のかの違いになります。
従来は、自社内に、オンプレミス環境(自社で必要なサーバ等を保有し運用する形態)で、データ基盤を構築することが多く、確保できるストレージ容量にも限りがありました。そのため、抽出したデータを変換して取り込む必要がありました。
一方で、ここ10年ぐらいで、クラウド環境のデータウェアハウス(様々なデータを集約し格納する倉庫のようなもの)が登場しており、容量をあまり気にすることなく、データを取り込むことが可能になりました。抽出したデータを事前に変換することなく、クラウド環境のデータウェアハウスへ取込み、その後に、必要な変換を行うことが一般的になってきました。
(勿論、データ基盤や連携に関わる各システムの運用の要件で、ETLの方が、適切なケースもあります。)
データ抽出機能に特化したAirbyteについて
上記で、ELTについて説明してきました。今回は、データ基盤の「収集」機能に的を絞っていますので、ELTのうち、ELのプロセスを実際に実行していきましょう。
昨今、じわじわと人気が出ているOSSに、Airbyte というものがあります。Airbyte社が開発している、ELをメインに行うツールです。また、クラウド版も提供しています。
参考: Open source data integration platform Airbyte launches its cloud service
Airbyteの良さは、システムをデプロイ後は、GUIで、簡単にELの設定を行えるところにあります。連携元のデータ(Airbyteでは「Source」と呼ぶ) と 連携先のデータベースやデータウェアハウス(「Destination」と呼ぶ) を指定し、その両者を繋げることで、ELの設定が出来上がります。(「Connection」と呼ぶ)
通常ですと、データの連携元からデータを抽出する処理や抽出したデータを連携先へ書き込むプログラムを作成する必要がありますが、それらを全て、Airbyteが担ってくれます。
また、よく利用されるデータベースだけではなく、昨今、よく見聞するSaaS (例えば、HubSpot, Asana, Jisa等)のコネクターも提供されており、様々なデータの連携に利用できることが利点として挙げられます。
参考: Catalog of Data Integration Connectors | Airbyte
ELに必要な環境のセットアップ
それでは、実際に、AirbyteでEL処理を作っていきましょう。
今回は、以下のような構成で試してみたいと思います。
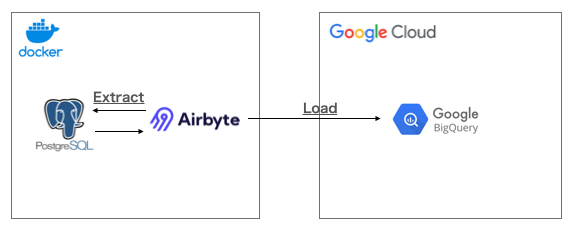
ローカル環境のDockerにて、Airbyte と PostgreSQLをセットアップし、Google Cloud(GCP) の BigQueryへのデータ連携を構築していきましょう。
今回は、あくまで、Airbyteの紹介ですので、Docker や PostgreSQL、GCPについての説明は省略します。
ローカル環境は、Mac (本記事の検証では、macOS 10.15.7 を使用) を利用しています。
また、BigQuery へデータを連携することで、僅かですが、課金が発生することにご注意ください。
(今回、利用するサンプルのデータベースは、容量は1GBもないため、BigQueryのデータ連携に掛かる料金は、1円にも満たない筈です。)
Airbyteのセットアップ
Airbyteの公式ページに従って、Dockerで環境を起動します。
Deploy Airbyte | Airbyte Documentation
| ## Airbyteのドキュメントに従い、以下のコマンドを順番に実行 git clone https://github.com/airbytehq/airbyte.git cd airbyte docker-compose up ※起動 |
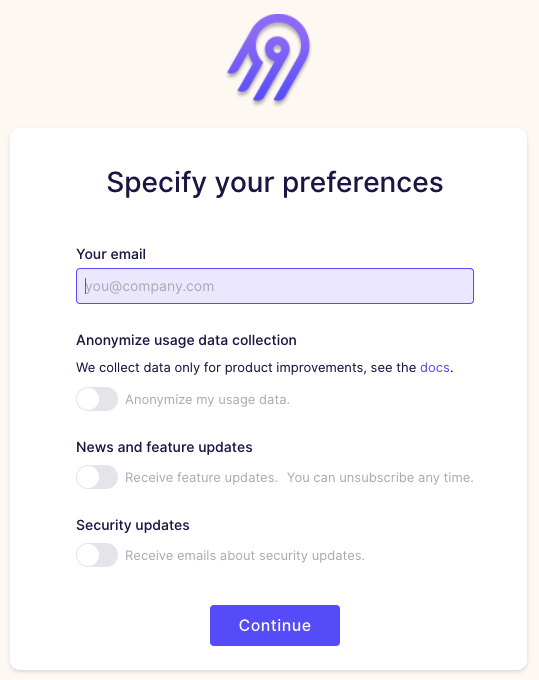
無事に起動できたら、ブラウザで、以下のURLにアクセスします。
以下のような画面が表示されますので、ご自身のメールアドレスを入力して、Continue をクリックします。
PostgreSQLのセットアップ
今回は、ELのお試しですので、ローカル環境に、簡易的にDockerでデータベースの環境を作成します。
| docker run --rm -d --name airbyte-source -e POSTGRES_PASSWORD=postgres -p 2000:5432 postgres |
これで、airbyte-source という名前のコンテナ環境に、PostgreSQLのデータベース環境が出来上がりました。今回は、PostgreSQLの公式ページでアップされているサンプルのデータベースを利用します。
サンプルのデータベースは、DVDのレンタルに関するデータのようです。
PostgreSQL Sample Database
以下のコマンドを実行して、PostgreSQLにデータベースを構築します。
コマンドを実行する場合は、本記事に添付している restore.sql というファイルを事前にダウンロードしておいてください。
| ## "dvdrental" というデータベースを作成する docker exec -it airbyte-source psql -U postgres -c "CREATE DATABASE dvdrental;" ## 上記で作成した"dvdrental"のデータベースへサンプルデータをリストアするcat {restore.sql までのパス} | docker exec -i airbyte-source psql -U postgres -d dvdrental |
[補足]
PostgreSQLの公式ページに公開されているサンプルデータをリストアするには、幾つかのステップを踏む必要があります。より簡単にデータベースを構築できるように、バックアップファイル(restore.sql)を用意しました。あくまで、今回のAirbyteのお試しのみにご利用ください。
無事に、PostgreSQLの環境がセットアップされたら、データベースにアクセスしてみましょう。
|
## postgresql on dockerへの接続 dvdrental=# \dt ※データベース接続後は、\dt を入力 |
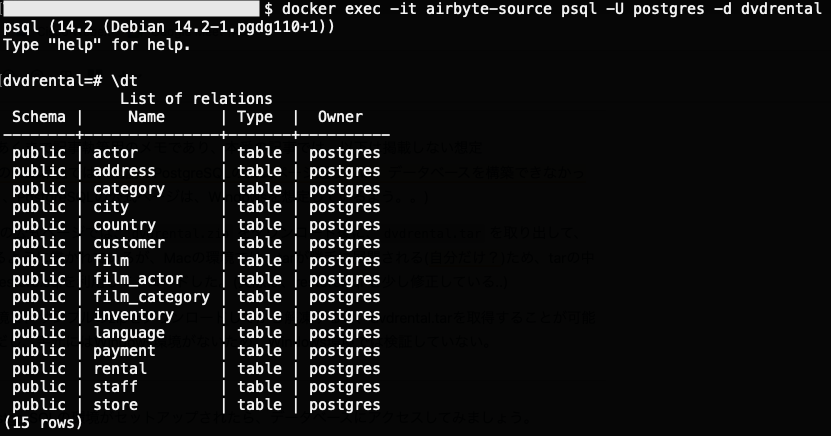
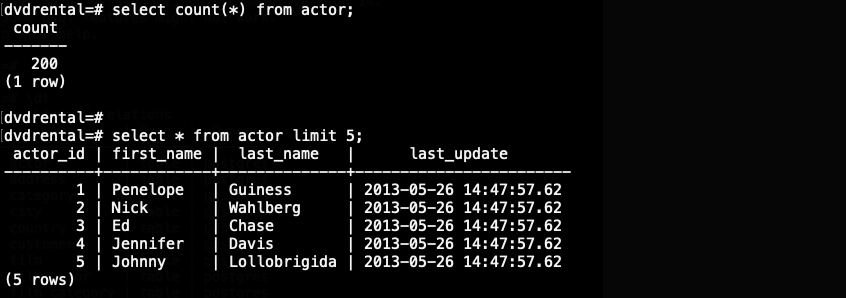
また、折角ですので、データベースの actor テーブルを確認してみましょう。
| ## actor テーブルのレコード数の確認 dvdrental=# select count(*) from actor; ## actor テーブルの一部のレコードを確認 dvdrental=# select * from actor limit 5; |
BigQuery のデータセットの作成
既に、GCPのプロジェクトは用意されていることが前提です。今回のEL処理によるデータ連携先のデータセットは、test_destination と命名しておきます。
Airbyte上での設定
必要な環境が揃いましたので、Airbyte上での設定を進めましょう。
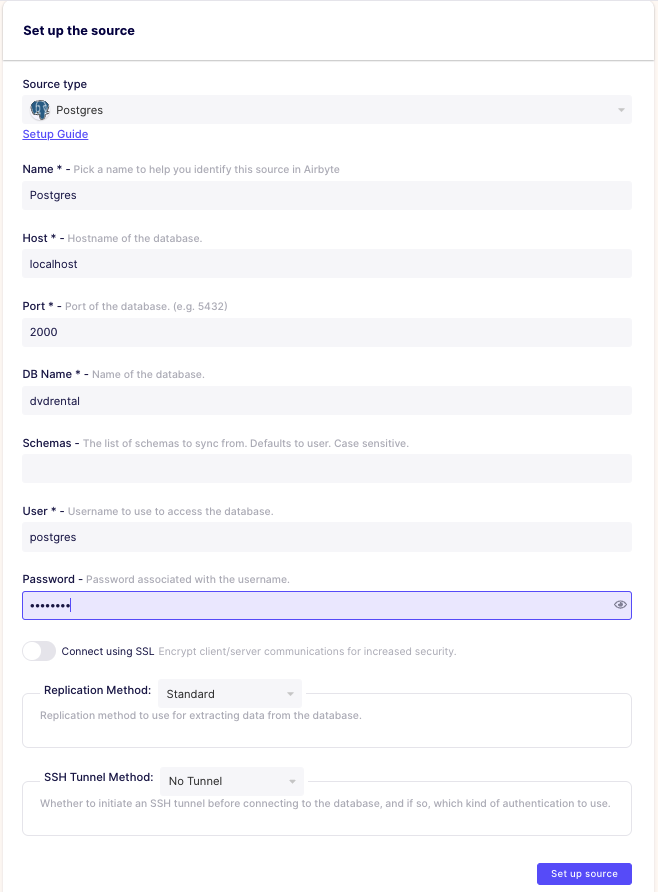
まずは、連携元の「Source」の設定を行います。Source type は、Postgres を選択し、画面のように設定していきます。
次に、連携先の「Destination」の設定を行います。Destination type は、BigQuery を選択し、画面のように設定してきます。
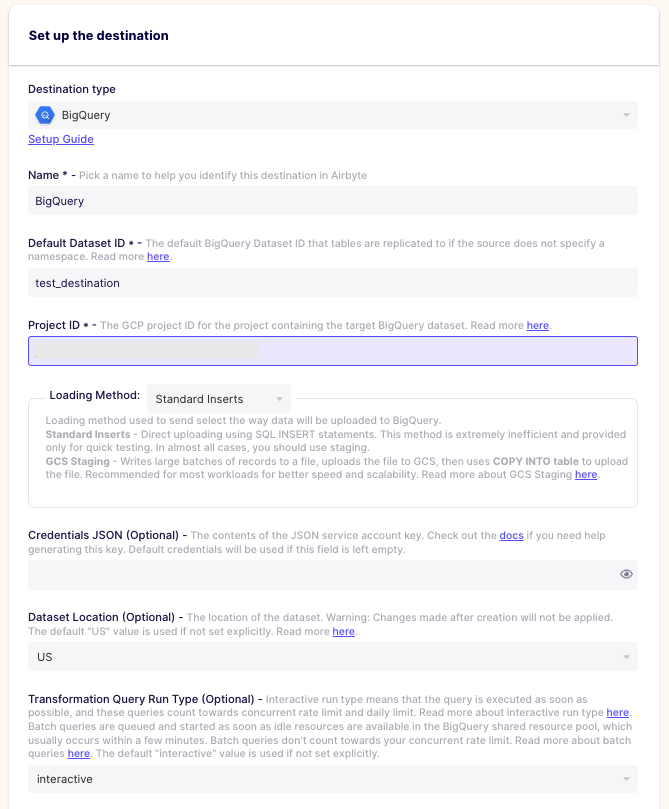
1点注意が必要です。
画面中央より、やや下部に表示の Credentials JSON には、必要な権限を持つサービスアカウントのKeyファイル(json)の中身をコピー&ペーストする必要があります。
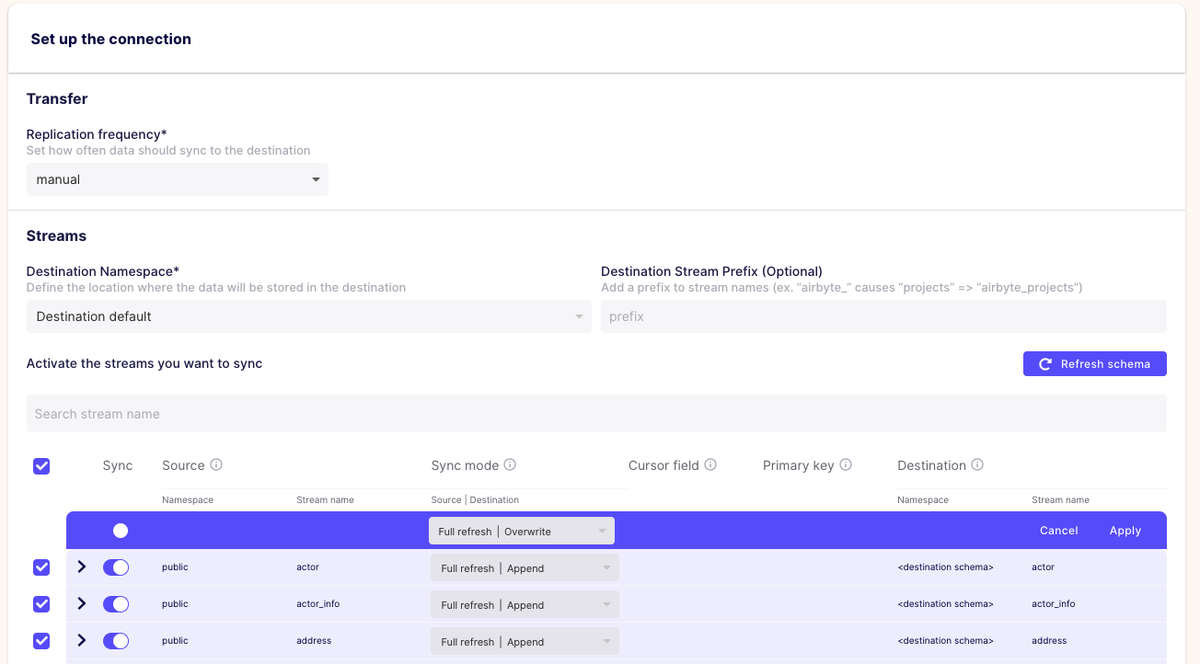
最後は、「Connection」の設定を行います。
先ほど、設定してきたSource と Destination を 繋ぐ設定を行います。つまり、ここまでの画面上での設定は、まさに、ELの設定を行ってきたことになります。
この画面で、連携する頻度(画面上部の「Replication frequentry」) や Source と Destination の テーブルデータの連携の仕方を選択することができます。
今回は、以下のように設定します。
- 頻度: manual * 自動ではなく、手動で連携を開始(スケジュールを設定することも可能)
- 連携モード: Full refresh | Overwrite
※Full refresh: Sourceの前回の連携に関係なく、全てのデータを連携対象とする
Overwrite: Destinationの既存のデータを全て上書き保存する。
Full Refresh - Overwrite | Airbyte Documentation
AirbtyeによるELの実行
先ほどまでで、全ての設定は完了しました。Airbyteの画面のConnections をクリックすると、以下のように、設定したConnection が参照できますので、早速、「Sync now」をクリックしてみましょう。
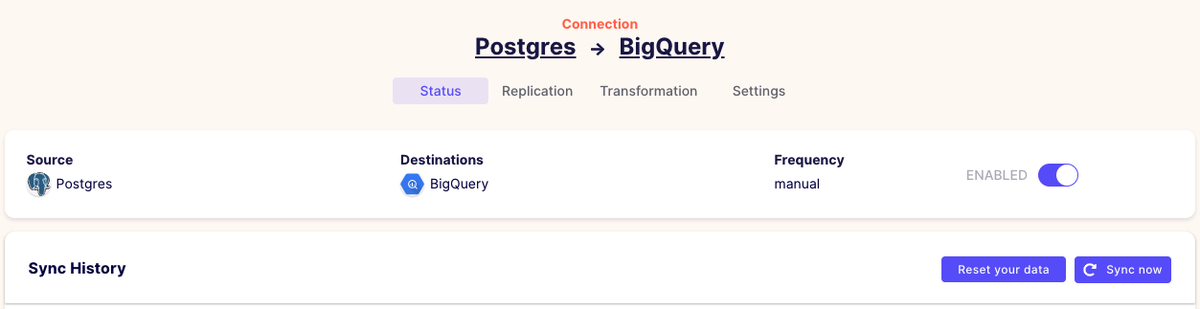
無事に連携が完了すると、以下のように画面表示されます。
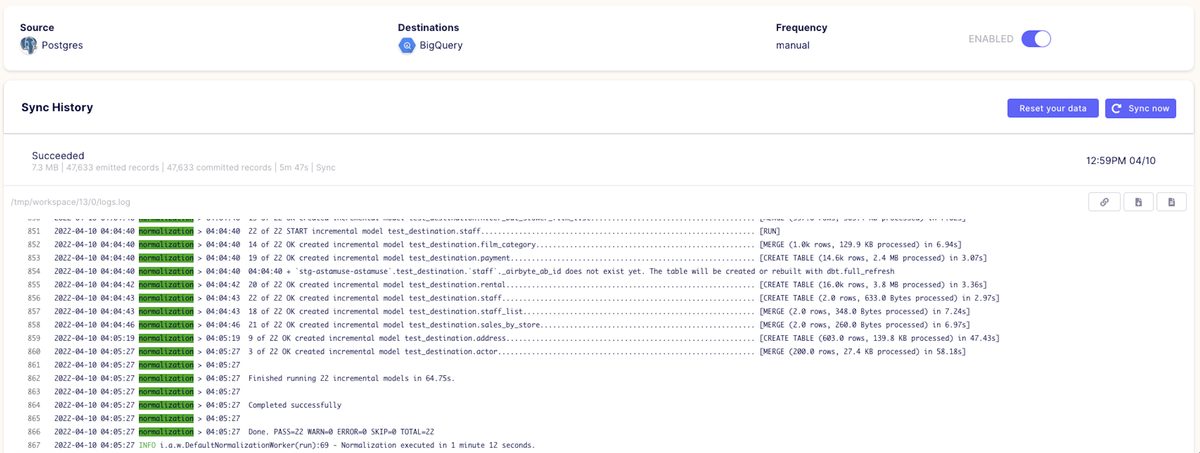
それでは、BigQuery 側の方を確認してみましょう。PostgreSQL で作成していた dvdrental の 各テーブル が、test_destination データセット配下に連携されていることが確認できました。
今回は、手元で、簡易的にEL処理を体験するために、ローカル + GCP の構成で実践してみました。
実際上は、Airbyte のデプロイ先の選定やデータ連携元、連携先の設定等を細かく検討・設定する必要があるかと思います。
また、注意点として、今回、連携したデータをBigQueryに残したままですと、僅かながら、課金が発生してしまいます。データを残しておく必要がない場合は、作成したデータセットごと削除することをおすすめします。
まとめ
- EL処理を構築するには、データの抽出や書き込むプログラムを作成する必要があるが、Airbyteを利用することで、GUIで、ELの設定を行うことができる
- Airbyteでは、連携元のSource と 連携先の Destination、それらを繋ぐ Connection の設定を行うことで、EL処理を構築することができる。また、連携対象のデータは、よく利用されているデータベースやデータウェアハウスだけではなく、様々なSaaS も含まれている
- 今回は、あくまでお試しのため、ローカル環境にAirbyteを構築したが、実際の運用では、何らかサーバ環境(オンプレミス環境 or クラウド環境)を用意したり、データ連携の設定などを細かく検討・設定する必要があることに注意。
