
本稿は近年注目を集めているResponsible AI(責任あるAI)の実現をサポートする技術トピックとそれぞれのトピックの実現をサポートするツール群を紹介します。
AI が引き起こす問題
AIの精度に関する知見がたまり、AIや機械学習が利用されることが一般的になるにしたがって、機械学習を利用したサービスやプロダクトが意図しない箇所で問題を引き起こすことがわかってきました。
最もよく知られている問題はAIが学習する際に意図せず偏見や倫理的に問題がある要素をモデルに取り込んでしまう点です。またプライバシーに関する情報を利用してモデルを生成することで、意図せず公開するべきではない情報が漏れてしまうことも考えられます。
AIが引き起こした問題として有名なのはマイクロソフトのAIボットの事例があります。公開されたAIボットははじめは問題なく動作していたのですが、ユーザフィードからのバックを学習に使うことで暴言、特に人種差別的な言葉を発するようになりました。Amazonの事例も有名です。Amazonが社内で使用してた採用ツールは女性の候補者が受かりにくいバイアス(偏見)を持っていたために使用が中止されました。
このような問題が注目を集めるにつれ、AIを活用したサービスを提供する側はシステムの精度だけに関心を持つだけでは十分ではないことが理解されてきました。
Responsible AI とは?
Responsible AI (責任あるAI) はサービスの提供者がプロダクトでAIを利用する際に発生する問題に責任を持つための取り組みを指します。取り組みには生成したAIのモデルが偏見を含んでいないかの検査などAIシステムに特徴的なものが存在します。
Responsible AI が満たすべき原則
AIを活用したサービスを提供する各社はそれぞれ責任あるAIを満たすための取り組みをしています。その中でもマイクロソフトは「責任あるAIがみたすべき6つの原則」についてまとめています。以下は原則の一覧です。
- 公平性 AI システムはすべての人を公平に扱う必要があります
- 信頼性と安全性 AI システムは信頼でき安全に実行する必要があります
- プライバシーとセキュリティ AI システムは安全であり、プライバシーを尊重する必要があります
- 包括性 AI システムはあらゆる人に力を与え、人々を結びつける必要があります
- 透明性 AI システムは理解しやすい必要があります
- アカウンタビリティ AI システムにはアカウンタビリティが必要であり、システムについて関係者への説明責任や説明義務が発生します
上記の原則の「公平性」や「安全性」からAIが引き起こしてしまう予期せぬ振る舞いが問題になっているのがわかります。また予期せぬ振る舞いを起こさないように、「透明性」、「アカウンタビリティ」で語られているようにAIの挙動が理解できるようにAI (機械学習) が生成するモデルの構造が理解しやすくあることが求められているのがわかります。
Responsible AIが満たすべき原則にはほかと少し毛色のちがう「信頼性」という項目も存在します。AIシステムの信頼性は一般的なシステムの信頼性の意味に加え、モデルとデータが乖離して精度が低下してしまうことに関するケアも含まれます。上記の原則の「公平性」や「安全性」からAIが引き起こしてしまう予期せぬ振る舞いが問題になっているのがわかります。また予期せぬ振る舞いを起こさないように、「透明性」、「アカウンタビリティ」で語られているようにAIの挙動が理解できるようにAI (機械学習) が生成するモデルの構造が理解しやすくあることが求められているのがわかります。
技術トピックと6つの原則の関係
以下の節では責任あるAIの実現をサポートする技術トピックを解説してゆきます。解説する技術トピックは「解釈可能性」、「プライバシー」、「ドリフト検知」、「因果推論」、「MLOps」です。
以下はこれから解説する技術トピックがマイクロソフトが掲げる「責任あるAIがみたすべき6つの原則」とどう関連するかについてまとめた表です。
| 技術トピック | 関連する6つの原則 |
| 解釈可能性 | 透明性、公平性、アカウンタビリティ |
| プライバシー | プライバシーとセキュリティ |
| ドリフト検知 | 信頼性と安全性 |
| 因果推論 | 信頼性と安全性 |
| MLOps | 信頼性と安全性 |
本文書の後半では、この表の中にある「解釈可能性」をサポートするライブラリ、InterpretMLのサンプルを動かしてみます。
それでは技術トピックを紹介してゆきます。
解釈可能性
多くの機械学習器は指定されたフォーマットの入力に対して結果を返すブラックボックスのように動作します。しかし適用するドメインによってはなぜ機械学習モデルがその結果を出力したのかが問われることがあります。
AIや機械学習の研究開発では精度が重要です。精度を向上するために古典的な機械学習器であれば、あらゆる有効そうな特徴量やその組み合わせを元にモデルを作成します。近年、大きな発展を遂げた深層学習では多数の中間層をもつモデルで入力の各要素がどのように結果に影響をあたえるかを判断するのはさらに難しくなります。
解釈可能性をサポートする機械学習モデルは出力がどのような情報をどのような重みをつかってなされたのかについての根拠を示せます。Responsible AIの実現で重要になる解釈可能性を向上するための機能を提供するツールの中では現在AequitasとInterpretMLが人気があります。InerpretML、Aequitas はともにモデル中身についての情報を理解しやすい形で示してくれます。InterpretMLは入力データやモデルのバイアスを検知するだけではなく、モデルの中身が理解しやすい(Glass Box)機械学習アルゴリズム(Explainable Boosting Machine)の実装も提供しています。InterpretMLについては後の節で実際に使ってみます。
さらに Fairlearnはもう一歩進んだ機能を提供します。具体的には Fairlearnはモデルにバイアスが見つかった場合、モデルの判別精度をは落とさずバイアスのみを軽減する追加学習アルゴリズムを提供します。
プライバシー(差分プライバシー)
マイクロソフトの責任あるAIが満たすべき原則にもプライバシーという項目があるように、データのプライバシーはデータを扱うシステムが責任を持つべきです。
プライバシーを確保する技術は多岐に渡ります。その中で差分プライバシーはApppleが個人情報を差分プライバシー技術で保護していることを発表し注目を集めている技術です(Appleが2016年に開催したWWDC)。
差分プライバシーはサンプリング技術とデータへのノイズ追加を組み合わせることでユーザの個人情報を保護したままデータ活用を可能にします。機械学習においても差分プライバシーを技術を利用することで個人情報を十分に保護した状態でモデル構築できるようになります。
OpacusはMetaが管理しているPyTorchモデルのトレーニングに差分プライバシーを簡単に採用するためのフレームワークです。そのほかにも差分プライバシーを用いた学習をサポートするツールにPyVacy、OpenDPなどがあります。
ドリフト検知
機械学習器のに日々入ってくる入力データは学習時のデータの傾向と徐々にズレていく(ドリフト)が発生するがあります。入力データの傾向が変化することで機械学習の精度が低下してしまうことが知られています。データの傾向が変わったことに気がつかないまま、機械学習を利用したサービスが動作し続けると出力の精度が下がってしまい、サービス事態への信頼性も揺らいでしまいます。
そのため信頼できるAIを目指す上でデータのドリフトを検知することは重要です。 Evidently やDeepchecksは入力データの変化(Data Drift)の検知をサポートします。
ドリフト検知については当ブログ記事「機械学習の運用に欠かせないドリフト(Drift)の概念と重要性」で詳しく書かれています。記事を読むことでこのトピックについて理解を深めるられるでしょう。
因果推論
一般的に機械学習はデータの相関関係を元にして出力します。しかし相関だけに基づいてモデリングすると、因果関係はないにもかかわらずたまたま相関がある情報(疑似相関)を利用したモデルを生成してしまうことがあります。疑似相関に基づいたモデルは入力の変化にも弱く、品質の高い結果を恒常的に返す責任あるAIを目指す上で問題になります。
因果推論はそのデータに内在する因果関係(原因と結果との関係)を統計的に推定していく手法です。因果推論を利用することでモデルで使用される変数と出力には相関はあるが、それは疑似相関にすぎないという事態を回避できます。
そのためデータを入手したら即座に機械学習器を利用して学習するのではなく、まずはじめに因果推論を利用してそのデータ生成されたドメインの理解を進めることが重要になります。
OSSの因果推論ツールはいくつか存在します。DoWhyはマイクロソフトが作成した因果推論ツールです。そのほかに、causalnex、Causalinferenceなども同様に因果推論で利用できるライブラリです。
MLOps
機械学習を利用したシステムでもシステムの頑健性は一般的なシステムと同じく重要です。システムが動作しなかったり、処理速度が十分ではなかった場合、そのAIシステムはやはり十分に責任を果たしているとは言えないでしょう。
そう言った意味でMLOpsやAutomated MLのような頑健な機械学習システムを構築するためのトピックやツール群もまたResponsible AIを支える技術と言っていいでしょう。
それでは、これまで紹介してきたResponsible AIを支える技術トピックのなかの「解釈可能性」をサポートするツール、InretertMLを試してみましょう。
InterpretML
InterpretMLはマイクロソフトが提供する機械学習ツールで、モデルの解釈をサポートする機能を提供します。ではこれから実際に使ってみましょう。
InterpretMLは $ pip install intrepret でインストールできます。
準備
以下はInterpretMLのサンプルで使用されているデータで、約5000人の賃金に関する情報が含まれています。データはUCIのMachine Learning Repository で公開されているものです。
|
import pandas as pd df = pd.read_csv( seed = 1 |
上記のコードではデータを収入(Income)が5万ドルを超えるかで分類するためのデータに加工しています(変数yの中身)。
InrepretMLを利用した入力データの傾向分析
このデータを実際にInterpretMLで分析します。分析するには以下のようなコードをJupyter Notebookに記述します。
|
from interpret import show
hist = ClassHistogram().explain_data(X_train, y_train, name = 'Train Data') |
すると以下のようにデータの各変数の傾向が描画されます。

注:上記のコードでグラフが描画されない場合、以下のコードを show(hist) の前に追加してください
|
from interpret.provider import InlineProvider
set_visualize_provider(InlineProvider()) |
上記の図は年齢(Old)についての傾向について描画されています。これから30代から40代が年収が高い割合が高いのがわかります。
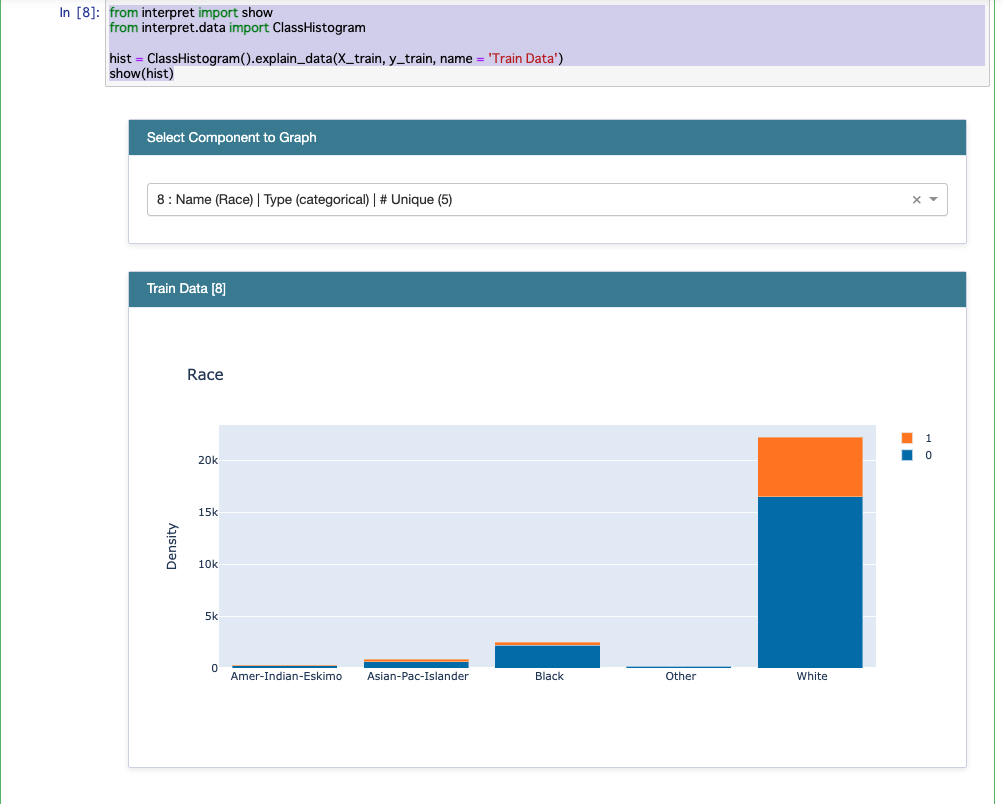
また以下は人種(Race)についてフォーカスした結果です。このデータでは白人のサンプルが多いのですが、年収が多い人数の割合自体も多くなっているのがわかります。
学習およびモデルの分析
IntretML は ExplainableBoosting という分類器の実装をサポートしています。ExplainableBoostingは生成するモデルの状態が理解しやすく「グラスボックス」でさらに十分な精度をもつ機械学習器です。
以下はExplainableBoostingで学習するためのコードです。
|
from interpret.glassbox import ExplainableBoostingClassifier
ebm = ExplainableBoostingClassifier(random_state=seed, n_jobs=-1) |
前節では入力データの偏りを描画しましたが、InterpretMLではモデルに内在する偏りも表示できます。モデルの状態を描画するには以下のようにshowコマンドにモデルを引数に与えます。
| ebm_global = ebm.explain_global(name='EBM') show(ebm_global) |

このようにInterpretMLでは入力だけでなく、モデルの中に存在するバイアスも描画されるため、モデルが倫理的な問題を保持していることを開発者が気がつきやすくなります。
まとめ
本稿ではAI が引き起こす問題の反省から、Responsible AI (責任あるAI) が注目をあつめる現在の状況について解説しました。次にResponsible AI が満たすべき原則について解説し、責任あるAIを支える技術トピック(ドリフト検知、解釈可能性、公平性、差分プライバシーなど)について紹介しました。
最後に、解釈可能性の実現をサポートするInterpretMLについて使い方を紹介しました。
