
こんにちは!nakamura(@naka957)です。
ドリフト(Drift)という言葉をご存知でしょうか?機械学習のサービスを運用する上で重要な項目ですが、知らない人も多いのではないでしょうか。
機械学習プロジェクトは、モデルを構築するまでがゴールではありません。本番環境での運用を続けることがゴールです。ところが、本番環境モデルは徐々に精度が低下していきます。そのため、時機を見計らって再学習が必要です。
このように、モデルの精度が想定からズレることをドリフトすると言います。ドリフトはモデルの運用のために重要となる概念です。
本記事では、ドリフトの概念と重要性を説明していきます。
ドリフトとは
ドリフトとは、本番環境のモデル精度が低下する現象を指します。
ドリフトは主に2種類に分けられ、コンセプトドリフトとデータドリフトとそれぞれ呼ばれます。詳細は後述しますが、コンセプトドリフトは入力データとモデル出力の関係性が変わることです。一方、データドリフトは入力データ自身の性質が変わる現象を指します。
ドリフトの検知は本番環境の運用において非常に重要です。なぜなら、本番環境でモデル精度が低下するドリフトの発生は、機械学習を活用する意義の低下に直結するからです。そのため、モデルの精度低下の検知に繋がる、ドリフト検知は重要な意味を持ちます。
最初に、一般的な機械学習プロジェクトの全体ワークフローを確認しておきましょう。

機械学習モデルの構築までの一連の流れは、データ準備、特徴量抽出、モデル訓練・評価となります。モデルの精度が必要な水準に到達すれば、本番環境へデプロイされます。
多くの機械学習エンジニアは、モデルのデプロイまでに携わる人が多いのではないでしょうか。しかし、実際には本番環境へのデプロイ後も、運用する工程が存在します。モデルは運用に伴い、徐々に精度が悪くなるため、精度維持のためには新しいデータでの再学習が必要となります。
ドリフト検知は、再学習の必要性を判断する強力な方法になります。以降で、より詳細なドリフトの説明を行っていきます。
コンセプトドリフト
入力データと予測対象(モデル出力)の関係性が変わることを、コンセプトドリフトと呼びます。
簡単にイメージしてみましょう。機械学習は入力データと予測対象(モデル出力)の関係性をデータから推定する方法です。下図において、関数 f(x)がモデルに相当し、f(x)の具体的な表式を訓練データから推定する形になります。
コンセプトドリフトは、f(x)の表式が変化することです。入力データ x に変化がなくとも、f(x)の変化で予測結果が変化するため、ドリフトが発生します。典型的な例としては、f(x)が季節で変動する場合です。
コンセプトドリフトは大きく次の4種類に分類されます。
- 突然生じるタイプ
- 徐々に変化するタイプ
- 確実に段階的に生じるタイプ
- 繰り返しのドリフト
突然生じるタイプもあれば、時間の経過で徐々に生じるタイプもあります。また、季節に代表される、繰り返し生じるタイプもあります。
発生の仕方も様々なため汎用的な検知方法はなく、様々な手法を組み合わせる必要があります。より詳しい内容に興味がある方はこちらの文献が参考になります。
データドリフト
入力データ自身の性質が変化することをデータドリフトと呼びます。
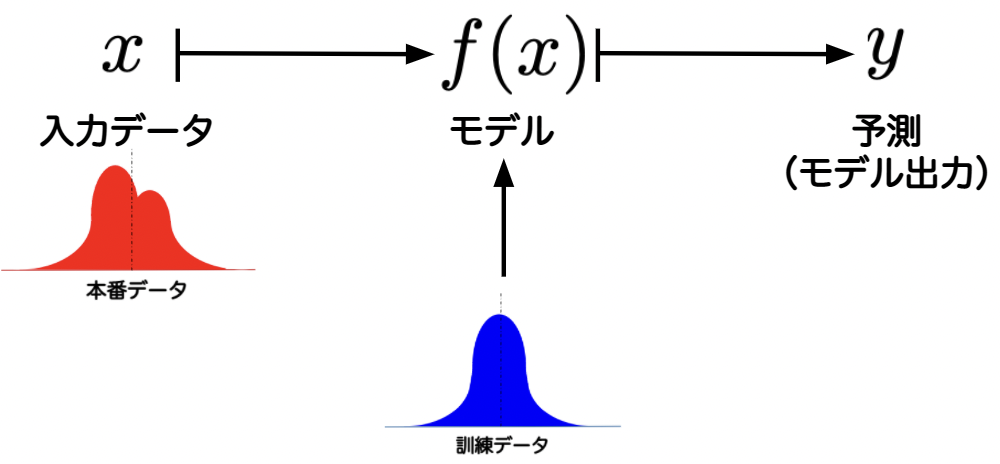
データの性質が変わるとは、統計的性質が変化することです。イメージとしては、分布形状が変化すると考えてください。例えば下図のように、分布のピーク数が訓練データでは1つに対して、本番データでは2つとなっています。このような場合は明らかに性質が異なることがわかると思います。

すでに述べた通り、機械学習は入力データと予測対象(モデル出力)の関係性をデータから推定する方法です。そのため、訓練データと本番データの性質が異なると予測結果も変わるため、モデル精度の低下に繋がります。このため、データドリフトの検知はモデル精度を保つために重要な手法になります。
データドリフトの原因は、主に次の2つの場合が挙げられます。
- データ自体に誤りが生じる
- 環境変化に伴いデータが変化
1つ目の「データ自体に誤りが生じる」とは、
- データ形式が変更されたが、未反映のままデータが収集されている
- 人為的なミス(ex. 項目を間違えたなど)
といった理由が原因となります。
機械学習システムの全体は複雑のため、上記のような現象が起きた場合でも気づかないことも少なくありません。
例えば、データを収集する機械の故障やネットワーク障害の場合が考えられます。故障した機械が不正確なデータを送信し続けたり、ネットワーク障害が発生した期間は送信データがNull値として受け取られる可能性があります。このような場合でも、モデルが予測し続ける場合は十分に考えられます。
考えたくはありませんが、データの前処理でNullをゼロ値に置き換えていれば、みかけは正常に動作しているようにみえるでしょう。また、数値データの列を入れ替えても同様にモデルは動作するでしょう。
問題の発生を認識できず、正常にみえた状態で運用されることは大きなリスクであり、データドリフト検知の仕組みが威力を発揮する場面になります。
2つ目の「環境変化に伴いデータが変化」は、ごくあたりまえに生じる現象です。例をみれば想像頂けると思います。
- 不測事態の発生
- 自然災害
- COVID19
- 時代の変化
- 固定電話からスマートフォンへの変化
- 情報媒体の変化(TVからSNSへ)
- 経年変化
- 機械の経年劣化
- 地球温暖化
例えば、COVID19により人々のライフスタイルは劇的に変化しました。休日の過ごし方に関するアンケートをとれば、COVID19前後で劇的に変化しており、以前のデータは参考にならないでしょう。
このように、データの性質に変化が起きた場合、古いデータで構築したモデルは、想定していた精度は期待できません。新しいデータで再学習する必要があります。
ドリフト検知後の再学習
ドリフトの発生で精度が低下したモデルは、再学習が必要です。新しいデータで再学習後、再び本番環境へデプロイする形になります。
ドリフトの検知と再学習までを含めた、機械学習プロジェクトの全体ワークフローは下図となります。
以前のワークフローとの違いは、本番環境へデプロイ後に、ドリフト検知と再学習の工程が追加されている点です。また、必要に応じて、前処理と特徴量抽出の再検討も想定されます。
本番環境でモデルの精度を保つために、ドリフト検知の仕組みを含めたワークフローで進めることが必須となります。
まとめ
ここまでドリフトの概念と重要性を説明してきました。
本番環境のモデルが精度低下する現象をドリフトと呼びます。また、ドリフトにはコンセプトドリフトとデータドリフトの2種類があることを紹介しました。
機械学習プロジェクトのゴールはモデル構築ではなく、運用を見据えたドリフト検知の仕組みまでを整備することです。
そして、本番環境での運用では、ドリフト検知とモデルの再学習を適切に行うことで、精度を維持した機械学習サービスを提供することが可能になります。
参考文献
- https://evidentlyai.com/blog
- Jie Lu, Anjin Liu, Fan Dong, Feng Gu, Joao Gama, Guangquan Zhang, “Learning under Concept Drift: A Review”, arXiv:2004.05785, 2020.
