
こんにちは! nakamura(@naka957)です。
今回はクラスタリングをご説明します。クラスタリングは教師なし学習に代表される手法の1つで、正解情報なしでデータ間の類似性を推定し、グループ化する手法です。DATA Campusでは、これまでに教師なし学習の概要とその手法の1つの主成分分析について解説しています。そちらも是非参考にしてみてください。
本記事では、最初にクラスタリングの概念と主要な手法であるk-means法について説明します。次に、実装例の紹介に加え、同じ教師なし学習である主成分分析と組み合わせることで、クラスタリングをより有効に機能する例も紹介します。k-means法は単純なアルゴリズムで、様々な場面で簡単に適用できる手法です。是非、この機会にマスターしてみてください。
では、早速始めていきます!
- クラスタリングとは
- k-means法: クラスタリングのアルゴリズム
- エルボー法: クラスター数の決め方
- 実装例: 手書き数字画像(MNIST)のクラスタリング
- データセット準備
- 標準化でスケールを揃える
- クラスター数の検討
- クラスタリング結果
- 応用例: 主成分分析とクラスタリングを組み合わせる
- 主成分分析
- 主成分に対するクラスタリング
- 結果の可視化
- まとめ
- 参考
クラスタリングとは
クラスタリングはデータから類似性を抽出し、類似のグループへ分類する手法です。分類されたグループのことをクラスタと呼び、類似性を算出する方法は色々あります。
クラスタリングのアルゴリズムには大きく2種類があり、階層クラスタリングと非階層クラスタリングがあります。名前の通り、クラスタへの分類を階層的に行うか否かで異なります。また、使用する立場の観点からも、事前にクラスタ数を決める必要性の有無で違いがあり、階層的な場合は事前に決める必要はありません。一方で、非階層的な場合は事前にクラスタ数を決める必要がありますが、単純なアルゴリズムで適用が簡単という利点があります。アルゴリズム違いの利点は一長一短ですので、両方を使いこなせることをお勧めします。
本記事では、非階層クラスタリングの代表的なアルゴリズムであるk-means法をご紹介します。事前にクラスタ数を決める必要性がありますが、クラスタ数の決定を手助けするエルボー法と呼ばれる手法も併せてご紹介します。
k-means法: クラスタリングのアルゴリズム
k-means法は、データの中心点を設定し、中心点からの距離を類似度とみなす手法です。距離が近いほど類似度が高くなり、直感的なアルゴリズムである点からも人気が高い手法です。分類は、クラスタ数に応じた中心点を設定し、距離に基づきグループ化することで行われます。教師なし学習と言えども、事前にクラスタ数や中心点の定義方法(ex. 平均値や中央値)は分析者自身が決める必要があります。
k-means法によるクラスタリング(グループ化)の手順は、以下の手順を繰り返す形です。ただし、各クラスタの中心点の初期位置はランダムに設定する場合が一般的です。
- Step 1. 各点を中心との距離が最も近いクラスタに所属させる
- Step 2. 各クラスターの中心位置を再計算する
- Step 3. 新しい中心位置を用いて、各点の所属クラスタを再計算する

上記のStep 1–3の手順を、各点の所属クラスタの変化がなくなるまで繰り返します。最終的に所属したクラスタが得られた分類結果となります。
k-means法は単純なアルゴリズムの手法のため簡単に適用できます。加えて、データ自身に構造が潜んでいる場合には有効な場合がしばしばあり、データ分析の初期段階で使用されることが多い手法です。
エルボー法: クラスター数の決め方
非階層クラスタリングのk-means法では、クラスタ数は事前に分析者が決める必要があります。ただし、決定的な決め方はなく、データに対する背景知識や目的から判断する必要があります。例えば、データである画像に対して、事前知識として猫と犬の画像であると知っていれば、クラスタ数は2と決定できます。
決定的な方法はないと述べましたが、クラスタ数の検討を補助する手法はあり、今回はエルボー法と呼ばれる手法をご紹介します。
エルボー法は、各データの所属クラスタ中心からの距離の2乗の和(誤差指標)に関して、クラスタ数を変化させた時に誤差指標の変化をみます。イメージとしては、適切なクラスタ数で分類すれば、誤差指標が十分小さくなるという考え方です。横軸にクラスタ数、縦軸に誤差指標を取り、その際の振る舞いがエルボー(肘)の形を連想させる下図のイメージとなることを期待します。誤差指標の変化の変曲点に位置するクラスタ数を採用します。
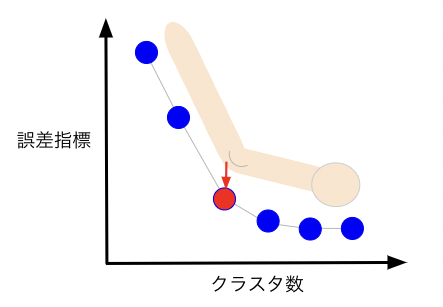
ただし、実際のデータ分析では上図のような期待する振る舞いにならない場合も多く、誤差指標が徐々に減少するような場合も多いです。そのような場合は、前処理の適用で改善を行う方法や、データ背景から推定することが考えられますが、様々なクラスタ数で試すことが大事です。本記事では、応用例の節で前処理として主成分分析を適用し、エルボー法の振る舞いが改善されることをみていきます。
実装例: 手書き数字画像(MNIST)のクラスタリング
今回は、手書き数字の画像データにk-means法を適用し、クラスタリングされた分類結果が数字と対応するか確認してみます。
分析の手順は次の通りです。
- データセットの準備
- 標準化でスケールを揃える
- クラスタリングの実行
事前に今回使用するライブラリを全て読み込んでおきます。また、今回のコード例は、Jupyter Notebook上での実行を想定した表記としています。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_digits from sklearn.preprocessing import StandardScaler from sklearn.cluster import KMeans from sklearn.decomposition import PCA
データセット準備
手書き数字の画像データセット(MNIST)は0から9までの手書き画像で、Pythonの機械学習ライブラリscikit-learnにも含まれており、簡単に使用できます。
mnist = load_digits() X, y = mnist.images, mnist.target
変数mnistはデータセットの情報を含んだインスタンスです。画像データはmnist.imagesで取り出すことができ、対応する画像のラベル(0〜9の数字)はmnist.targetで取り出せます。
試しに、インデックスが1番目のラベルと画像データを表示してみます。数字1とその画像が出力されます。
# 1番目の画像ラベル print(y[1]) # 1番目の画像データ plt.gray() plt.matshow(X[1]) plt.show()

今回はわかりやすさのため、数字を0, 1, 2の3種類に限定しましょう。
# 画像データから数字(0, 1, 2)を取得 X_select = X[(y == 0) | (y == 1) | (y == 2)] y_select = y[(y == 0) | (y == 1) | (y == 2)] print(np.unique(y_select)) # >> [0 1 2]
また、画像データの形状を変更します。画像は2次元データですが、取り扱いやすい形式の1次元へ変更します。
# 画像データを2次元から1次元へ変更 print(X_select.shape) X_select = X_select.reshape(X_select.shape[0], -1) print(X_select.shape) # >> (537, 8, 8) # >> (537, 64)
以上で、データセットの準備は完了です。
標準化でスケールを揃える
k-means法は各クラスタの中心点とデータ間の距離から分類する手法です。そのため、中心点とデータ間の距離は各特徴量のスケールの違いに影響を受ける点に注意が必要です。
特徴量間のスケールを揃える方法に標準化があり、平均と標準偏差をそれぞれ0と1へ揃えることができます。

pythonでは、scikit-learnを使用することで簡単に標準化を行えます。StandardScaler()モジュールで標準化のインスタンスを定義し、fit_transform()へ変数X_selectを渡すと、標準化された結果が返ってきます。
scaler = StandardScaler() X_std = scaler.fit_transform(X_select)
クラスター数の検討
今回は既に、画像の数字が0, 1, 2の3種類とわかっていますが、今回は練習のためにエルボー法を用いてクラスタ数を検討してみます。
今回は、クラスタ数が0から9までの範囲でk-means法によるクラスタリングを繰り返し、誤差指標の変化を可視化してみましょう。ただし、誤差指標とは、各データの所属クラスタの中心位置からの距離の2乗誤差の和です。
# 誤差指標の格納リスト # 誤差指標: 各データの所属クラスタの中心位置からの距離の2乗誤差の和 distortions = [] cluster_ranges = range(1,11) for cluster in cluster_ranges: # k-meansのモデル定義 kmeans = KMeans(n_clusters=cluster, init='random', n_init=10, max_iter=300, random_state=0) # クラスタリングの実行 kmeans.fit(X_std) # 誤差指標をリストに追加 distortions.append(kmeans.inertia_) # エルボー法の結果の可視化 plt.figure(figsize=(6, 6)) plt.plot(cluster_ranges, distortions) plt.xlabel('number of clusters', fontsize=14) plt.ylabel('distance', fontsize=14) plt.show()

エルボー法の結果を見ると、残念ながら誤差指標の急激な変化点(エルボー)は見えづらい結果となりました。全体的に徐々に誤差指標が減少する傾向で、画像データの数字が3種類である事前知識と整合しない結果となっています。
クラスタリング結果
クラスタリングを実行し、クラスタリング結果と実際の手書き画像を比較してみます。ここでは、クラスタ数を事前知識から決めた3を採用します。ただし、クラスタリング結果であるクラスタ番号(1, 2, 3)はプログラム内で自動で割り当てられ、手書き数字画像の数字とは対応しないことに注意してください。なお、クラスタ番号はコード実行の度に変化します。
fig, axes = plt.subplots(2,3, figsize=(10, 7.5), tight_layout=False) for i in range(2): for j in range(3): # 手書き画像を表示 axes[i][j].matshow(X_select[i+j].reshape(8, 8)) # クラスターをタイトルに表示 axes[i][j].set_title(f"cluster: {y_cluster[i+j]}", fontsize=16) # 軸の数値表示を消す axes[i][j].tick_params(labelleft=False, labeltop=False) plt.show()

上図を確認すると、クラスタ 2に所属する画像に数字の1と2が両方含まれている結果となっています。
以上の結果のように、データ間の類似性をばっちりと掴めることはできていない様子です。しかし、まずはざっくりと設定したクラスタ数で各クラスタに分け、各クラスタのデータを詳細に分析することで、データセットの背景理解をより深める方法も有効な教師なし学習の活用方法の1つです。
ただし、データ間の類似性を事前に前処理の形で明確化する方法も考えられます。手法の選択肢の1つに主成分分析が挙げられ、事前に主成分分析の適用で、主成分という形でデータ間の類似性が掴みやすくなる場合があります。次節で、先ほどのデータセットに主成分分析を事前に適用することで、エルボー法がより効果的に機能することをみていきます。
応用例: 主成分分析とクラスタリングを組み合わせる
クラスタリングの分類精度の向上を目的に、事前にデータ間の類似性をより明確化することを考えます。今回は、同じ教師なし学習の手法の1つである主成分分析を活用します。主成分分析については、前回の記事で詳しく解説していますので、是非参考にしてみてください。
■前回の記事:教師なし学習の実践 主成分分析で高次元データを可視化する
前節から追加する実施手順は次の通りです。
- 標準化後の手書き数字の画像(MNIST)に主成分分析を適用し、次元縮約
- 次元縮約後の第1・第2主成分に対して、k-means法でクラスタリング
- 横軸と縦軸をそれぞれ第1・第2主成分とし、結果を可視化
主成分分析
scikit-learnのPCA()モジュールでインスタンスを定義し、fit_transform()へ標準化後の変数X_stdを渡すと、主成分分析の結果が返ってきます。算出される主成分の数は、PCA()に渡す引数のn_componentsで指定します。
# PCAを実行し、第1と第2主成分を取得 pca = PCA(n_components=2) X_pca = pca.fit_transform(X_std) print(X_pca.shape) # >> (537, 2)
以上で主成分分析は完了です! 変数X_pcaに第1・第2主成分が格納されています。
主成分に対するクラスタリング
再び、エルボー法でクラスター数を検討してみます。k-means法を変数X_pcaに適用する以外は、前回コードと内容は同じです。
# エルボー法 distortions = [] cluster_ranges = range(1,10) for cluster in cluster_ranges: # k-meansのモデル定義 kmeans = KMeans(n_clusters=cluster, init='random', n_init=10, max_iter=300, random_state=0) # クラスタリングの実行 kmeans.fit(X_pca) # 誤差指標: 各データの所属クラスターの重心位置からの距離の2乗誤差の和 distortions.append(kmeans.inertia_) # エルボー法の結果の可視化 plt.figure(figsize=(6, 6)) plt.plot(cluster_ranges, distortions) plt.scatter(cluster_ranges, distortions) plt.xlabel('number of clusters', fontsize=14) plt.ylabel('distance', fontsize=14) plt.show()
今回は、グラフから縦軸の誤差指標の急激な変化点(エルボー:肘)がみられます!横軸のクラスタ数が3で変曲点となっており、画像の数字が3種類の事前知識と整合する結果となっています。
エルボー法からクラスタ数を3と決め、第1・第2主成分に対して再びk-means法でクラスタリングを行います。
# クラスタリング kmeans = KMeans(n_clusters=3, init='random', n_init=10, max_iter=300, random_state=0) kmeans.fit(X_pca) # 所属クラスターを取得 y_cluster = kmeans.labels_
次節での可視化のため、データセットとクラスタリング結果をpandasのDataFrame形式へ整形しておきましょう。
df = pd.DataFrame(data=X_pca, columns = ['pca_1', 'pca_2']) df['cluster'] = y_cluster df['label'] = y_select df.head()

結果の可視化
クラスタごとで色分けし描画します。左図がクラスタリングされた分類結果になります。また参考のため、右図に正解ラベルで色分けした結果を描画しています。
label_color = {'0':'red', '1':'blue', '2':'green'}
cluster_color = {'0':'red', '1':'blue', '2':'green'}
fig, axes = plt.subplots(1,2, figsize=(10, 5), tight_layout=True)
for i in np.unique(y_select):
# クラスタリング結果
pca1, pca2 = df['pca_1'][df['cluster'] == i], df['pca_2'][df['cluster'] == i]
axes[0].scatter(pca1, pca2, color=cluster_color[str(i)], label=f"cluster {i}")
# 正解ラベル
pca1, pca2 = df['pca_1'][df['label'] == i], df['pca_2'][df['label'] == i]
axes[1].scatter(pca1, pca2, color=label_color[str(i)], label=f"Label {i}")
# 軸ラベル
axes[0].set_xlabel('PCA 1', fontsize=14)
axes[0].set_ylabel('PCA 2', fontsize=14)
axes[1].set_xlabel('PCA 1', fontsize=14)
axes[1].set_ylabel('PCA 2', fontsize=14)
# 凡例
axes[0].legend()
axes[1].legend()
plt.show()

正解情報を一切使用していませんが、同じ数字(色)がグループ化されて分布している傾向がみえています。このように、正解情報なしで各数字画像間のデータに潜む構造を捉え、分類された結果が得られています。
まとめ
ここまでクラスタリングの説明と実装例を紹介してきました。
データに潜む構造を推定する方法としてクラスタリングは有効です。データ分析のタスクが教師あり学習の場合でも、教師なし学習の適用はデータセットの理解に有効な場合も少なくありません。
また、今回は非階層クラスタリングに代表されるk-means法の実装例をご紹介しました。もう一方の階層クラスタリングもよく使われる手法で、事前にクラスタ数を決める必要がない点からも実用性が高く人気の手法です。是非、そちらもチェックしてみてください。
参考
- https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
- https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
- https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
- https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
