
こんにちは!nakamura(@naka957)です。今回は、主成分分析(PCA)をご説明します。
主成分分析は教師なし学習の重要手法の1つです。教師なし学習は正解情報なしでデータのパターンを推測する手法です。その中でも、主成分分析は多数の特徴量を少数の特徴量で表現する手法です。言い換えれば、高次元のデータを低次元で表現するため、次元圧縮の手法とも呼ばれます。
本記事では、主成分分析の概要と実装例をご紹介します。実装例では、手書き数字の画像データを実際に次元圧縮してみます。手書き数字の画像データでパターンが観測されるか確かめてみましょう。
では、早速始めていきます。
主成分分析
主成分分析(Principal Component Analysis: PCA)は、多数の特徴量のデータセットを少数の特徴量で表現することを指します。そのため、高次元データを次元圧縮する手法として有名です。
具体的には、データを表現する軸(ex. x-y座標軸)を取り直すことに相当し、次の手順で主成分の軸方向を決めていきます。
- データのばらつきが最も大きい方向に第1主成分の軸を定義
- 第2主成分を第1主成分軸と直交し、ばらつきが最も大きくなる方向に定義
- 第3主成分以降も同様に、定義済みの主成分軸と直交方向かつデータばらつきが最大の方向に定義
わかりやすくするため、2次元データの例を下図に示します。第1主成分(PCA1)の軸方向は赤色矢印で、第2主成分(PCA2)の軸方向が青色矢印で表されています。第1主成分(赤色)方向で見た時、データのばらつきが最も大きくなります。別の表現をすると、第1主成分軸方向でデータの分布が最も広くなり、2次元のデータを第1主成分軸のみで(それなりに)表現できる形になります。
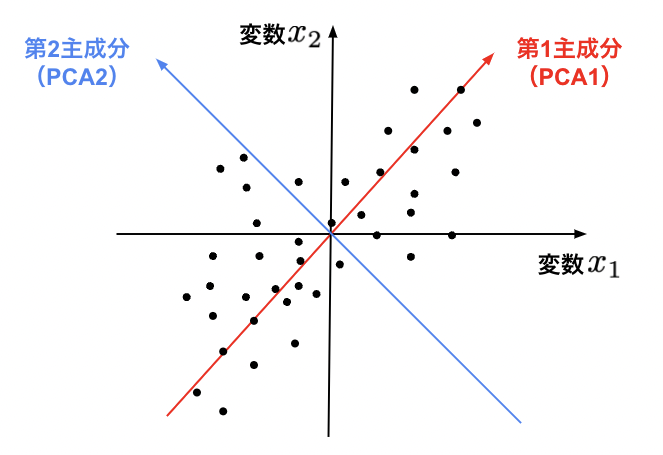
主成分分析の使い方の1つに、高次元データを低次元で表現し、可視化する方法があります。これは、情報量を多く持つ主要な主成分を軸に取る発想からきています。特に、人間は3次元までしか視覚的に認知できないため、高次元データを3軸で可能な限り表現したい場合に有効です。
実装例
主成分分析を実際に実装してみます。
今回は、手書き数字の画像データに主成分分析を適用し、主要な主成分を軸にデータを可視化してみます。果たして、手書き数字ごとのパターンが確認できるでしょうか。
分析の手順は次の通りです。
- データセットの準備
- データのスケールを揃える(標準化処理)
- 主成分分析の実行
- 主要な主成分を横軸と縦軸にとり可視化
まず、事前に使用する主要なライブラリを読み込んでおきましょう。
import numpy as np import pandas as pd import matplotlib.pyplot as plt
データセットを準備
使用するデータセットを準備します。手書き数字の画像データセットで有名なMNISTを題材にします。MNISTは0から9までの手書き画像のデータセットで、Pythonの機械学習ライブラリscikit-learnにも含まれており、簡単に使用できます。
from sklearn.datasets import load_digits mnist = load_digits()
変数mnistはデータセットの情報を含んだインスタンスです。画像データはmnist.imagesで取り出すことができ、対応する画像のラベル(0〜9の数字)はmnist.targetで取り出せます。
試しにデータセットの最初のラベルと画像データを表示してみます。
# 0番目の画像ラベル print(mnist.target[0]) # 0番目の画像データ plt.gray() plt.matshow(mnist.images[0]) plt.show()

数字0とその画像が出力されました。
では、ここからは画像データに主成分分析を行う準備をしていきます。まず、画像データとラベル情報をそれぞれ分けて変数へ格納します。
| X, y = mnist.images, mnist.target |
次に、画像データの形状を変更します。画像は2次元データですが、取り扱いやすい形式の1次元へ変更します。
print(f"変更前: {X.shape}") X = X.reshape(X.shape[0], -1) print(f"変更後: {X.shape}") # >> 変更前: (1797, 8, 8) # >> 変更後: (1797, 64)
変更後のデータ形状(1797, 64)は、データ数が1797個で64次元であることを表します。
標準化でスケールを揃える
主成分分析を実行する前にデータのスケールを揃える必要があります。
すでに述べた通り、主成分分析はデータのばらつきが大きい方向に軸を取り直す手法です。ここで注意すべき点は、ばらつきの比較を定量的に行うため、変数の単位を揃える必要があることです。例えば、変数の単位が長さの場合を考えます。単位(mm)と単位(m)の変数のばらつきの大きさは見え方が同じになるでしょうか。

次元が異なる変数を同時に扱う場合は注意が必要です。上図は、x軸に長さ(mm)の変数、y軸に長さ(m)の変数を取った場合です。同程度にばらついている場合でも、軸のスケールが異なると見え方も異なります。
そのため、各変数のばらつきを同じ価値で扱うために、変数間のスケールを揃える必要があります。
変数間のスケールを揃える方法は様々ありますが、代表的な方法は標準化と呼ばれる手法です。具体的には、平均と標準偏差を揃える手法です。
統計学的には平均は基準で、標準偏差はデータの平均からのばらつき程度を表します。そのため、両者のスケールを揃えることは、統計的な性質を揃えることに相当します。
標準化の定義は次の通りです。

平均からの差を標準偏差で除した操作を各変数それぞれで行うことで、標準化された変数を得ることができます。
pythonでは、scikit-learnを使用することで簡単に標準化を実装できます。StandardScaler()モジュールで標準化のインスタンスを定義し、fit_transform()へ変数Xを渡すと、標準化された結果が返ってきます。
# 標準化 from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_std = scaler.fit_transform(X)
以上で、主成分分析を実行する準備は整いました。
主成分分析の実行
標準化と同様に、scikit-learnで簡単に実装できます。PCA()モジュールでインスタンスを定義し、fit_transform()へ標準化後の変数X_stdを渡すと、主成分分析の結果が返ってきます。算出される主成分の数は、PCA()に渡す引数のn_componentsで指定します。
# PCA from sklearn.decomposition import PCA pca = PCA(n_components=2) X_pca = pca.fit_transform(X_std)
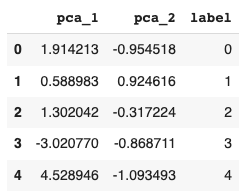
以降で扱いやすくするため、pandasのDataFrame形式へ変換しておきます。次節の可視化の際で使用するため、ラベル情報も追加しておきます。
df_pca = pd.DataFrame(data=X_pca, columns = ['pca_1', 'pca_2']) df_pca['label'] = y df_pca.head()
結果の可視化
最後に結果を可視化してみましょう。正解ラベルで色分けして描画してみます。
fig = plt.figure(figsize=(6, 6)) for i in np.unique(y): pca1 = df_pca['pca_1'][df_pca['label'] == i] pca2 = df_pca['pca_2'][df_pca['label'] == i] plt.scatter(pca1, pca2, label=str(i)) plt.xlabel('PCA 1') plt.ylabel('PCA 2') plt.legend() plt.show()

いかがでしょうか。同じ数字(色)が集まって分布している傾向がみえています。
重要なことなので繰り返しますが、主成分分析では正解ラベルの情報は一切使用していません!正解ラベルの情報なしでデータに潜む構造を捉え、各数字の特徴を反映していると言えます。
以上が、手書き数字の画像データへ主成分分析を適用する実装例でした。今回のように、データにパターンがあることを示すことは重要です。パターンの存在が示唆されることで、分類を目的とした教師あり学習の有効性が期待できます。
まとめ
ここまで主成分分析の概念と実装例を説明してきました。
主成分分析は、多数の特徴量を少数の特徴量で表現する手法で、高次元データを次元圧縮する場合によく使用されます。手書き数字画像データの例のように、64次元データを2次元データに圧縮し、可視化することで数字間にパターンがあることが示唆されました。
主成分分析はシンプルな手法なだけに、応用範囲も広く、様々な分野で活用されています。また、同様な手法で非線形性をより反映した手法に、t-SNEやUMAPがあります。
是非色々と試してみてください。
参考
- https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
- https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
- https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
- https://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html
- https://umap-learn.readthedocs.io/en/latest/
