こんにちは!nakamura(@naka957)です。本記事では、PyCaretで簡単に探索的データ分析を行う方法をご紹介します。
探索的データ分析(Explanatory Data Analysis: EDA)とは、データセットを様々な視点から分析し、データを考察することを目的に行うことです。EDAで得られた知見や仮説を活用し、その後のデータ分析や機械学習モデルの構築を有効に行うことができます。
データを考察するための最も有効な手法は、可視化することです。そのため、データを可視化するスキルはEDAにおいて非常に重要になります。本記事ではEDAを目的とした可視化する方法をご紹介します。
では、早速始めていきます。
- PyCaretとは
- AutoVizとは
- ライブラリのインストール
- 実行の前準備
- EDAの実行
- AutoVizでの実行内容
- eda()の**kwargs引数の指定
- まとめ
- 参考文献
- Appendix: eda(display_format=’svg’)の実行結果
PyCaretとは
PyCaretは人気が高いAutoML(Auto Machine Learning)のPythonライブラリの1つです。オープンソースのため誰でも無料で利用できます。
大きな特徴として、少ないコード行数で、データの前処理から機械学習アルゴリズムの比較・パラメーター調整・実装までを行うことできます。
また、PyCaretには上記以外にも便利な機能が様々実装されており、その1つがEDAを簡単に実行できるeda()関数です。eda()は、データセットを自動で可視化する別ライブラリのAutoVizを呼び出しています。そのため、PyCaretからAutoVizを呼び出すことで、簡単にEDAの実行が可能になっています。
AutoVizとは
AutoVizは1行で自動でデータセットを可視化できるPythonライブラリです。PyCaretと同様にオープンソースのため、誰でも無料で利用できます。
通常、データセットの可視化には相当量のコードを書く必要があります。そのため、EDAの実施にはそれなりの知識と労力が必要です。しかし、AutoVizを用いることで、1行で様々な形式でデータセットを可視化し、確認することができます。
また、AutoVizは変数のタイプ(数値・カテゴリカル・ブーリアン・自然言語)に応じて適切な描画方法を選択し、さらには、複数の描画スタイル(散布図・棒グラフ・密度分布など)で描画してくれます。
以上の内容をわずか1行で実施できるため、素早くデータセットのEDAを行い、データセットに対する理解を深めたい際には非常に威力を発揮するツールです。
ライブラリのインストール
以降で紹介するコード例は、Jupyter Notebook上での実行を想定しています。また、PyCaretとAutoVizのバージョンはそれぞれ以下を想定しています。
pycaret==2.3.6 autoviz==0.1.36
PyCaretのインストールが未実施の人は、事前にインストールが必要です。ただし、通常のインストールでなく、fullモードでのインストールが必要な点に注意してください。fullモードでないと、AutoVizが一緒にインストールされません。
fullモード
$ pip install pycaret[full]
通常モード
$ pip install pycaret
また、ライブラリのバージョンを指定する場合は次の通りです。
$ pip install pycaret[full]==2.3.6
実行の前準備
使用するライブラリを事前に読み込んでおきます。まず、PyCaretのeda()関数を読み込みましょう。
from pycaret.classification import eda
次に、残りのライブラリも読み込みます。
import matplotlib.pyplot as plt %matplotlib inline from pycaret.datasets import get_data from pycaret.classification import setup
ライブラリを事前に読み込んだら、次にデータセットを用意します。PyCaretは様々なデータセットを含んでいます。今回はワインに関するデータセットを使用してみましょう。
データセットはdatasetsモジュール内のget_data関数から読み込めます。get_data関数の引数に’wine’を指定すれば、ワインのデータセットを取得できます。なお、データセットはpandasのDataFrame型で渡されます。
dataset = get_data('wine')

今回は変数typeの赤(red) or 白ワイン(wihite)の分類問題を想定してみます。
PyCaretでは実験環境の設定を最初に行う必要があります。主な目的は次の通りです。
- 目的変数の指定
- 入力変数の型推定結果の確認
- (必要があれば)明示的に変数型を指定
- 乱数シード値の指定(再現性の確保)
今回は目的変数に変数typeを指定し、再現性確保のために乱数シード値に0を渡して実行しましょう。
s = setup(data=dataset, target='type', session_id=0)
EDAの実行
eda()関数を用いて、1行で実行できます。引数のdisplay_formatで表示スタイルを指定でき、主に次のタイプを指定できます。
- ‘bokeh’: ダッシュボードに描画結果を表示
- ‘svg’: 静的な表示
- ‘html’: 結果をhtmlファイルで保存
- ‘server’: 各グラフをWebブラウザで表示
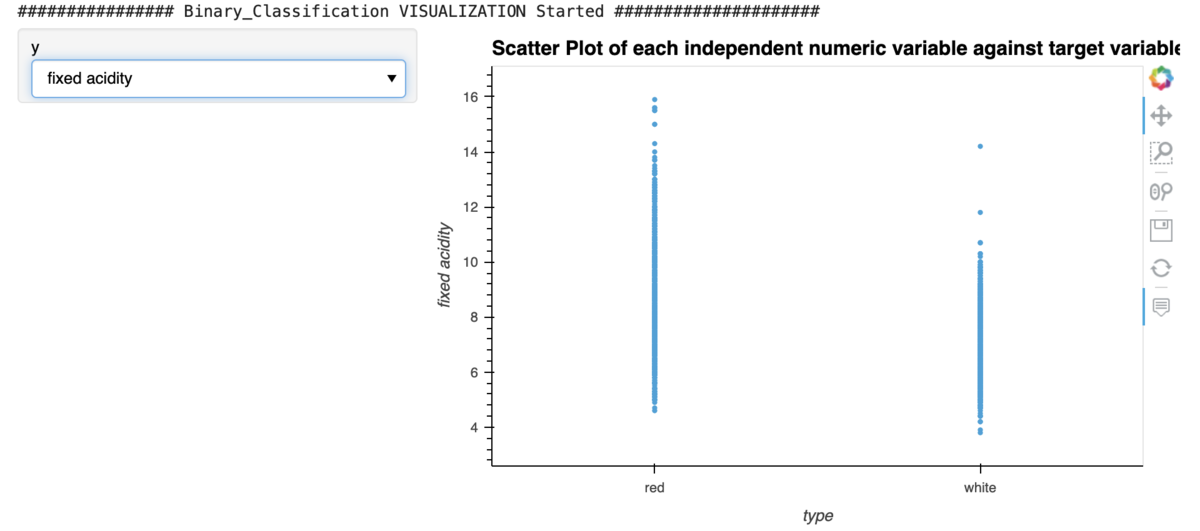
今回はdisplay_format=’bokeh’で実行してみます。この場合、次の1行のみのコード実行でBokehダッシュボードがJupyter Notebook上に作成され、対話的に描画結果を確認することができます。
eda(display_format='bokeh')
描画結果をいくつか以下に列挙します。様々な描画スタイルがあることがわかりますので、是非とも雰囲気を味わってみてください。
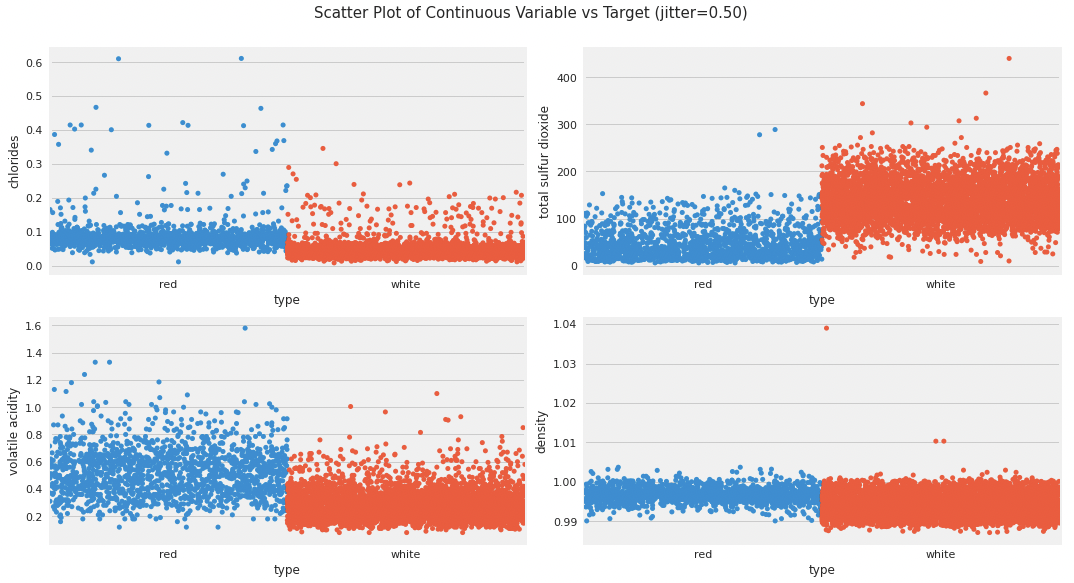
散布図
変数間の相関を散布図で確認できます。
(説明変数 vs 目的変数)
(説明変数 vs 説明変数)

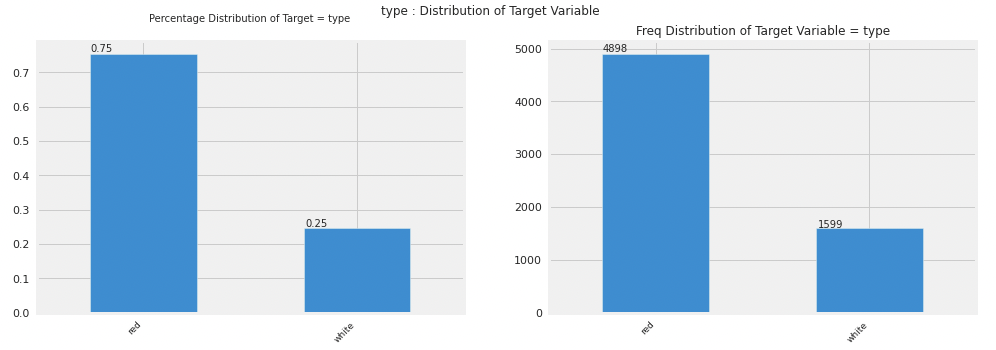
棒グラフ
カテゴリカル変数に対して、変数typeで色分けして棒グラフで表示されています。

密度分布
変数ごとの密度分布です。変数typeで色分けして描画されています。下図は変数alcoholを描画した結果で、変数typeに関して、redよりwhiteでより広い分布であることがわかります。

Violinプロット
各変数の平均値・四分位数・値範囲が確認できます。特に、変数chloridesで中央値や四分位数からの分布が広いことがわかります(外れ値の存在可能性を示唆)。Violinプロットの詳細は、有名なPythonの描画ライブラリであるseabornライブラリのドキュメントなどを参考にしてみてください。

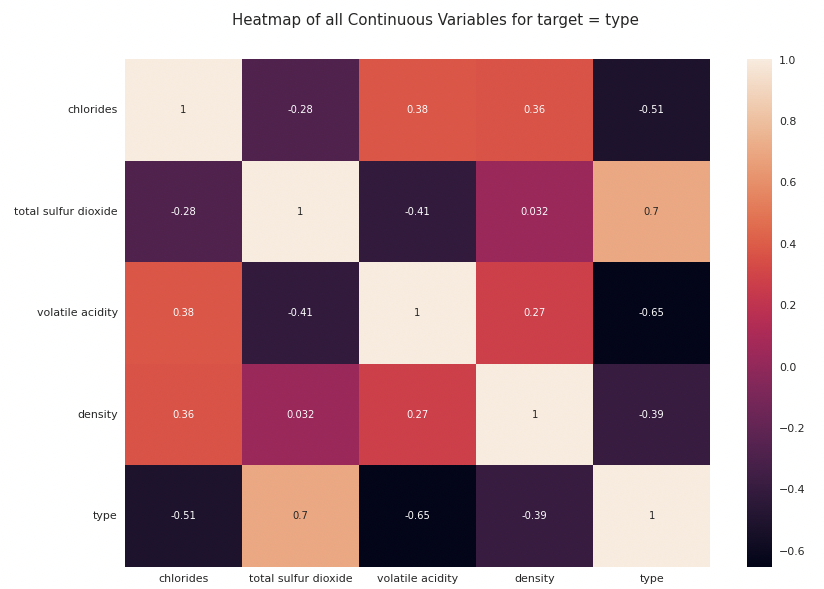
ヒートマップ(相関係数)
変数間の相関係数を可視化することができます。ヒートマップから、変数typeと相関が最も大きいのが変数total sulfur dioxideであることを確認できます。

AutoVizでの実行内容
より深い理解のため、PyCaretのeda()の実行内容を確認しておきます。
eda()では、AutoVizのAutoViz_Class()を定義し、AutoVizメソッドを実行しています。
具体的には、PyCaretでeda()を実行する次のコード
eda( data=None, target=None, display_format="bokeh", # default **kwargs, )
は、AutoVizを用いた次のコードを実行する形になります。
from autoviz.AutoViz_Class import AutoViz_Class AV = AutoViz_Class() AV.AutoViz( filename="", dfte=data, depVar=target, chart_format=display_format, **kwargs, )
PyCaretのeda()の引数で、指定が必要な次の3つの引数data, target, display_formatは、AutoVizの実行時の引数dfte, depVar, chart_formatへそれぞれ渡されます。これらの引数は、データセット(pandasのデータフレーム)、目的変数名(文字列)、表示スタイル(ex. ‘bokeh’, ‘svg’)にそれぞれ対応します。
また、それ以外に**kwargs引数もPyCaretのeda()からAutoVizへ渡すことができ、実行時の詳細な指定が可能です。
eda()の**kwargs引数の指定
eda()の実行時で、より詳細な指定をするために必要な**kwargs引数についてご説明します。
PyCaretのeda()で指定できる**kwargs引数の説明は次の通りです。
- header: int (デフォルト: 0)
- ファイルのヘッダー行の指定
- verbose: int (デフォルト: 0)
- log出力レベル
- 0: 描画結果と一部のメッセージ出力
- 1: 描画結果とより詳細なメッセージ出力
- 2: 描画結果を保存(筆者の動作確認では、display_format = "bokeh"では保存されず、”svg”では保存された結果)
- log出力レベル
- lowess: bool (デフォルト: False)
- 目的変数と連続な説明変数間の回帰直線を表示。ただし、データセットサイズが小さい場合のみ推奨 (筆者の動作確認では、lowness=Trueはdisplay_format = "bokeh"では反映されず、”svg”では反映された結果)
- max_rows_analyzed: int (デフォルト: 150000)
- グラフに表示される最大行数
- max_cols_analyzed: int (デフォルト: 30)
- 分析対象となる変数の最大数
- save_plot_dir: str (デフォルト: None)
- 描画結果の保存フォルダ先の指定
- 指定がない場合、./AutoViz_Plots/ へ保存される。
まとめ
PyCaretによるEDAの実施方法をご紹介しました。eda()関数を用いることで、1行でEDAを実施でき、様々なスタイルで描画結果を確認できます。
また、PyCaretのeda()はAutoVizを呼び出しており、**kwargs引数の指定でより詳細な出力方法を指定できます。
EDAをサクッと行う上で非常に便利な機能ですので、是非試してみてください。
参考文献
- https://github.com/pycaret/pycaret
- https://github.com/bokeh/bokeh
- https://seaborn.pydata.org/generated/seaborn.violinplot.html
- https://github.com/AutoViML/AutoViz
Appendix: eda(display_format=’svg’)の実行結果
PyCaretのeda()関数において、表示スタイルの引数 display_format=’svg’での実行結果を参考までにご紹介します。svgスタイルは対話的なダッシュボードでなく、静的な結果が得られます。
ただし、全ての変数を分析対象とした場合、出力ファイルサイズが大きくなります。そのため、以下では、**kwargs引数で max_cols_analyzedx=4 とし、分析対象の変数を4つに限定します。
eda(display_format='svg', lowess=True, max_cols_analyzed=4, verbose=1)