
こんにちは!
皆さんはAutoMLと呼ばれるツールをご存じでしょうか?AutoMLは機械学習の面倒なデータ処理からモデルの選定、実際に学習を行って予測値を算出するまでを自動で行ってくれる便利なツールです。
今回はその中でもDartsというAutoMLを紹介します。
Dartsとは
Dartsは少ないコードで機械学習を実行でき、時系列の分析に長けたPythonのライブラリです。前述したようにこちらもAutoMLの一つで前処理から予測値の算出までを自動で行ってくれます。
Darts内には豊富なモデルが実装されており、ARIMAのような標準的な時系列モデルからRNNのような深層学習を使っての学習も可能です。公式ドキュメントは下記URLをご確認ください。
Time Series Made Easy in Python — darts documentation
時系列分析とは?
言葉通り時間の流れとともに変化するデータを分析することです。
例えば、『過去数年間の毎日の気温の記録』などを指します。時系列分析において難解になる点が、通常の機械学習ではデータのそれぞれが独立して存在しているのに対し、時系列分析では過去のデータと未来のデータに順序があることです。学習をするときはこの順序を保つことが重要です。
また、時系列データは24時間や1年などの一定の周期で似たような動きを持つことが多いです。例えば、夏は暑いからアイスが売れるけど冬場にはアイスの売れ行きが落ち、そしてまた春夏になるにつれ売り上げが伸びていきます。
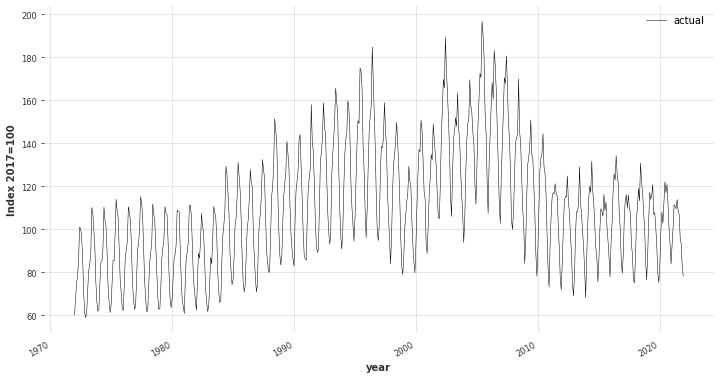
アメリカでのアイスクリームの生産量の推移(2017年を100とした割合
アメリカのアイスクリームの時系列データを可視化してみました。画像のように大きく上下動を繰り返しながら推移しており、1990年代半ばまでの大きなスパンで見ると右肩上がりになっています。売り上げが下がった時に時期的な影響なのか、その他の要因なのかを判別することが難しいです。上記の例で予測を行うときアイスのみの生産量を説明変数にとるので単変量の時系列と言われます。
ここに、例えばコーラのような清涼飲料水の売り上げもデータをとって二つ以上の説明変数からアイスの生産量を予測しようとするのは多変量の時系列と言われます。
Dartsでは単変量も多変量も双方の分析が可能です。
Dartsの強み
AutoMLには有名なものでPyCaretやAuto-sklearn、AutoGluonなどがありますが、こういったものと比較してDartsは一貫して時系列の取り扱いに特化したライブラリとなっています。
時系列を使える他のAutoMLと比較しても、Dartsのみが過去共変量と未来共変量の取り扱いを明示的にサポートしています。(2022/3現在)
共変量とは分析のテーマとは異なるところにある既知の事実を指します。
例えば、川の流量を計測したいときに明日が雨になると予報されたとしましょう。すると単純な時間推移の他に『雨で流量が増える』という外部の要因を加えて予測を行うことができます。この天気予報のような説明変数とは別の変数で目的変数に影響を与えるものを、共変量と呼んでいます。
今回の場合は未来に対して作用するので未来共変量です。Dartsでは、このような共変量を設定しての学習を行うことができます。
Darts内のモデルを覗く
以下にDartsに組み込まれているモデルを列挙します。
- ARIMA
- Auto-ARIMA
- Baseline Models
- Block Recurrent Neural Networks
- Exponential Smoothing
- Fast Fourier Transform
- LightGBM Model
- Linear Regression model
- N-BEATS
- Facebook Prophet
- Random Forest
- Regression ensemble model
- Regression Model
- Recurrent Neural Networks
- Temporal Convolutional Network
- Temporal Fusion Transformer (TFT)
- Theta Method
- Transformer Model
- VARIMA
上記に挙げた全てを解説するのは相当量のボリュームとなってしまうため、今回は時系列分析において長年親しまれているARIMA、波形の分析においてよく用いられるFast Fourier Transform、Facebookも取り入れている実用的なFacebook Prophet、ディープラーニングの一種であるRecurrent Neural Networksの解説をします。
それぞれのモデルに対し本稿では簡単な導入にとどめます。Darts内のモデルをなんとなく理解することで、表面上だけでなく少し踏み込んでDartsがどのような分析を行っているか理解することが目的です。
ARIMA
ARとMAモデルを組み合わせたARMAモデルを非定常過程に適合できるように、和分でとったものがARIMAとなります。専門用語の羅列となってしまったので一つ一つ整理します。
ARモデル(autoregressive)
日本語では自己回帰モデルと呼ばれています。ある地点を目的変数として、それより過去の値を説明変数にとって回帰をすることです。このモデルでは過去の値によって未来の値を予測できるということを表しています。
MAモデル(moving average)
日本語では移動平均モデルと呼ばれています。ある地点から過去を見て一定区間の平均値を取ります。平均値をとって点を打っていくと図のように大まかな推移が見て取れます。

上記の図は導入で触れたアイスクリームのグラフにmoving averageを追加してみたものです。
非定常過程
ざっくり言えば時系列データに一定の規則性があるときのことを定常過程といいます。定常過程をイメージすると同じ値の周りを同じような大きさで上下に行き来している感じです。
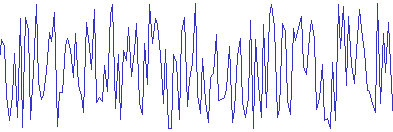
上記が定常過程の例であるホワイトノイズです。定常過程である例は非常に少なく、ホワイトノイズ程度しかありません。上記の波形は一見バラつきがあるようにも見えますが、これがどれだけ右に伸ばしても突出した振幅も出さず延々と似たような波形を示します。
このように常に同じような動きをするのが定常過程です。非定常過程は、これに当てはまらないものでよく非定常過程の例に上がるのが株価です。Google Finenceより1年間のapple株価の推移を見てみましょう。
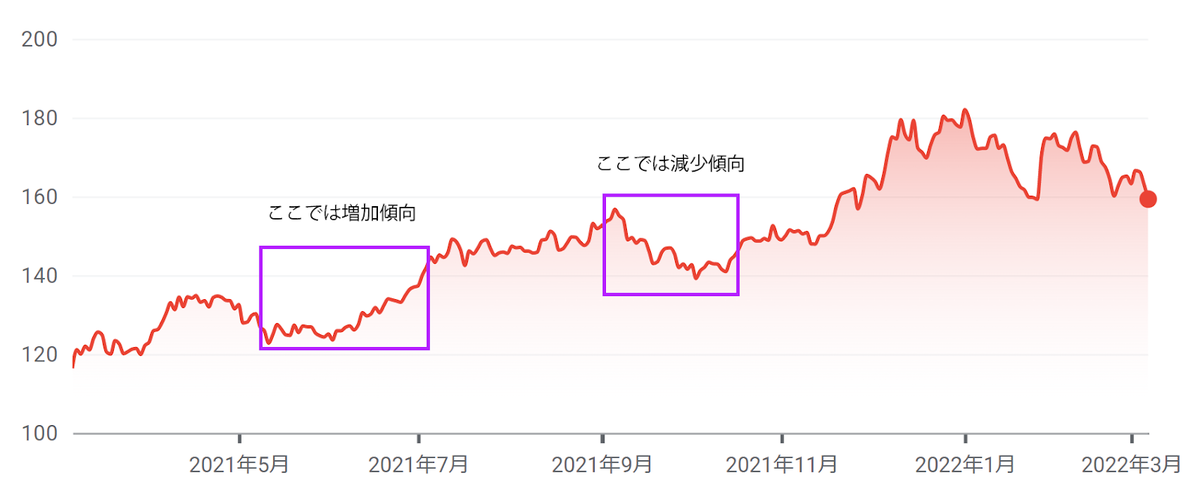
Apple Inc (AAPL) Stock Price & News - Google Finance (2022/03より過去一年間)
画像のように株価は細かく上下動を繰り返しています。ある時は上昇したり、ある時は急落したりとその場その場で動き方に特徴を持っています。これをトレンドと言って非定常過程では期間によってトレンドを持つことがあるというのがひとつの特徴でしょう。
まとめるとARIMAモデルとは回帰と平均を組み合わせたモデル
更に、様々な時系列データに適用できるように工夫したモデルです。
Fast Fourier Transform
日本語で『高速フーリエ変換』です。言葉の通り、フーリエ変換を高速化したモデルですが肝心なフーリエ変換が難解です。
時系列データを可視化した時に見られる波のような不規則な線形を、規則性のあるsin関数(三角関数)の組み合わせにとらえ、それらのsin関数に分割します。その分割したsin関数の振幅などを合計して統計を取ることがフーリエ変換です。
フーリエ変換では不規則な線形に規則性を見出して特徴量に変換することで時系列データの分析を行います。言葉ではわかりにくいと思いますのでwikipediaにわかりやすいアニメーションがあったので掲載します。
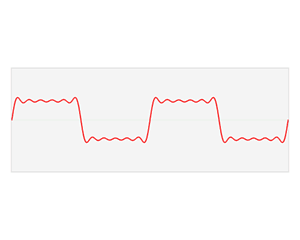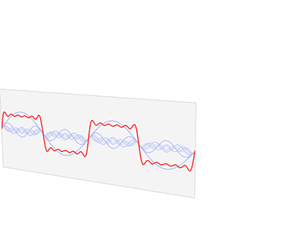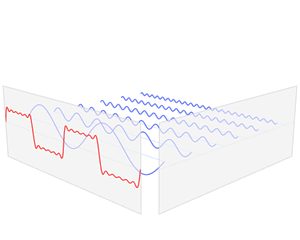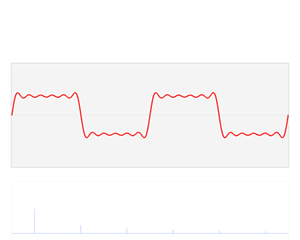
アニメーションそのものはフーリエ級数展開と呼ばれるものですが、フーリエ変換と概ね同じような処理をしていると考えて構いません。フーリエ級数展開の発展形がフーリエ変換で、簡単に説明するとフーリエ級数展開は一定区間の波形に対して三角関数に分解することで、フーリエ変換はその区間を限定せず無限に続く波形を分析することです。
Prophet
月や週などの季節性に加えて休日の影響などを検出し、それらを組み合わせた加法モデルによって予測値を算出します。加法モデルについてざっくり説明すると、特定のルールに基づいて算出した指標をそれぞれ合算することです。
Prophetでは単なる分析にとどまらず欠損値や外れ値の扱いにも長けており、前処理に注意せずとも簡単にモデルを作成して予測値を算出可能です。Facebookの多くのアプリケーションで使用されているという実績もあります。
本稿ではメインのDartsの解説と反れるので簡単な導入にとどめましたが、興味がある方は公式ドキュメントをご覧ください。
RNN
通常のデータ解析は沢山のデータがあり、データそのものは1つ1つがそれぞれ独立しています。時系列データではこれらが独立しているのではなく、過去のデータから未来のデータに影響を与えています。この未来から過去への順序を乱すことなく深層学習を行うために作成された手法がRNNです。
RNNではある層での出力を次の層の出力に使うのみではなく、時系列のデータポイントとしても入力することで分析を進めていきます。時間の流れの中に順序を崩さないよう予測値を入れ込みながら、最終的な予測値を算出するイメージです。
まとめ
Dartsは時系列の分析に特化しており簡単に分析を行うことが可能です。さらに本稿で解説したような様々なモデルにデータセットを当てはめて、評価指標からどのモデルでの分析が最適かを自動で検出してくれます。
実践編では、時系列で上げたアイスクリームの生産量をデータセットとして実際にDartsを動かしてみましょう。モデルごとの予測値の違いや、前処理や評価指標といった機械学習における重要な部分がどう処理されているのかに触れていきます。
