
こんにちは!nakamura(@naka957)です。今回は機械学習モデルの解釈するために有用な手法であるSHAPをご紹介します。モデル解釈はデータ分析や機械学習の活用において重要な内容ですので、興味がある方は是非参考にしてみてください。
SHAPとは
SHAP(SHapley Additive exPlanations)は、機械学習モデルを解釈するのに便利な手法です。モデルの予測に対し、特徴量(説明変数)の寄与度を定量的に算出できます。また、モデルのアルゴリズムの種類(決定木・線形回帰など)に限定されません。様々な場面で使用できる点からも人気の高い手法です。
今回は機械学習モデルの中でも決定木ベースのXGBoostを例に、SHAPを用いた機械学習モデルの解釈方法をご紹介します。
では早速、本題に入っていきましょう。
機械学習モデルの準備
最初にデータセットを準備します。SHAPライブラリー自身にもデータセットが含まれていますが、今回はscikit-learnライブラリに含まれるカリフォルニア住宅価格のデータセットを使用します。
データセットはsklearn.datasetsモジュール内のfetch_california_housing()から取得できます。”dataset”の変数名で取得したデータセットのインスタンスから、使用するデータ(説明変数、目的変数、変数名など)を取り出すことができます。
import pandas as pd from sklearn.datasets import fetch_california_housing dataset = fetch_california_housing() X = pd.DataFrame(dataset.data, columns=dataset.feature_names) y = dataset.target
データセットに関する説明は次の通りです。
- fetch_california_housing: カリフォルニア住宅価格データセット
- .data: 説明変数データ
- .feature_names: 説明変数名
- .target: 目的変数データ
- .DESCR: データセットの説明
次に、XGBoostのモデルを作成します。モデルインスタンスを作成後、データセットを渡し、訓練させます。
import xgboost
model = xgboost.XGBRegressor()
model.fit(X, y)
これで学習済みの機械学習モデルが準備できました!
次に、SHAP値の算出とグラフの描画を行っていきます。
SHAP値の算出
SHAPライブラリを読み込みます。
import shap
次に、SHAP値を算出します。訓練済みのモデルと説明変数から算出できます。
必要なステップは次の2つです。
- モデルをshap.Explainer()に渡す
- 説明変数(特徴量)を渡す
# 1. モデル shap.Explainer()に渡す explainer = shap.Explainer(model) # 2. 説明変数(特徴量)を渡す shap_values = explainer(X)
算出されたSHAP値はshap_valuesに格納されています。以降では、算出したSHAP値を描画していきます。
今回は、SHAP値の描画スタイルの中で頻繁に使用される、次の3種類をご紹介します。
- waterfallプロット
- beeswarmプロット
- scatterプロット
waterfallプロット
1つ目はwaterfallプロットです。
予測に対する説明変数の寄与度を、各データごとで確認できます。そのため、各データごとに確認できる特徴を活かして、教師データから大きく外れた予測の原因調査に有効です。下図の例では訓練データの1番目の結果を出力しています。
shap.plots.waterfall(shap_values[0]) # 1番目のデータを描画
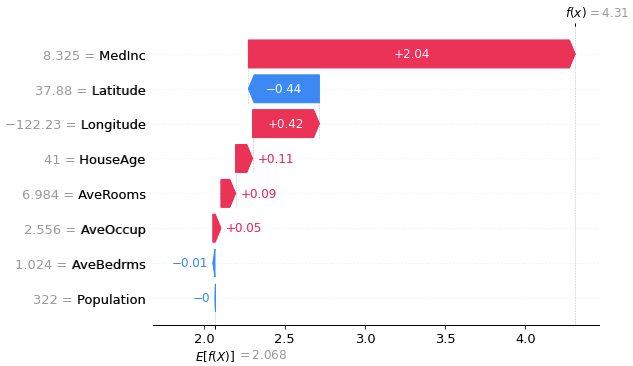
グラフの見方を説明します。
横軸のE[f(x)] = 2.068は、訓練データに対するモデルの予測結果の平均値です。この平均値を基準として、各説明変数の寄与度を算出しています。
上図のデータの予測結果はf(x) = 4.31になります。基準のE[f(x)] = 2.068から予測結果f(x) = 4.31までの寄与度を、各説明変数ごとで赤色と青色の帯で表しています。赤色は正値へ、青色は負値へそれぞれ寄与することを意味します。
色分けした帯を用いることで、視覚的に重要な説明変数と、その寄与度を把握できます。例えば、上図の場合、正および負値へ最も寄与した説明変数はそれぞれ”MedInc”と”Latitude”で、
- MedInc:収入の中央値
- Latitude:緯度
が住宅価格への影響が大きいことを示唆しています。
beeswarmプロット
2つ目はbeeswarmプロットです。
shap.plots.beeswarm(shap_values)
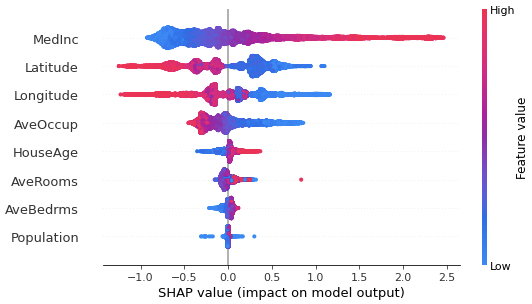
全データサンプルに対して、説明変数ごとにSHAP値をプロットしたグラフです。見方のポイントは、SHAP値を示す横軸のグラフとして見る点です。SHAP値が大きい程、予測結果への寄与度も大きいと考えられるため、横軸の分布が広い説明変数が重要と解釈できます。
注意点として、各プロットの色は説明変数自身の値の大きさを反映しており、SHAP値とは関係ありません。説明変数値の尺度はグラフ右側の軸に示されており、青色から赤色の変化で値が大きくなることを表します。
beeswarmプロットの特徴は、説明変数の重要度(横軸方向分布)と説明変数値の相関が視覚的に表される点です。
再度、寄与度が大きい”MedInc”と”Latitude”の説明変数に着目してみます。まず、MedIncの値が大きい程、SHAP値も大きい傾向です。これは、収入の中央値と住宅価格が正の相関を意味します。一方で、Latitudeが大きい程、SHAP値は小さい傾向です。すなわち、緯度と住宅価格は逆相関の傾向です。この分析結果から、高収入世帯の地域に加えて、南部の地域で住宅価格が高い傾向が読み取れます。
上記の分析だけでは、南部地域で住宅価格が高い理由を断定はできません。ただし、推測として、ビバリーヒルズも位置するロサンゼルスが南部地域である点が要因の1つと推測されます。また、データセットが1990年の国勢調査時のものであり、当時のサンフランシスコでは現在の巨大企業(GAFAMなど)が集結していなかったから点が2つ目に挙げられます。
実際のビジネス現場でも、データ分析結果の考察から仮説の立案に繋げ、また別の切り口から分析することは頻繁にあります。そのための道具として、SHAPが有効と実感頂けましたら、嬉しい限りです。
ここで、beeswarmプロットに関連し、SHAP値の絶対値平均をとるグラフを下図にご紹介します。絶対値平均を取るため、正値のみの棒グラフで表されます。そのため、特徴量の影響度が一目でわかります。
shap.plots.bar(shap_values)
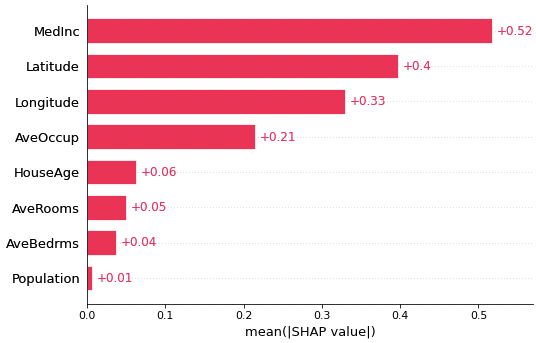
棒グラフの形式で直感的に理解できる一方で、予測値に対して正と負どちらに寄与したかはわかりません。そのため、beeswarmプロットに比べ、情報量が少ないです。
scatterプロット
3つ目はscatterプロットです。
shap.plots.scatter(shap_values[:, 'MedInc'], color=shap_values)
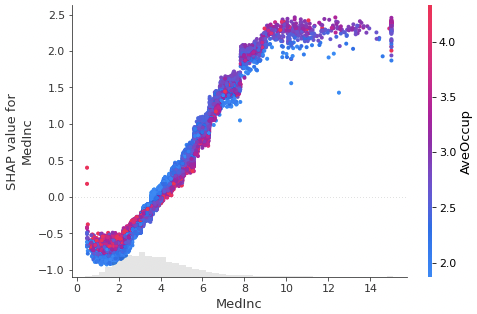
横軸に1つの説明変数、縦軸にSHAP値をそれぞれ取るグラフです。大きな特徴に、交互作用が存在する可能性を推定できる点があります。
1つ目のwaterfallプロットでも述べましたが、SHAP値は平均値を基準とした予測値の寄与度を反映しています。そのため、横軸固定でみた際で、縦軸(SHAP値)に分布の広がりがある場合は、他の説明変数の影響を示唆します。グラフ横軸の説明変数と線形関係でないことを意味するため、交互作用が存在する可能性が示唆されます。
ただし、実際に交互作用が存在するかは、様々な観点から判断する必要がある点に注意してください。
まとめ
ここまでSHAPの代表的な描画スタイルを紹介しました。紹介した種類以外にも、様々な描画スタイルがあります。
描画スタイルの種類で得られる情報も異なるため、是非色々と試してみてください!
参考文献
