
こんにちは!nakamura(@naka957)です。今回は少ないコードで機械学習を簡単に実装できるPyCaretをご紹介します。
PyCaretとは
PyCaretはAutoML(Auto Machine Learning)を簡単に行えるPythonライブラリです。オープンソースのため誰でも無料で利用できます。
大きな特徴として、少ないコード行数で多数の機械学習アルゴリズムを比較できることが挙げられます。そのため、この機能を用いて最適な機械学習アルゴリズムの検討・選択・実装のサイクルを簡単かつ迅速に行うことが可能です。
本記事では回帰分析を例に、PyCaretを用いた機械学習モデルの検討・選択・実装、そして未知データの予測までをご紹介します。
また、以降で紹介するコードはJupyter Notebook上での実行を想定しています。また、PyCaretはバージョン 2.3.6で実装しています。
では早速、本題に入っていきましょう。
実装プロセスの全体像
PyCaretを用いた実装プロセスは、次のステップ順で行います。
- データセットの準備
- 実験環境の設定
- 機械学習モデルの比較・定義
- ハイパーパラメーター調整
- 未知データの予測
最初に本記事で使用するライブラリを読み込みましょう。
PyCaretには回帰分析用のモジュールが用意されています。25個以上の回帰アルゴリズムが実装されており、加えて、ハイパーパラメータ調整、アンサンブル、スタッキングの機能もあります。今回は全機能を事前に読み込みこんでおきます。
from pycaret.regression import *
データセットの準備
データセットを用意します。PyCaretはすでに様々なデータセットが含まれているため、その中のダイヤモンド価格予測のデータセットを使用してみます。
データセットはdatasetモジュール内のget_data関数から読み込めます。get_data関数の引数に’diamond’を指定すれば、ダイヤモンド価格予測のデータセットを取得できます。なお、データセットはpandasのDataFrame型です。
from pycaret.datasets import get_data dataset = get_data('diamond')
データセットの各列の説明は次の通りです。
- Carat Weight: カラット単位の重量(1 carat = 0.2 g)
- Cut: 5段階のカット性評価
- Color: 6段階の色性評価
- Clarity: 7段階の透明度評価
- Polish: 4段階の磨き度評価
- Symmetry: 4段階の対称性評価
- Report: 品質等級評価機関による2段階評価(“AGSL” or “GIA”)
- Price: USD単位での価格
ここで、モデルの最終的な精度評価のために、データセットの一部を分割しておきます。今回は1割をテスト検証用に残しておきましょう。
# 9:1比率で訓練と検証にデータをサンプリング train_df = dataset.sample(frac=0.9, random_state=0) test_df = dataset.drop(train_df.index) # indexを再設定 train_df.reset_index(drop=True, inplace=True) test_df.reset_index(drop=True, inplace=True) # データ数を確認 print('(Number of data)') print(f'total: {dataset.shape[0]}') print(f'training: {train_df.shape[0]}') print(f'test: {test_df.shape[0]}')
実験環境の設定
PyCaretでは実験環境の設定を最初に行う必要があります。主な目的は次の通りです。
- 目的変数の指定
- 入力変数の型推定結果の確認
- (必要があれば)明示的に変数型を指定
- 乱数シード値の指定(再現性の確保)
s = setup(
data = train_df,
target = 'Price',
transform_target = False, # 目的変数に対する box-cox transformation
log_experiment = False, # 実験結果の記録
experiment_name = 'diamond', # 実験記録の名前
categorical_features = [], # カテゴリカル変数列を指定
numeric_features = [], # 数値変数列を指定
session_id = 0
)
PyCaretは自動で入力変数の型を推定してくれます。推定結果が異なる場合は、カテゴリカル変数もしくは数値変数として明示的に指定し、再度実行すれば反映されます。
機械学習モデルの検討・定義
複数の回帰アルゴリズムを一度に比較し、結果を踏まえてモデル定義を行います。
回帰アルゴリズムの比較は、compare_model関数で行います。返り値は精度が上位のモデルインスタンスです。返り値のモデル数は引数n_selectで指定できます。その他に、比較の際の評価指標やクロスバリデーションのフォールド数、検討時に除外するアルゴリズムも引数sort, fold, excludeでそれぞれ指定可能です。
それ以外の引数は公式ドキュメントを参照してみてください。
では、実際に比較してみましょう。たった1行で様々なアルゴリズムを比較できます!
best_models = compare_models( n_select = 1, # 上記"n_select"個のモデルを返す sort = 'RMSE', # ソート順の評価メトリック, default = 'R2' fold = 4, # Cross Validationのfold数 exclude = ['lar', 'dummy', 'en', 'ada', 'omp', 'par', 'huber'], # モデル評価から除外するアルゴリズム名を指定 )
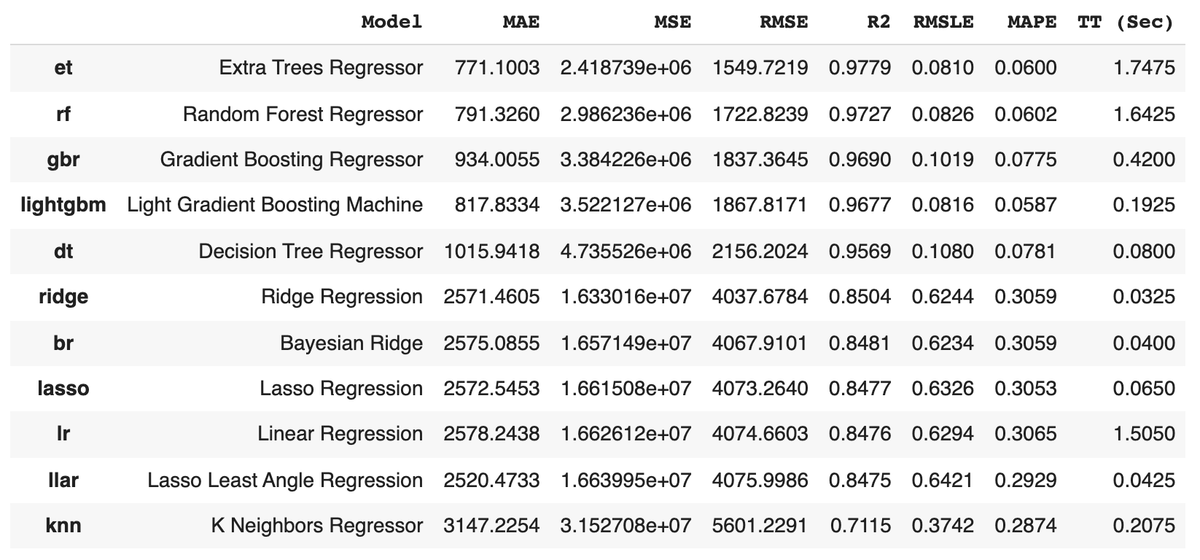
次に、モデル定義を行います。compare_model関数の返り値 best_modelでも構わないですが、汎用性も踏まえ、アルゴリズムを直接指定する方法をご紹介します。
精度指標RMSEで精度が最も良かったExtra Trees Regressor(et)を採用します。
モデル定義にはcreate_model関数を使用します。最初の引数にアルゴリズム名を指定します。また、クロスバリデーション(CV: Cross Validation)の実施有無と、フォールド数も指定します。
et = create_model( 'et', # アルゴリズム名を指定 cross_validation = True, # CVの実施有無 fold = 4, # CVのfold数 )

ハイパーパラメーター調整
次に、定義したモデルのハイパーパラメーターを調整しましょう。tune_model関数で簡単に調整できます。引数には、モデルインスタンスと評価指標、クロスバリエーションのフォールド数を指定します。
なお、調整アルゴリズムはグリッドサーチ法が使用されています。
tuned_model = tune_model( et, # モデルインスタンスを指定 optimize = 'RMSE', # 評価指標 fold = 4, # CVのfold数 )

以上が、モデル定義からハイパーパラメーター調整までの流れです。
非常に少ない行数で実行可能なことがわかって頂けたかと思います!
未知データの予測
未知データを予測する前に、最終モデルをfinal_model関数で定義します。
predict_model関数で最終的な精度を確認できます。
predict_model(final_model)

未知データの予測は、predict_model関数の引数dataに未知データを渡すことで予測できます。テスト用データtest_dfを渡しましょう。予測結果は’Label’列になります。
pred = predict_model(final_model, data = test_df)
pred.head() # "Label"列が予測結果
 予測結果と教師データのR2値を確認しておきます。PyCaretのutilsモジュールのcheck_metric関数に’R2’を指定すれば、算出することが可能です。
予測結果と教師データのR2値を確認しておきます。PyCaretのutilsモジュールのcheck_metric関数に’R2’を指定すれば、算出することが可能です。
from pycaret.utils import check_metric r2 = check_metric(pred['Price'], pred['Label'], 'R2') print(f"R2: {r2}") # R2: 0.9808
まとめ
PyCaretによる回帰分析の一連の流れをご紹介しました。アルゴリズム比較、ハイパーパラメーター調整、未知データ予測の一連の流れを、非常に少ないコード行数で実装できることを体感頂いたと思います。
次回は、今回実装したモデルを用いた結果の描画方法をご紹介します。PyCaretでデータ分析が簡単にできることを体験頂けると思います!
続きはコチラ
AutoMLライブラリPyCaretを使ってみた 〜結果の描画〜
参考文献
- Introduction to Regression in Python with PyCaret (https://towardsdatascience.com/introduction-to-regression-in-python-with-pycaret-d6150b540fc4)
- PyCaret 101 — for beginners (https://medium.com/analytics-vidhya/pycaret-101-for-beginners-27d9aefd34c5)
