
こんにちは!
皆さんはXGBoostとLightGBMの二つをご存じですか?
機械学習をやっている方は聞き慣れているフレームワークだと思いますが、
両者の違いを正しく理解できているでしょうか。
今回はこの二つのフレームワークの違いを解説していきます。
結論から話すと、XGBoostではLevel-wiseという決定木の作成方法を用いており、LightGBMではLeaf-wiseを用いています。Leaf-wiseでは決定木の分岐が少ないためそれを活用したLightGBMでは高速な計算が可能になります。
GBDTの計算手順を復習してから、両者の違いを理解していきましょう。
勾配ブースティング決定木とは
まずはベースとしてこれらのライブラリが何を行っているのか理解しなければいけません。
XGBoostとLightGBMも勾配ブースティング決定木(以下GBDT)を基にしたフレームワークです。
本段落ではGBDTについての解説をします。
GBDTは勾配降下法とアンサンブル学習と決定木の3つの計算手法を合わせたものです。
このアルゴリズムは非常に強力で、KaggleのようなデータサイエンスのコンペではGBDTを用いた計算モデルがハイスコアを叩き出した前例が何度もありました。
データサイエンティストとしては是非とも押さえておきたい手法でしょう。
Optiver Realized Volatility PredictionではLightGBMをアンサンブル学習に活用して2位を受賞しています。
1st place (public 2nd place) solution
Home Credit Default RiskではLightGBMで7位のスコアを出しています。
LightGBM 7th place solution
決定木
木構造の条件分岐を繰り返すことでサンプルの分類をします。

例としてアイスクリームを購入する確率を表にしてみました。
段階ごとに2パターン(厳密にはTrue/False)のカテゴリに振り分けて全てのデータを分類していきます。
表のように、振り分けたものを図にすると、木のように見えることから決定木と呼ばれています。
一見、分類問題でしか使えないように見えますが、回帰木という回帰問題に適応できる決定木の種類があり、回帰問題へも対応できます。
ちなみにGBDTの場合、分類問題でも回帰木を扱って予測値は確率として算出します。
アンサンブル学習
言葉が異なるのでまぎらわしいですが、勾配ブースティング決定木のブースティングとはアンサンブル学習のことを指します。
アンサンブル学習は、複数のモデルを組み合わせて新たにモデルを作ることを意味します。
三人寄れば文殊の知恵ということわざのように、数人でアイディアを出しあうことでより良いものが生まれるという考え方です。モデルの苦手な部分を補ったり得意分野をより強固にしたりなどモデルの組み合わせで様々な期待が出来ます。
GBDTでは勾配降下法と決定木をアンサンブル学習しており、決定木で算出した予測値と目的変数の誤差を勾配降下法を用いて誤差を埋めるように学習を進めていきます。
勾配降下法
勾配法とは関数を最小にする変数の値を求めることです。
- 初期位置にするxを決めて、x地点の傾きを求めます。
- その傾きと任意で設定した学習率から次の探索地を求めます。
(学習率とは任意で定めた、一度の計算で次の探索地まで移動する量です。) - 求めた探索地の傾きを求めます。
- 2,3を繰り返すと最終的に傾きは0になります。
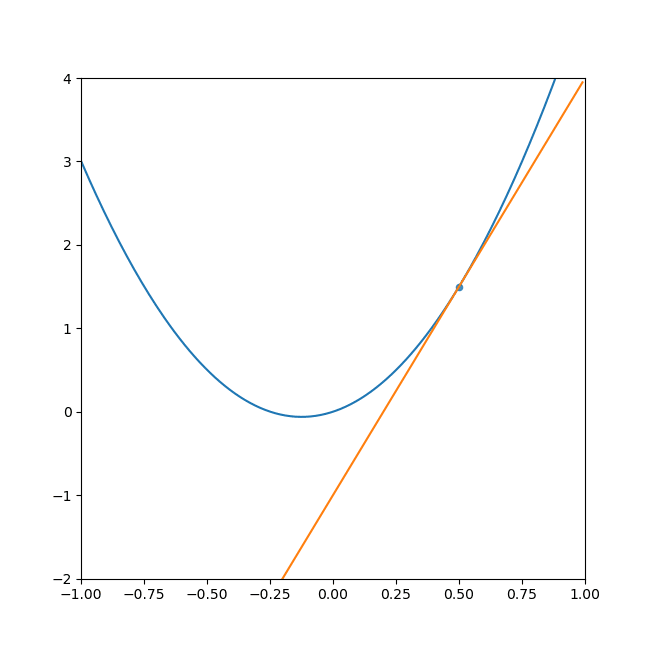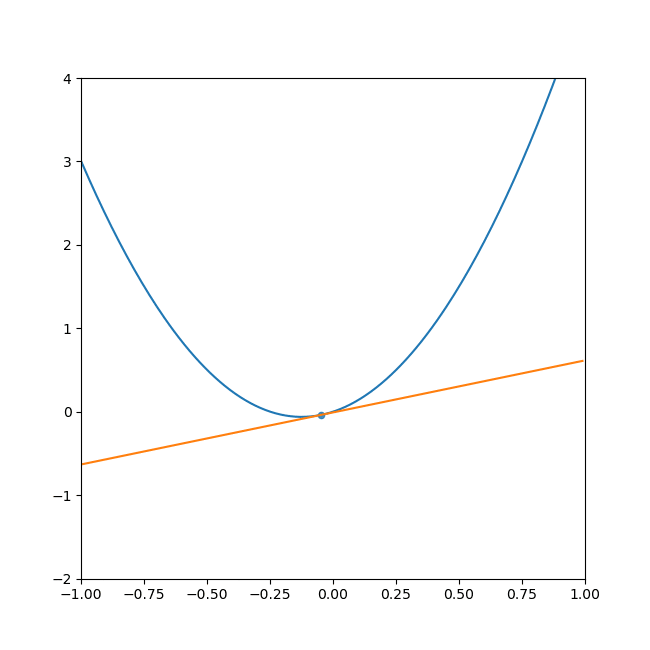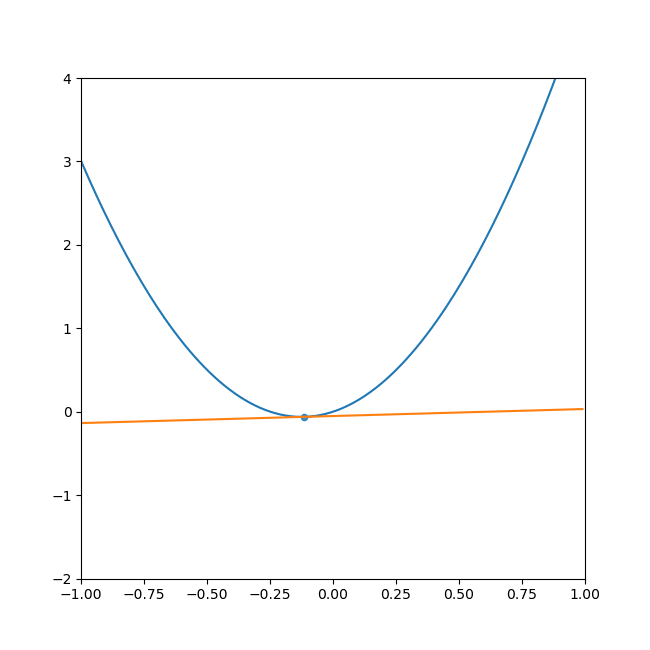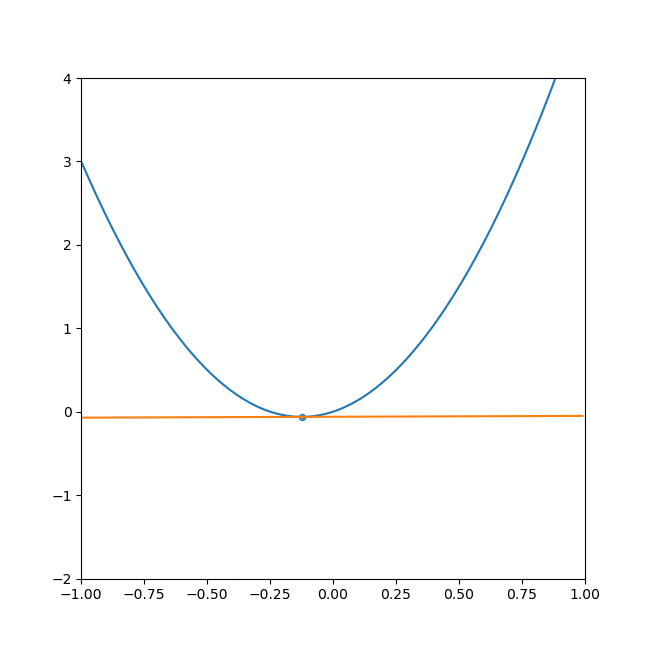
言葉で説明しても分かりにくいと思うので、GIFを添付します。
ご覧の通り、最終的に落ち着くのは水平な線(傾きがゼロ)で最小値を取っています。
GBDTではこの勾配降下法を用いて決定木で得た結果の誤差を学習を繰り返す度に小さくしていきます。
GBDTの計算手順
メインの計算は決定木が担当しています。
- 決定木を作成して、初期の予測値を算出する。
- 予測値と目的変数の誤差を算出する。
- 予測値と目的変数の誤差を勾配降下法を用いて小さくするように新しい決定木を作成する。
- 3の手順で指定した数だけ決定木の作成を繰り返す。
- 予測対象のデータがそれぞれの決定木で属する葉のウェイトの和が予測値となる。
本稿ではXGBoostとLightGBMの相違点に着目したいため細かい計算は割愛させていただきます。
XGBoostとLightBGMの異なる点
大まかな違いを表に起こします。
| XGBoost | LightGBM | |
| スポンサー | NVIDIA,Intel等 | Microsoft |
| 設計思想 | GBDTの先駆け | 軽量化を目指した設計 |
| 学習の傾向 | 深さ優先 | 幅優先 |
| デメリット | 計算が遅い | 過学習しやすい |
機械学習上で最も重要な相違点が傾向の項目です。
XGBoostではLevel-wiseを採用しており、LightGBMではLeaf-wiseです。
Level-wise
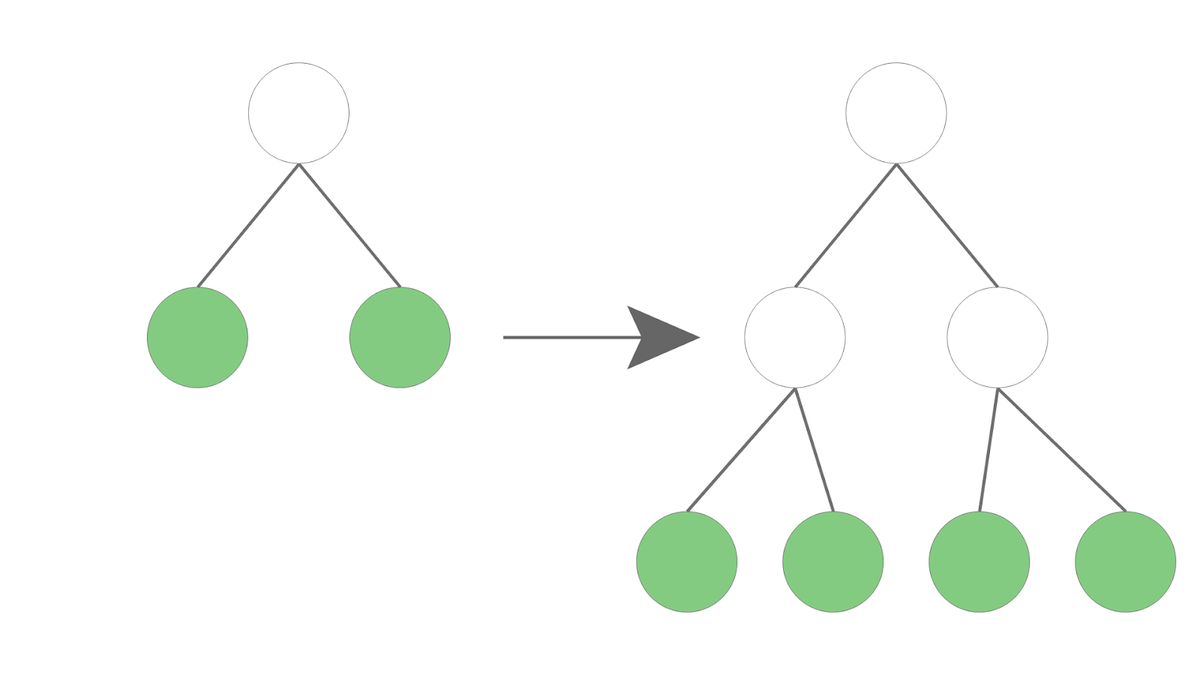
Level-wiseでは、決定木を階層ごとに分岐させていきます。
画像のように深さが一段階増えるごとに全ての葉を分岐させていきます。
深さに準じて葉が増えることから、深さ優先での探索と言われています。
Leaf-wise
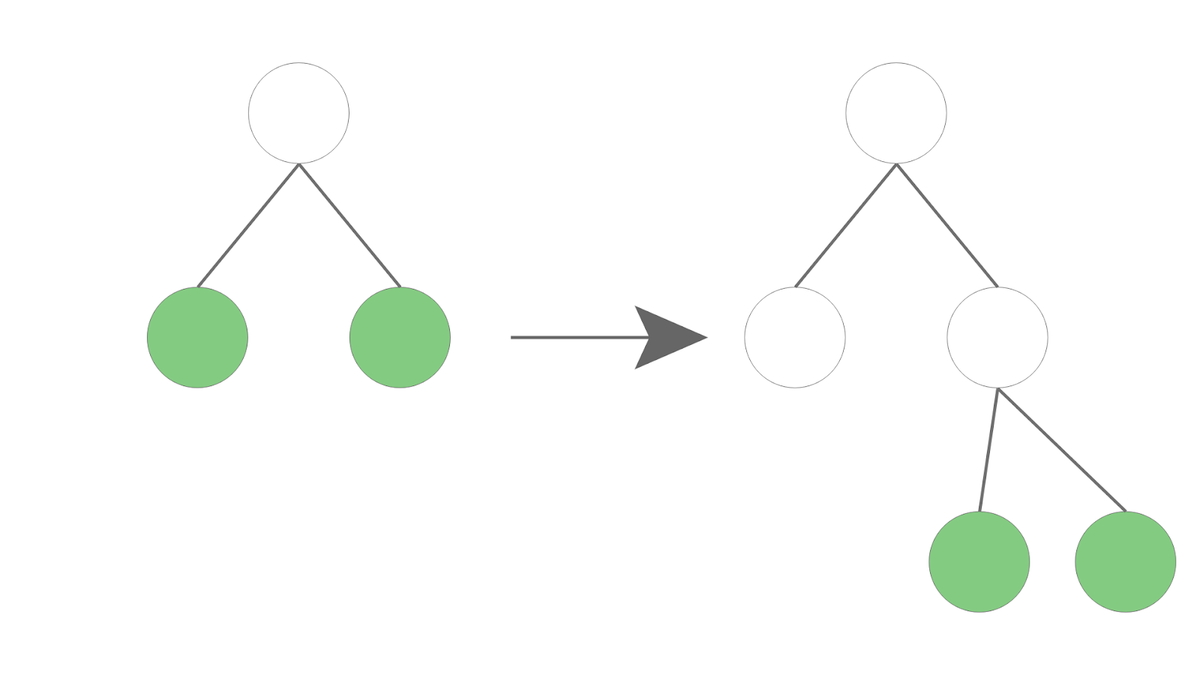
Leaf-wiseではLevel-wiseでの探索より計算量を減らすことを目的にしています。
画像の通り、Level-wiseに比べて分岐点が少ないです。
なぜこのようなことが可能になるのかというと、ジニ不純度を計算して情報利得の大きいものに分岐をしているからです。
ジニ不純度は、ターゲットがどれだけ分類できていないかを表しています。
情報利得とは親ノードと子ノードのジニ係数の差です。
情報利得が大きいということは効率的に分類が進んでいると言えます。
Leaf-wiseではLevel-wiseに比べて決定木が複雑になります。
複雑になるということはデータセットに対して適合しすぎて汎化性が低くなってしまいます。
つまり機械学習で避けるべき過学習を引き起こしやすいというデメリットがあります。
特に、データサイズが小さい場合に過学習しやすいので注意しましょう。
ジニ不純度
前述したとおりジニ不純度とは、ターゲットがどれだけ分類できていないかを表しています。本稿のキモとなる部分ですのでもう少し掘り下げて解説したいと思います。
![]()
こちらが、計算式で
tが決定木の任意のノード(決定木中の葉のこと)
cはターゲットラベルの数(分類したいものの数、例えば性別なら2)
p(i|t)がそのノード地点でカテゴリに属するものがデータ中どれだけ含まれているか
を示しています。
試しにジニ不純度が最も小さいケースを考えてみます。
ジニ不純度が最も小さいというのは特定のカテゴリですべて分類できるときです。
男性が100人中100人、女性が100人中0人で性別でカテゴライズした時を考えましょう。
計算式は以下になります。
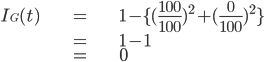
この場合は混ざりあいが全くないのでジニ不純度が0となります。
ジニ不純度が最大になるときは男性が100人中50人、女性が100人中50人とラベルが均等に分かれるときです。この時の値は0.5となりますので、0から0.5の間を取ることが分かります。
具体的にどうLeaf-wiseにどう適応させているかを図にしてみました。
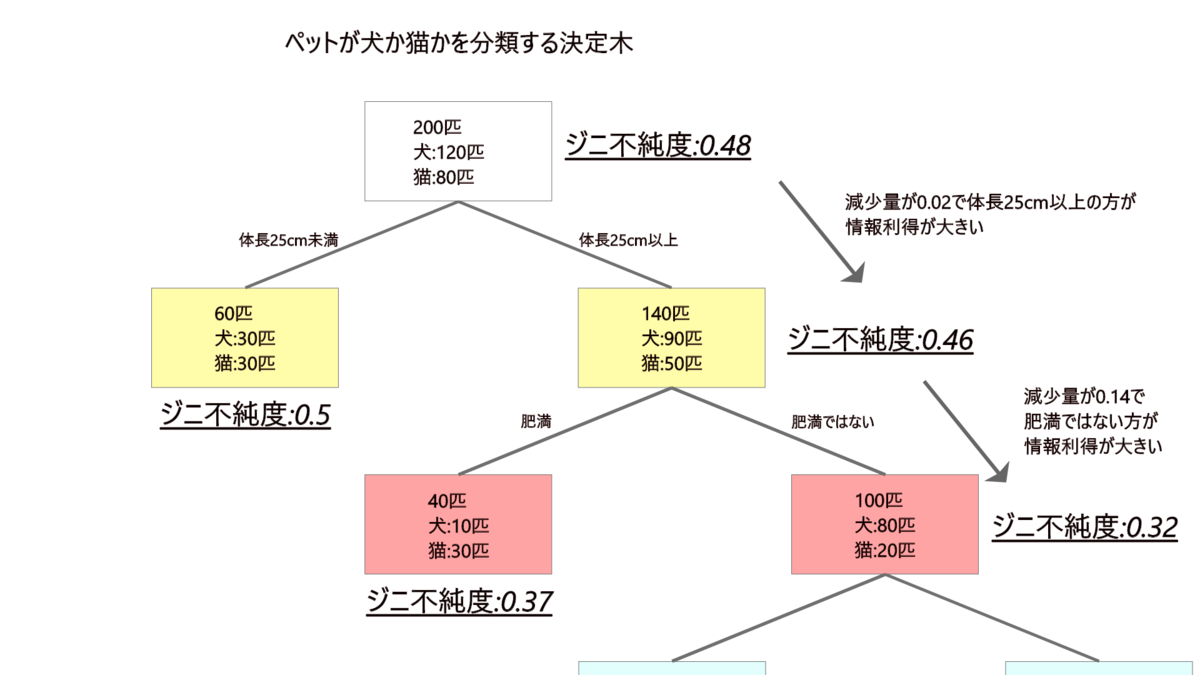
図中ではペットが犬か猫かを分類するために、体長で分けた後、肥満かで分類してみた例になります。
親ノードと子ノードのジニ不純度の差が情報利得と言われこの減少量が大きい方に分岐をしていきます。
ジニ不純度が大きく下がるということは効率的に分類が進んでいるということです。
上記例でいう体長25cm未満に分岐を進めると、ジニ不純度から見ても分類が全く進んでいません。
このような分岐を続けていてはいつまで経っても分類できないことになります。
その他のLightGBMの高速化の理由
上記以外にもLightGBMで計算が早くなる理由があり、GOSSとEFBという手法でデータを加工していることが挙げられます。以下で簡単に解説します。
GOSS(Gradient-based One-Side Sampling)
Sampling(以下サンプリング)とはデータの数をサンプルに取り出して学習を行うことです。
ただし、サンプリングをする際にランダムに取り出しては計算の精度が落ちやすいです。
そのため勾配を用いてサンプルに扱うデータを決定します。勾配が小さいということは、傾きが小さいということです。その際のデータは既に学習が進んでいると判断されるため学習をしなくてもいいと判断し除外します。勾配降下法の説明で用いたGIFで分かりますが学習が進む過程で傾きは小さくなっていますね。
EFB(Exclusive Feature Bundling)
似ている特徴量がある場合に、次元削減することです。
次元削減とは、異なる特徴量をまとめて一つの特徴量にすることを指します。
データセットが多い時には互いにゼロ値をとる傾向にある特徴量があったり、
相関性の高い特徴量が存在することがよくあります。
それらをまとめて一緒に学習することで、計算の量を小さくしています。
ヒストグラムベースでの分割
現在はXGBoostでもパラメータ調整で同等のことができますが、ヒストグラムベースで分岐点を探すということがLightGBMの高速化に貢献していました。
分岐点をすべて探索するのではなくヒストグラムを利用して大きな塊ごとに分岐点を探すことで、計算量を少なくしています。
まとめ
同じGBDTを元にしているモデルでも、LightGBMでは決定木の分岐方法を工夫して高速で計算が終わる工夫がしてあります。それまで主流だったXGBoostと比べて計算精度も劣らず軽量に計算を終えることができたので、現在ではLightGBMが使われることが増えました。
ただし、LightGBMはLeaf-wiseを採用したことで軽量になった分データサイズが小さい場合には過学習を起こしやすいという側面があります。
データセットに応じて使い分けることも意識してXGBoostかLightGBMかの選択をしていきましょう。
より、細かくアルゴリズムを理解したい方はオリジナルの論文をご覧ください。
https://proceedings.neurips.cc/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf
