
こんにちは!
最近、僕は遅すぎる集計処理を書いてしまい「遅い!」とシンプルに怒られてしまいました。。
みなさんは自分の書いたコードが遅いのか、速いのか測定したことがあるでしょうか。
本日は処理速度を計測することの重要性と計測方法について紹介していきます。
記事の概要
- 大量のデータに対して前処理を行う前などには処理の必要時間を把握することが重要
- jupyter notebookとlocal環境等ではそれぞれ異なる計測方法がある
- jupyter notebook: Magicコマンド1つで簡単に速度が計測が可能
- local環境等: 標準ライブラリのtimeを用いて簡単に計測が可能
- prunを用いることでプロファイラーを用いた詳細な計測が可能
なぜ実行速度を計測するのか
機械学習を用いる時に、避けては通れないのは「前処理」です。
データをモデルが学習可能な形式に変換したり、余分なデータを取り除いたり...と前処理の幅は多岐に渡ります。
仮に100万個のデータに対して、実行時間が1秒の前処理を行うと、単純計算で100万秒の時間が必要となります(約277時間)。
当然ですが、実行時間が10秒であれば10倍の時間が必要になり、100倍であれば100倍の時間が必要になります。
処理の実行時間を計測しておくことで、簡単に総実行時間の見積もりをすることが出来ます。
合わせて、処理時間が長い場合は処理の改善を検討することも可能です。
筆者の体験談
実際に筆者も計測を通して速度を改善した事があります。
- リストの生成を内包表記に変更した
- 計算処理をnumpyを用いた形式に変更した
- 形態素解析のライブラリをjanomeからMecabに変更した
- Pythonのバージョンをアップグレードした
など...
「どっちの方が早いんだろうか?」と疑問に思った時、コードを実行->計測->比較して気軽にデータを得られます。
計測方法について
jupyter notebookの場合
jupyter notebook(IPython)にはMagic commandというコマンド群が用意されています。
「%コマンド名」と入力するとコマンドが実行されます。
コマンドの一覧は%quickrefで確認することが出来ます。
|
# 出力結果が非常に長いので割愛 obj?, obj?? : Get help, or more help for object (also works as |
実行時間の計測に使えるのは以下の2つです。
- %%time
- %%timeit
%%timeセル内の処理の実行時間を計測します。
|
%%time
def create_list(size):
create_list(100) |
CPUの稼働時間(CPUtimes)はユーザー実行時間(user)とシステム実行時間(sys)の2つに分けて計測されます。
「Wall time」は計測を開始して終了までの総実行時間を指します。
今回は処理時間が短かったので単位には「 µs(10^-6)」が採用されました。単位については処理時間によって都度、適当な単位が採用されます。
また、%timeであればワンライナーでも測定可能です。
| %time create_list(100) # CPU times: user 0 ns, sys: 16 µs, total: 16 µs # Wall time: 20.3 µs |
どうやらワンライナーの方が動作が遅くなる傾向があるので、計測する際は記述を揃えておきましょう。
%%timeit
%timeは1回だけの測定に対して、%%timeitは複数回実行して処理時間を計測します。
|
%%timeit
def create_list(size):
create_list(100) |
Nというオプションを指定することで、実行回数を固定させることが出来ます。
Nが未指定の場合は精度が正確に計測される回数、実行されます。
| <N> is determined so as to get sufficient accuracy. |
コードを見る限りはautorange関数によって実行回数が決定されています。詳しい解説は省略しますが、総合実行時間が0.2秒を超過した際の実行回数が採用されるようです。
Nを指定して実行
|
%%timeit -n 100 create_list(100) |
jupyter notebook以外での実行
時間の差分を抽出
最もシンプルな方法ですが、拡張性があります。
呼び出し前と呼び出し完了後の時間の差分を求めることで、実行時間を計測します。
|
import time
def create_list(size):
create_list(100) |
簡単に計測が出来ますが、経過時間の差分算出のコードを対象のコードに記述する必要があり、非常に手間です。
また、計測値を受け取ることが出来ないというのも非常に不便です。
無名関数を用いた測定
計測したい処理を無名関数を用いて内包することで、計測対象のコードに手を加える必要がなく、計測値の受け取りも可能になります。
|
import time
def create_list(size):
def measure_wall_time(func):
executer = lambda: create_list(100) |
複数回実行した平均値、中央値などを求めたい場合には「measure_wall_time」に手を加えるだけです。
例として引数経由での実行回数の指定と、平均値、中央値、最小値、最大値の4つの項目を算出するように変更しました。
|
import time
def measure_wall_time(func, try_num=100):
executer = lambda: create_list(100) |
総括
今回紹介した以外の方法にも計測を行う方法はたくさんあります。
外部ライブラリや標準パッケージを組み合わせることでメモリ使用率の計測や、CPU使用率の計測など、オリジナルの計測処理を作成することも可能です。
コードを改善して前処理時間を減らしていきましょう!
おまけ: prunを使ったプロファイラ結果の出力
今回、紹介した方法とは別に、「prun」というMagic Commandを使うことでpythonのプロファイラーを用いた解析結果を確認することが出来ます。
|
# notebookのcell内での実行 %%prun
def for_list(size): res = [] for i in range(1, size+1): res.append(i) return res
for_list(100000) |
出力結果を見てみます。
for_listが1回呼び出されており0.023秒の時間が経過、appendが100000回呼び出されており、0.009秒の時間が経過しているなど、より細かい単位で経過時間を確認することが出来ます。
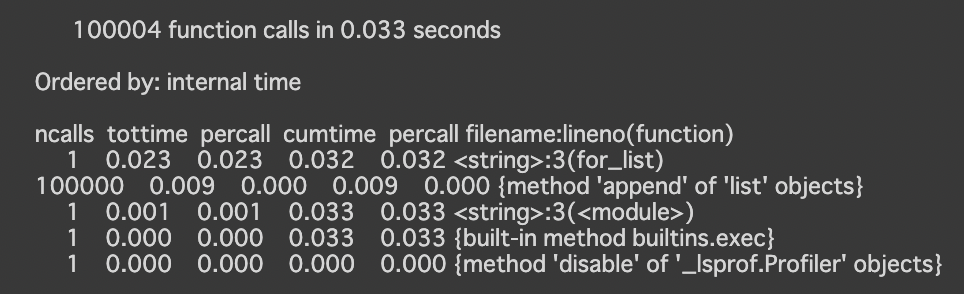
各項目の詳細については、Pythonプロファイラを参照ください。
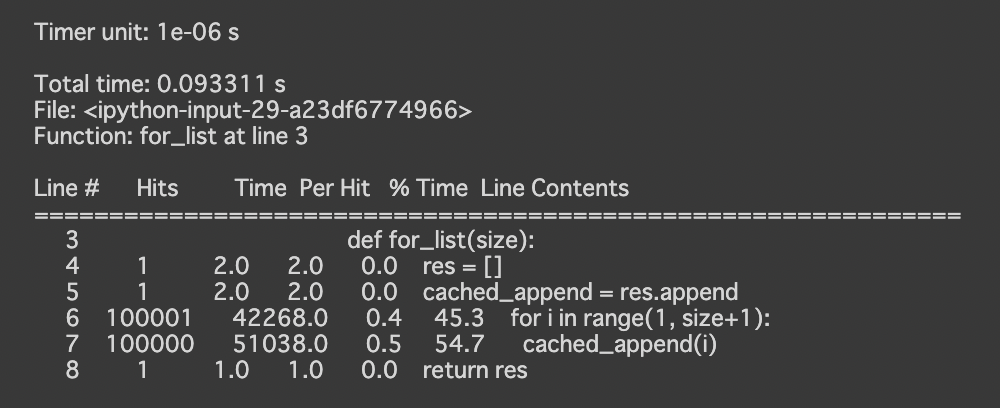
また、prunの他にも1行単位でのプロファイルを行う「lprun」やメモリの使用量のプロファイルを行う「memit」というコマンドもあります。
(どちらも別途インストールが必要です)
|
!pip install line_profiler %load_ext line_profiler %lprun -f for_list for_list(100000) |
|
!pip install memory_profiler %load_ext memory_profiler %memit for_list(100000)
# peak memory: 178.90 MiB, increment: 2.37 MiB |
参考文献
- Built-in magic commands
- github.com/python/cpython
- Introducing IPython
- Pythonのデコレータについて
- PEP 318 -- Decorators for Functions and Methods
