
こんにちは。本稿では機械学習を利用したコンポーネントの処理速度の計測方法、および負荷テストのやり方について解説してゆきます。
機械学習を利用するコンポーネントの処理速度を計測する必要性
機械学習を利用したタスクでは、モデルの精度に注意が行きがちです。しかし、一般的なWebアプリケーションでは入力はリソースID(ユーザIDなど)やシンプルなJSONである場合が多いのに対し、機械学習は入データ(自然言語や画像など)やその処理コストが大きくなりがちです。そのため実行時の処理速度が問題になることが以外に多いです。
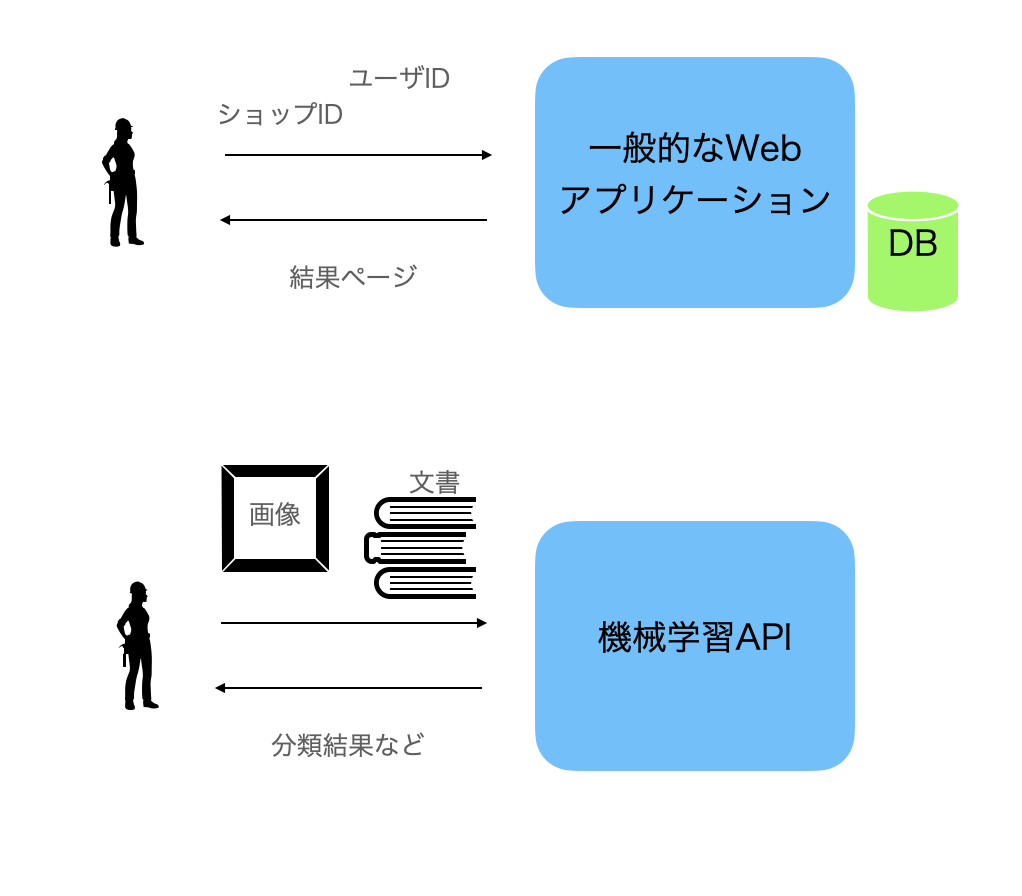
機械学習やその前処理の処理速度はモデルの高度化や使用する特徴量の変化などによって大きく変化していきます。初め問題なかったシステムでも、モデルの精度を向上するために入力データの前処理を複雑にして行くことで徐々に処理速度が遅くなっていきます。 機械学習を利用するシステムの精度を改善する施策によって処理にかかる時間が多くなってしまうと、改善施策をリリースした後に突然問題が発生してしまうことも考えられます。
求められる速度に制約がある場合には、機械学習システムの処理速度がその制約を満たしているかをチェックすのが望ましいでしょう。本稿でははじめに機械学習を適用する関数の速度を計測する簡単な方法について解説し、それをユニットテストのテストケースとして追加する方法についてみてゆきます。後半ではLocustというツールを利用して機械学習を適用するAPI(機械学習)の速度を計測する方法について解説します。
機械学習アルゴリズムを適用する関数の処理速度を検証
機械学習を適用するコンポーネントは学習済みのモデルを利用して推論結果を返します。通常推論を行う処理は関数もしくはクラスのメソッドとして実装されます。そのため、機械学習が適用する関数に入力が与えられてから出力されるまでの実行時間を測定することで処理速度が求められます。
実行時間を測定
関数の実行時間は time を利用すると計測できます。 たとえば DocumentClassifier という機械学習により入力テキスト(のリスト)のトピックを分類するクラスがあり、そのクラスには predict というメソッドが存在するとします。
このとき predict の実行時間は以下のように記述することで確かめられます。
|
import time from configuration import Config sample_docs = [
classifier = Classifier(
|
このスクリプトコマンドをターミナルで実行すると以下のように実行時間が表示されます。
| $ python scripts/sample.py 0.04538536071777344 |
CLIコマンドで実行するのであれば、上記のような測定は単純に標準出力に流すのではなく、ロガーを通じて出力するようにしておくとよいでしょう。さらに任意の関数に対して実行時間を検証できるように、デコレーターを定義しておくと便利です。
関数の実行時間を算出するデコレーター
Python にはデコレーターという仕組みがあります。関数に定義したデコレータを付与することで、関数の振る舞いを修正、追加できます。自分が体験した機械学習のようなデータを扱うプロジェクトの多くでは、関数の実行時間を算出する以下のようなデコレーターを定義して、利用していました。
| def elapsed_time(func): def _wrapper(*args, **kwargs): start = time.perf_counter() result = func(*args, **kwargs) end = time.perf_counter() print(f'{func.__name__} takes {end - start}') return result return _wrapper |
上記のようなデコレーターを定義しておけば、実行時間を知りたい関数に @elaseped_time を関数定義の前に付与しておくとことで、実行時間を自動で出力してくれます(ただし上記のコードをそのままプロダクション環境で使用すると大量のログを出力してしまうので、プロダクション環境ではデコレーターを削除するか、環境変数によって出力しない制御の追加が必要になります)。
性能評価テストと継続的な性能チェック
前節で解説した実行時間を計測する処理をユニットテストとして追加しておくと、モデルを改良している中で処理速度が劣化してしまっているとテストがFailすることで問題に早期に気がつけるので便利です(性能劣化に関わらずソフトウェア開発における問題は時間と共に修正コストが大きくなることが知られており、早期に問題を発見するのが重要です)。
以下に示すtest_annotation_speedは検証用データを処理する時間(実行時間)がしきい値(0.1秒)よりも少ないことをチェックしています。日々の開発で実行するテストに掛かる時間を大幅に増加させてしまわないよう、実行時間テストは閾値以内に完了する量のデータに対して適用するのがよいでしょう。
|
class TestAnnotationSpeed(unittest.TestCase): def test_annotation_speed(): |
上記のようなテストの実施をCI/CDに組み込むことで、修正による性能劣化が起こる前に問題を検知できる継続的な性能のチェック体制が整います。
機械学習 API の性能を評価する
これまで機械学習を適用する関数の速度を計測し、テストとして追加してきました。これにより修正のたびに、CIで性能の劣化を定常的に検知できる体制が整いました。
これによって実行時間と入力データの数から、関数にどの程度の文書集合を与えるとどの程度の時間で処理できるかについて大まかな情報がえられます。バッチ処理で機械学習コンポーネントを使用する場合は、大量のデータから決まった量のデータを切り出して逐次実行します。このようなシステムでは入力の大きさをシステム側で調整できるため、一定量のデータを処理するのに必要な時間についての情報があれば十分でしょう。
しかし機械学習を扱うコンポーネントをAPIとして適用した場合、どの程度のアクセスに耐えられるのかについては具体的にはわかりません。アクセスは複数のユーザから並列でも行われ入力の大きさも様々です。
このような場合、Locust という負荷計測ツールを利用できます。
Locust:インストールと負荷テスト設定追加
LocustはAPIサーバの負荷テストツールの一つです。LocustがAPIサーバに設定で追加したアクセスをすることで、負荷がかかった状態でのサーバの性能を計測できます。負荷のかけ方もUIを通じて変更でき、多様な状況での性能が検証できるのが特徴の一つです。
Locust は以下のように pip からインストールできます。
| $ pip install locust |
Locust は Railsなどで記述されたWebアプリケーションの負荷テストをするのによく利用されますが、機械学習のようなデータを処理するAPIの負荷テストにもおなじように利用できます。
今回負荷テストを適用する機械学習APIはFlaskで記述されていて以下のようなコードになっています。APIへの入力データJSONフォーマットでPOSTメソッドで追加され、結果はJSONで追加されます。
| @app.route('/predict', methods=['POST']) def predict(): contents = request.json results = classifier.predict(preprocess_data(contents)) return jsonify({"results": results.tolist()}) |
入力はJSONフォーマットで、一つ以上の文書をリストとして追加します。例えば以下はふたつの文書の場合の入力です。
| [ ["日本航空が7年ぶり首位、国際線の旅客数 コロナ禍から回復は遠く。"], ["オランダ1部PSVに所属する日本代表MF堂安律が、来季のマインツ入りが決定的になったとドイツ紙「ビルト」が報じている。"] ] |
結果は以下のようなJSONです。
| { "results": [ "economy", "sports" ] } |
Locust は locustfile.py という名前の設定ファイルを使います。locustfile.py にはAPIサーバにアクセスするユーザの振る舞いを記述します。以下は 入力となる入力をAPIに投げるユーザを模した Locust の設定です。
|
CANDIDATES = [ class DocumentTopicRequestUser(HttpUser): self.client.post(url="/predict", |
Locustを利用した負荷テストの設定ファイルにはAPIを使用するユーザを表すクラスを HttpUser クラスを継承して作ります。今回はユーザは入力文書のトピックを分類してもらうタスクなので、DocumentTopicRequestUserという名前にしてみました。
クラスにはユーザの振る舞いを記述します。今回のユーザの振る舞いを記述するには @taskデコレータを追加したメソッドを作ります。今回は単純に数個の文書を文書分類API(/predict)に追加するだけなのでひとつのメソッド(predict)を追加するだけです。
メソッドにはAPIに対するアクセスを記述します。今回は /predict に対して、POSTメソッドで入力文書(JSON)を追加してアクセスします。上記のLocustの設定では複数の文書候補から1〜3件の入力データを選択して結果を抽出するリクエストを投げるユーザを表現しています。実際のリクエスト文書を生成するのが理想かもしれませんが、負荷をかけた状態での性能が知りたいだけなので変数 CANDIDATES に含まれるの文書をランダムで1〜3件追加するようにしています。
Locsutを使った測定測定
設定ファイルができたら Locust サーバを起動して使います。Locust サーバは locust コマンドで立ち上がります。
| locust [2022-05-07 20:12:05,588] locust.main: Starting web interface at http://0.0.0.0:8089 (accepting connections from all network interfaces) [2022-05-07 20:12:05,594] INFO/locust.main: Starting Locust 2.8.6 |
Locust サーバは 8089 ポートに立ち上がっているのでWebブラウザでアクセスするとLocustの画面が開きます。
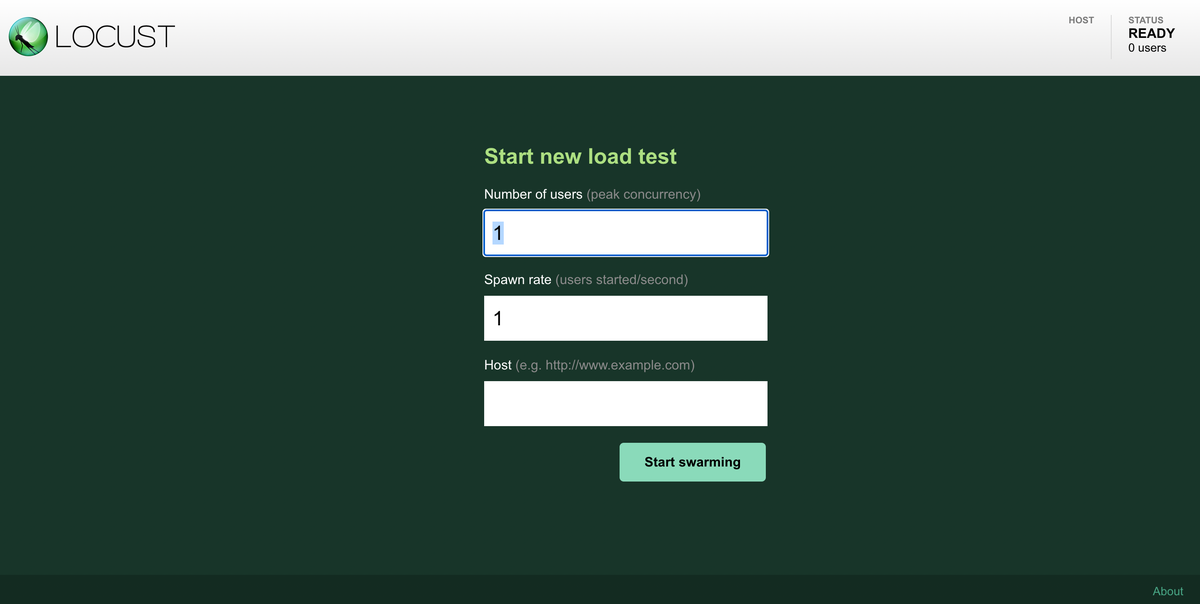
画面にはユーザの数、ユーザが増えるタイミング、そしてアクセスするサーバのURLを指定します。ユーザ数が少なすぎると十分な負荷にならないので、負荷テストにならないことがあります。最適なユーザ数は予定される負荷に基づいて選択すると良いでしょう。
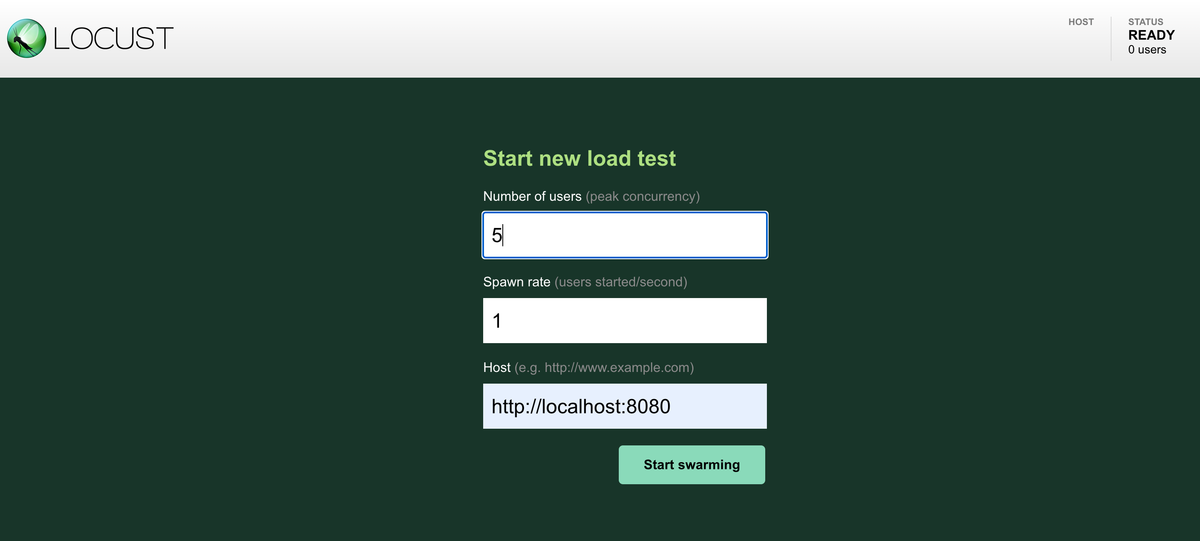
今回はローカルに立ち上げた文書サーバを指定して実行します。Start swarming ボタンをクリックすると負荷テストが開始され、負荷テストのモニタリングページが開きます。
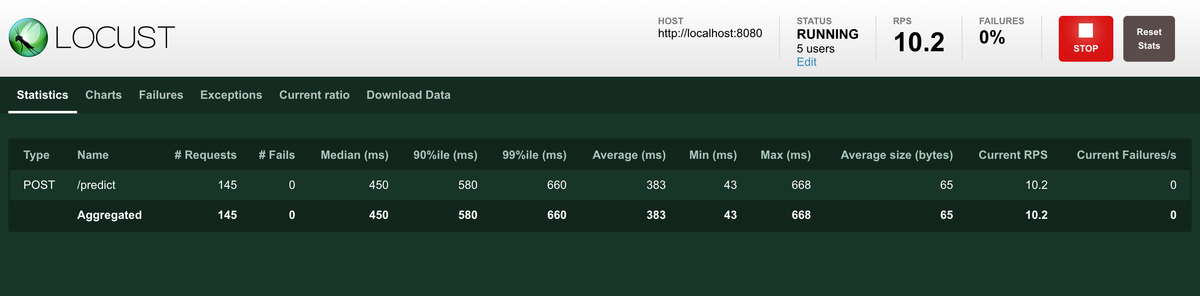
Graph タブを開くと負荷テストの状況がグラフで表示されます。
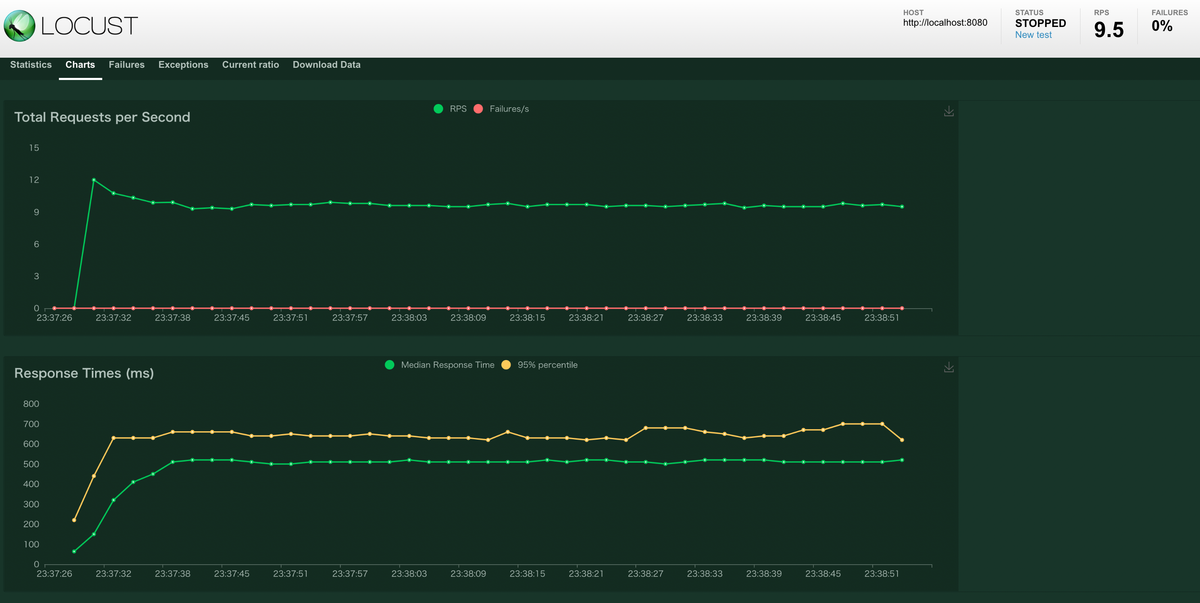
描画されるグラフには1秒でどれだけのリクエストを処理できたのか(Request per Second)や リクエストを処理するのにかかった時間 Request Times などがあります。とくに Request Times では 95% tile での処理時間も描画されるので突発的に遅くなるような挙動についてもチェックできます。
もうすこし高度な使い方
今まで解説してきた内容を利用するだけでもLocustは便利なツールなのですが、設定を追加することで以下のようなことに対応できます。
分散実行
一台のコンピュータで負荷テスト実施したいサーバとLocustプロセスを動かす場合、コンピュータは負荷テストを受けているAPIサーバとLocustの両方の処理をしなくてはならず、正確な負荷テストになりません。
そこで通常は負荷テストを適用したいサーバはローカル環境以外のところに立てて、Locustから外部にアクセスします。残念ながら、この場合でも負荷を十分にかけられないことがあります。
このような場合Locustは master-slave 構成をサポートしており複数のプロセスを強調して動作させることでより大きな負荷をかけることができます。
コマンドラインから実行
Locustサーバを立ち上げて Web UIから利用するのは便利なのですが、CI/CDから呼び出してリリースプロセスに組み込みたい時などコマンドラインから使いたい場合があります。
このような時 locust コマンドを --headless オプションをつけて実行します。
| $ locust --headless -u 1000 -r 100 |
上記のコマンドで、 -u はAPIサーバにアクセスするユーザ数、-r は ユーザが生成される速度(上記の設定では100秒に1人ユーザが生成されます)を表します。
まとめ
機械学習を利用したプロジェクトは精度に注意が行きがちですが、意外に処理速度が問題になることがあります。開発速度をテストで継続的にケアしつつ、初回リリースや大規模改変前にはLocustなどの負荷ツールで想定される負荷に耐えられるかをチェックすることで、リリース後に問題が発生する事態を避けられます。
