 こんにちは!
こんにちは!
AIがトレンドとなって世間で騒がれる中、『文系だけどAIの開発ができるようになりたい!』と思う方も多いのではないでしょうか。
今回は文系出身の私、小笠原がAIにも通ずるデータサイエンスの知識を得るまでに行った勉強方法を紹介します。データサイエンスはAIのベースとなる領域ですので、データサイエンスを学ぶことはAIを学ぶことにつながります。
本記事では文系の方を対象としますが、文系出身ではなくてもデータサイエンス分野の勉強を始めてみたい方は是非一読ください!
前半で文系出身でもデータサイエンスの勉強を進められるかどうかの疑問点解消、それから勉強を進めていく注意点。後半で実際に私がどのように勉強を行ったのかを書籍などを紹介しつつ説明します。
文系出身でも大丈夫?
数学への苦手意識
文系の方々の多くは数学に苦手意識を持っている方が多いですよね。
データサイエンスでの分野では複雑な数式が出てきますが文系で容易にその数式を理解できる方はほとんどいないでしょう。無論、私もそうです。本節では数学との向き合い方のマインドの話をします。
高校数学を頑張った方でも、理系大学で扱うような数学には馴染めないと思います。ただでさえ数式が複雑なのにΔやηとか謎の記号も出てきてちんぷんかんぷんになりますよね。
数学的な知見が乏しいことや数学への苦手意識が文系がデータサイエンティストになりたいと思ったときに大きな壁となりますが、安心してください。
数学の知識は勿論あるに越したことはないですが、そこまで難しい数式を解く力や複雑な公式を暗記する必要はありません。
何故ならプログラムを書くとき大抵は、ライブラリと呼ばれる既にプログラムの組み上がっているものにデータを流すような処理をするので、自分で数式を考えたり解いたりする必要はほとんどないからです。
あくまでも大切なのは数式への理解ではなくどのような分析を行うことでどのような結果を得られるかという、工程への理解です。
数学的な理論は最初は流してしまって、興味がわいたら論文を読んでみたりして数学知識を身につけて深く理解してみましょう。
幸いネットで見れる無料の情報にも優良な説明はたくさんあって、ちょっと〇〇が知りたいなんてニーズも十分に満たしてくれます。
個人的な見解ですが文系が不利なことはどちらかというと数学に対して消極的になってしまう気持ちの問題だと思っています。もしデータサイエンスに興味があるのなら思い切ってチャレンジしてみてください。文系だから無理と決めつけて諦めるのは勿体ないです!
統計学が分かりづらい
この分野を理解する上で統計学的な考え方が非常に重要になりますが、いま読んでくださっている方で統計学に慣れ親しんでいるという方は少ないかと思います。
統計学では過去の結果が未来の結果に当てはまるということを前提にしています。例に挙げると以下のようなものがあります。
- 昨日の朝に満員電車だったから今日の朝も満員電車だろう
- 去年のクリスマスにチキンが売り切れたから今年もチキンが売り切れるだろう
皆さんの日々の行動の中でもこういったことを何気なく考えていますよね。これらも統計学的な考え方ですが、予測が外れている可能性を数値化して指標とすることがあります。
分析の精度を測ったときに指標と外れていたら、値が小さいほどいい分析であったといえます。統計学は逆説的な考え方の多い学問であると感じていて、私は普段親しみのないこういった考え方に触れることに苦手意識がありました。
統計学分野の特徴をつかむことを意識しながら学習を進めていくと理解がスムーズになります。

文系の有利な点を考える
不利なことを考えていても億劫ですし、折角なので逆に文系がデータサイエンスで有利になる点を考えてみましょう。
社会問題を考える経験がある
ビジネスの世界でのデータサイエンスは、社会学的な領域を取り扱うことが多いです。その点は文系のほうが理系より経験してきていることですので、データで得られたことを課題に対して活かすということは文系のほうが得意なのではないでしょうか。
心理学や行動経済学とも関連性の高い領域ですので文系としての経験が生きる機会も多いと感じます。
コミュニケーション能力が高い
大学での授業で理系では実験を行うことが多いのに対して、文系では討論を行う機会が多いからでしょうか、専門的な知識を用いた学術的なコミュニケーション能力などは一般的に文系の方が高いと言われています。
語学系の勉強をしてきた方や文学の勉強で語彙力を養ってきたなど、コミュニケーションにまつわる学問を経験してきた方も多いですよね。
IT系の技術職は黙々とPCに向かっているイメージが多いかもしれませんが、実際はチームで業務を行うことが多いのでメンバーとのコミュニケーションは頻繁に行わなければなりません。
データサイエンスのスキルに加えて高いコミュニケーション能力があると貴重な人材になれます。
上記にあげたように文系の有利だと考えられる点もあります。強みを活かせば理系人材と差別化して、価値ある人材になれると思います。
学習方法の解説
データサイエンスを学ぶのは何が難しいのか
分野自体が難しい領域であることはもちろんですが、この分野が取り扱っている領域が広いため勉強をするときに混乱しがちであるということも学習を難しくしている要因だと思います。
単純な回帰問題から始まり、言語の分析があったり、画像の解析があったり、分析するテーマで学習すべき内容が乱立しています。
上記のように一口にデータサイエンスといっても扱う範囲が大きく地図が描きづらいため、初学者は何を学ぶべきか迷子になってしまいます。
そのうえ、非常に速いスピードで成長している分野なので日々新しい技術が開発され、最新の技術を追おうとするとかなりの労力を要してしまいます。
体系的に学ぶことをオススメ
データサイエンスもネットでも多くの解説がされており、お金を払わずたくさんの情報に触れることができます。しかし前節でも解説した通り、データサイエンスは非常に広範な分野を取り扱うので、なんとなくネット検索しながら勉強していくのは相当な労力がかかり非効率です。
お金はかかってしまいますが、書籍やUdemyなどの学習サービスを利用することで体系的に学ぶことをオススメします。
まずは入門書を読んである程度データサイエンス全体を俯瞰した後に、プログラムの公式ドキュメントを覗いてみたり、当サイトにあるようなデータサイエンス記事を熟読するなどして知識を深めていくのが効率的かと思います。
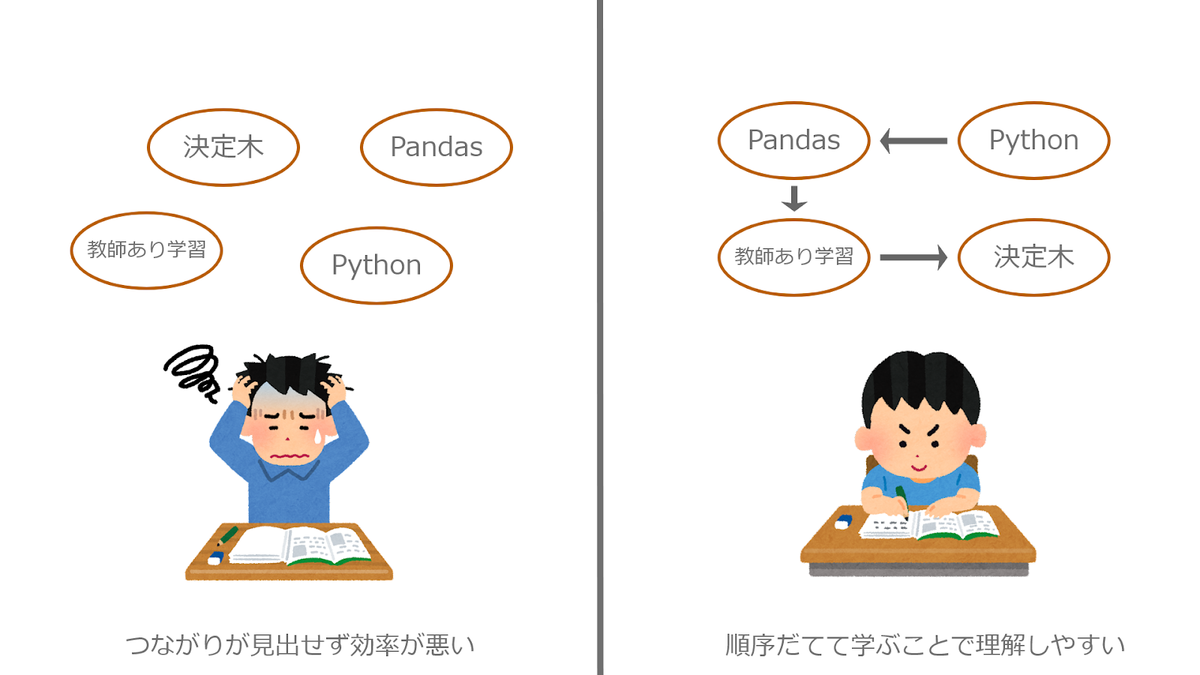
勿論お金が許すのなら良質な参考書も数多くあるので、入門書のあとも書籍を参考に勉強するのもいいでしょう。私は書籍を用いて勉強したので実際に勉強をして参考になった参考書を紹介しながらどのように勉強を進めていくのが効率的かを解説していきます。
小笠原の勉強のコツ
折角なので私の個人的な勉強のコツを記述しておきます。
立ち止まらないこと
データサイエンスのような広範な分野だと特にですが勉強を進めるごとに分からないことが増えてその度に足止めをくらいます。理解に苦しんでくよくよするよりも分かることから拾っていく勉強法のほうがモチベーションが保ちやすいと思います。
分からないことも寝かせておくと後から急に気づきが増えて理解できるということもあるので、参考書は1周で完璧に理解するというよりも、2周3周と繰り返して少しずつ理解度を上げていくという姿勢のほうが結果効率的に感じています。
日常的に勉強すること
継続は力なりという言葉もある通り、結局はどれだけ続けられるかが肝心だと思います。できれば時間を決めて毎日少しずつでもデータサイエンスに触れてみましょう。
私は夜は眠くて頭が回らないので頭を使う勉強は朝に行うようにしています。1日30分程度でも習慣化することで何冊も参考書を読破して来れました。
まずはコードを書いて動かすことから始めましょう
最初はロジック的な難しい話よりも自分でプログラムを書いて動かして結果を得ることで実際のデータサイエンスに触れてみるところから始めたほうがモチベーションも上がりやすいです。
理解は後回しにしてなんとなくでいいので動かしてみましょう。
やっているうちに後から分かる部分もあるのでまずはプログラムを組んで動かすというデータサイエンスの基本に慣れ親しんでみてください。
データサイエンスの入門書となると、プログラミングが前提知識として扱われることも多いです。高度なプログラミング知識はいらないので無料の教材で軽く予習しておくと入門書に入りやすいかと思います。無料の教材を以下に挙げておきます。
この後紹介する『東京大学のデータサイエンティスト育成講座』では基本的なプログラミングの書き方も解説されているので下記の無料資料は必須ではありません。
「Python ゼロからはじめるプログラミング」サポートページ
ゼロからのPython入門講座 - python.jp
※PCは性能のいいものじゃなきゃダメ?
AIというと物凄い高性能なPCじゃないと動かないイメージもありますが、安心してください。クラウドと言ってネット上でプログラムを実行できるツールもあるので、PCの性能は大して求められません。
例えばGoogle Colaboratoryもそうですし、後述するKaggleもクラウド上でデータサイエンスのプログラムを実行してくれます。
Google Colaboratory
https://www.kaggle.com/
入門編

参考書というと分厚いものが多いですがこちらは比較的薄めのものではじめの一冊として手に取りやすいかと思います。
Kaggleとはデータサイエンティストがコンペで競い合ったり、技術に関して議論したりしているデータサイエンティスト向けのSNSのようなものです。
まだデータサイエンスに触れたことがないと敷居が高そうで敬遠したくなるかもしれませんが、データサイエンスに必要な実行環境が無料の会員登録をするだけで手に入るうえ、データサイエンスの勉強でネックになる分析対象のデータまでダウンロードできます。
以上からKaggleは初学者でも十分に活用できるプラットフォームといえます。本書の対象読者はある程度プログラミングを理解している方になっていますが、コードがしっかり乗っていることに加えファイルをダウンロードできるのでプログラミングがほぼできない方でも機械学習に触れやすい配慮がされています。
まずは、本書に書いてあるプログラムを真似して実行することで、分析して結果を得る楽しみや実感を味わってみましょう。

いかにも参考書という感じで分厚めな本です。
ディープラーニングは含みませんが基礎的な機械学習手法を網羅的に学習できます。こちらの参考書はプログラミングそのものの初歩からの説明も含むため、プログラミングを全く知らない方も対象となっています。
プログラミングから基本的な機械学習を一気に学びたい方は本書をオススメします。各節に練習問題があるので、ザっと内容を斜め読みしてから練習問題を解き、それをこなす中で理解を深めていく進め方がいいかと思います。
ステップアップ編
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

ディープラーニングを1からPythonで書いてみるためのステップが載っています。複雑なディープラーニングを自分で実装してみるため、どうやって学習が進んでいくのかの全行程を理解することができます。
分厚い本でやることも大掛かりな内容に感じますが、掲載されている数学も簡単なもので説明も非常にシンプルです。シリーズ化されており一冊目は画像の解析などを行います。
ディープラーニングはなんとなく勉強すると内部処理が不透明になりがちで、それなりには動かせても何をやっているか分からないという状態になってしまいます。本書では1から学ぶので中身を細かく理解できるのでディープラーニングの勉強にはもってこいでしょう。
BERTによる自然言語処理入門: Transformersを使った実践プログラミング

本書は言語分野で使われるBERTというディープラーニングライブラリの解説及び実践本ですが、言語をどのようにコンピュータで読み取って分析と予測を行っているのかまで丁寧な解説がされています。
BERTに限らずそこに至るまでの言語分野の分析の歴史が学べるので、言語データの分析がしたいという学習者にはもってこいの参考書となります。
ザックリ読んでみて試してみたい分析は実際にプログラムを書いてみるといいでしょう。文章の穴埋めとかはTOEICの穴埋め問題を機械学習で解いたりできるので、手元の英語教材などで正答率を確かめてみるといった遊びをしてみても面白いですよ。
現場で使える!Python深層強化学習入門 強化学習と深層学習による探索と制御

強化学習は機械自身が自ら学習を繰り返して最適な行動を導き出す、学習手法のことです。とてもAI的ですね。本書では強化学習の理論から実践にまで触れています。解説はかなり丁寧で数式を持ち出して内部的な理論からしっかり解説されています。
私の興味のある領域なので何度か読み返していますが、強化学習そのものが難しい理論なので理解するのはとても骨が折れます。実践にはルービックキューブを解かせてみるプログラムがあったりしてとても面白いです。
2015年に、プロ将棋士にAIが勝ったということで世界を震撼させました。実はその時使われたAIのAlphaGoは強化学習をベースとしています。最先端のAIに興味のある方は読んでみてください。
数学的な理論を掘り下げたくなったら
統計学に基礎から親しみたい方は完全独習シリーズがオススメです。

こちらは中学レベルの数学で統計学の基本を丁寧に解説した一冊となります。色々な統計学の入門本がありますが、これが一番わかりやすかったと感じます。
統計学はデータサイエンスの一番の根底にある理論なので、余裕のある方は是非勉強をしておきましょう。
ちなみにデータサイエンス領域は普通の統計学よりもベイズ統計学に基づいているものも多いです。細かくは割愛しますが、同シリーズの参考書も同様に分かりやすく優良なものでしたので紹介しておきます。
また、プログラミングで統計学を学ぶ形式の参考書も紹介します。『Rによるやさしい統計学』はRという言語で統計学を基礎から勉強する本です。ついでにPythonの評判のいい参考書もリンクをしておきます。
どちらも統計学の基礎を扱っているので学びたい言語に応じて選択してみてください。

本書は高校一年生の数学の復習から始め、少しずつディープラーニングの数学的理論を解説するという内容になっております。
そのため文系の方でも十分に理解ができる内容になっています。私も読了していますが、やはり難しいですね。完璧には理解できなくても本書を読めば高校レベルの数学の復習になります。
そのうえ部分的にでも数学的な理論を抑えているかでデータサイエンスの捉え方が変わってきます。
ガッツリ数学的な理論からディープラーニングを理解したい方はぜひチャレンジしてみてください。
さらに先に進むには
実践系の参考書籍にもチャレンジ

私が購読したのは上記の一冊ですが、根強い人気があるのかシリーズ化されていますね。
本書の素晴らしいと感じる点は、単なる実践系の本ではなく、実際のビジネスで起こりえそうな課題を与えられることです。
顧客の要望と、実際にありそうなデータからどのようにその要望に応えていくかという構成になっています。ただの実践ではなく実務的なデータサイエンスに触れられるので、これをやってみるとかなりの自信につながります。
Kaggleのコンペに挑戦
私もたまにチャレンジしていますがKaggleのコンペにチャレンジすると大変勉強になります。出された課題に対して、少しでも分析の精度を上げるために試行錯誤するのですが、その間ほかのユーザーと情報交換をしたり、精度のいい分析を公開しているユーザーから参考になる部分を自分のプログラムに落とし込むようなことをやります。
一つの課題に対して十人十色の様々な分析手法を知れることもあるので、とても勉強になります。ただ、サイトが英語なのでどうしても英語を避けたい方はSignateなどの日本で開催されているコンペにチャレンジすることもオススメです。
まとめ
以上が文系の小笠原がデータサイエンス領域の知識を得るまでの勉強方法でした。
少しでもデータサイエンスに興味がある方は臆せずチャレンジしてみましょう!当サイトDATA Campusではデータサイエンスにまつわる様々な知見をまとめてあります。勉強の役に立つ記事も沢山ありますのでぜひ他の記事も覗いてみてください。
