
FastAPIとは
2022年現在、大人気のマイクロWEBアプリケーションサーバーを構築するためのPython製のフレームワークです。2018年12月に作者のtiangoloさんがリリースしてから、活発に開発がされています。作者のtiangoloさんは元々、仕事でも機械学習やデータシステムのAPIやツールを作成されていたそうです。
だからこそ、使いやすさ、必要なものが何かを認識しておりFastAPIはここまで広く使われるようになったのではないでしょうか?
元々、PythonでマイクロWEBアプリケーションサーバーを構築する時はFlaskというWEBフレームワークが広く使用されていました。しかし、今日ではFastAPIが猛勢を奮っています。その理由をFastAPIの特徴を見ながら、追っていきましょう。
特徴
API作成までの手軽さ
PythonでWEBフレームワークといえば、まずDjangoの名前が上がります。RubyでいうRailsのような立ち位置でPythonで大規模なWEBアプリケーションを作るのに向いています。
しかしながら、簡単なAPIを1つ作るだけでもViewの作成とルーティング、ケースによっては様々な設定を行う必要があり、なによりもファイルサイズが大きくなってしまいます。
それに対してFastAPIでは.pyファイル1つでAPIを作ることが出来ます。
詳しくは「シンプルなGETのAPIを作る」で紹介しますが、FastAPIの記述はFlaskやResponderと似ており、非常に簡潔なものなので、数分もあればAPIを1つ作ることが出来てしまうでしょう。
Flaskよりも非常に高速
APIが手軽に作れることは分かりましたが、手軽さでいえばFlaskも負けていません。
それだけでは、FastAPIを使う利点がありませんが、FastAPIがFlaskよりも人気な理由の1つは動作の速さです。
こちらの記事では、Pythonの著名なフレームワークのパフォーマンスの比較を行なっております。
PythonのWeb frameworkのパフォーマンス比較 (Django, Flask, responder, FastAPI, japronto)
結果だけを見ると、Flaskに比べてFastAPIは高速で、高負荷に耐えられることが分かります。
FastAPIが高速な理由の1つとして、WSGI(Web Server Gateway Interface)ではなく、後続のASGI(Asynchronous Server Gateway Interface)であるStarletteを使用しており、非同期での処理を効率的に実行しているからです。
FastAPIの公式ページにも「FastAPIは巨人の肩に立っている」と記載があります。
|
(引用) FastAPI は巨人の肩の上に立っています。 |
ドキュメントの自動生成
FastAPIはWEBアプリケーションサーバーを起動すると「http://xxxxxx/docs」というエンドポイントを自動で生成します。
このエンドポイントではFastAPIが作成したドキュメント(Swagger)をSwaggerUI上で確認することが出来ます。APIのドキュメントはAPIがどのようなリクエスト、パラメーターを許容するのか、どのようなレスポンスを返すのかを把握するためには必須と言えます。大規模なプロジェクトになればなるほど、ドキュメントの有無が開発速度に影響を与えます。
仮にSwaggerが自動生成されないと、ドキュメントを全て.yaml形式の手書きで用意する必要があり、非常に手間がかかります。また、最初こそドキュメントを用意することが出来るケースもあるでしょうが、APIへの修正や変更がある度に、ドキュメントも修正し続ける必要があります。
その点、FastAPIではAPIの変更に合わせてSwaggerも自動で更新されるため、こういった手間が必要ありません。
また、今回は詳しく解説しませんが、Pythonの標準ライブラリのtypingを使って型アノテーションを行うと、FastAPIが内部でpydanticを用いたバリデーションの実行を行なってくれます。型アノテーションを行うことで、FastAPIはより正確なドキュメントを生成するようになります。
簡単なAPIを作る
それではFastAPIの紹介は終わりにして、いよいよFastAPIを使ってみましょう。
※動作の確認にはPython3.9x系を使用しております。
インストール
まずはPythonに標準で用意されている「venv」コマンドを使って仮想環境を作成します。
なお、仮想環境については作成しなくても問題はありませんが、ローカル環境へのグローバルなインストールが発生する点にはご注意ください。
プロジェクトの用意
| $ mkdir fastapi_sample $ cd fastapi_sample |
environmentsという名前で仮想環境を作成
| $ python -m venv environments |
作成した仮想環境を起動
| $ source environments/bin/activate |
仮想環境の用意が出来た所で、FastAPIの公式ドキュメントに従ってインストールを進めます。
| (environments) $ pip install fastapi[all] |
[all]というオプションを付与することで、関連パッケージである「uvicorn」のインストールも実行されます。FastAPIとuvicornはそれぞれ別にインストールすることも可能です。
| (environments) $ pip install fastapi uvicorn |
これでFastAPIが無事にインストールされました。
| (environments) $ pip freeze | grep fastapi fastapi==0.75.2 |
シンプルなGETのAPIを作る
まずは「hello world --FastAPIより愛を込めて--」というシンプルな文字列を返す「GET: /hello」というAPIを作成してみます。
| (environments) $ touch main.py |
作成したmain.pyに以下を記述します。
main.py
|
from fastapi import FastAPI # FastAPIのインスタンスを作成 # GETのメソッドで/helloのエンドポイントを指定 @app.get("/hello") |
記述が完了したらuvicornを起動します。これでアクセスが出来るようになるはずです。
|
(enviroments) $ uvicorn main:app --reload api | INFO: Will watch for changes in these directories: ['/app'] |
curlコマンドでレスポンスを確認してみます。
| (environments) $ curl http://localhost:8000/hello -X GET "hello world --FastAPIより愛を込めて--" |
無事にGET: /helloからレスポンスがあることを確認出来ました。jsonを返したければ、関数の「return」を辞書型にするだけでOKです。
| @app.get("/hello") async def sample(): return { "message": "hello world --FastAPIより愛を込めて--" } |
|
(environments) $ curl http://localhost:8000/hello -X GET |
たったこれだけでAPIが作れてしまうとは驚きです。
自動生成されるドキュメント
なんと先ほどのシンプルなGETのAPIを作成した時点でドキュメントが自動生成されています。生成されたドキュメントは「http://localhost:8000/docs」から確認することが出来ます。
ブラウザでアクセスすると以下のようなSwaggerUIが表示されます。
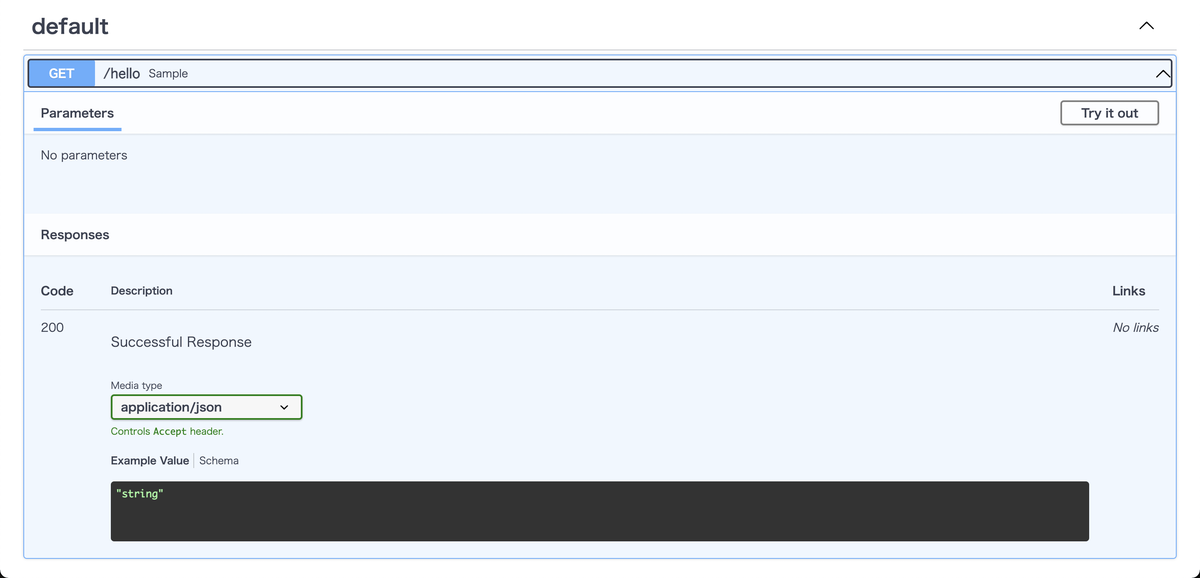 先ほど作成した「GET: hello」が表示されていることが分かります。
先ほど作成した「GET: hello」が表示されていることが分かります。
また、リクエストのパラメーターの一覧・型であったり、エラー時のレスポンスなども、このドキュメントに記載されます。
今回はシンプルなAPIだったので、これだけだと何が便利なのか感じにくいですが、実際の本番稼働するAPIでは複数のクエリストリングやリクエストボディなど多くの情報を把握する必要があります。
SwaggerUIのようなドキュメントがない場合には、自分でドキュメントを作成するか、関係者に確認する、コードが読み解くという作業をしないといけません。
推論APIを作る
次はPOSTで機械学習モデルの推論結果を取得する「POST: /predict」というAPIを作成してみます。値の受け渡しにはリクエストボディを使用します。
また、機械学習モデルはiris(アヤメ)の品種分類を事前学習済みのモデル(.pkl形式で保存済み)を使用します。
以下の手順で作成しました。今回はモデルについての詳細は割愛します。
| from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression import pickle iris_datasets = load_iris() model = LogisticRegression(C=100) # 推論時に使用するためデータを1つだけ学習対象から除去 model.fit(iris_datasets.data[:-1], iris_datasets.target[:-1]) pickle.dump(model, open('iris_model.pkl','wb')) |
実行時に生成された「iris_model.pkl」をfastapi_sample内にコピーします。また、LogisticRegressionをfitした際に以下のようにモデルが収束出来なかったという警告文が出力されることがあります。
| Increase the number of iterations (max_iter) or scale the data as shown in: https://scikit-learn.org/stable/modules/preprocessing.html |
その場合には、LogisticRegressionの引数で「max_iter(デフォルトで100)」の数値を変更することで解消されます。
| model = LogisticRegression(C=100, max_iter=1000) |
学習済みモデル(.pkl)の読み込み
推論を行うためにscikit-learnが必要になるのでインストールします。
| (environments) $ pip install scikit-learn |
先ほどのAPI作成の手順に従って同じようにmain.pyを記述します。
| from fastapi import FastAPI import pickle # 機械学習モデルの読み込み: サーバー起動時に一度だけ読み込ませるため関数外に記載 model = pickle.load(open("iris_model.pkl", "rb")) app = FastAPI() @app.post("/predict") async def iris(): return { "result": model.predict([]) } # .predictで推論結果を取得 |
.predictに使用するデータはリクエストボディから取得するので、一旦、空配列にしておきます。
リクエストボディから推論を行う
FastAPIでリクエストボディを受け取るには「pydantic」という型アノテーションのライブラリで受け取る値の形式(型)を定義する必要があります。
今回はirisの推論を行うために以下4つの数値(float)を配列で受け取るようにします。
- がくの長さ
- がくの幅
- 花びらの長さ
- 花びらの幅
| from pydantic import BaseModel from typing import List class PredictRequestBody(BaseModel): input: List[float] |
これでリクエストボディの定義が出来ましたので「POST: /predict」で受け取れるように既存の「def iris」を変更します。
| @app.post("/predict") async def iris(req: PredictRequestBody): |
「iris」の引数reqに受け取ったリクエストボディが格納されます。「req.input」とすれば値にアクセスが可能です。あとはこの値をモデルの「.predict」に受け渡せば推論が実行されます。
| import numpy as np @app.post("/predict") async def iris(req: PredictRequestBody): # predict関数が指定するnumpy.ndarrayの形式に変換 to_predict = np.array(req.input) # predict関数は複数の値の入力が必要なため配列で受け渡し、1件目の結果のみを取得。 # またresponseをint型に変換(※型エラーになるため) return { "output": int(model.predict([to_predict])[0]) } |
一度、コードの全体像を確認しましょう。
| from fastapi import FastAPI from pydantic import BaseModel from typing import List import numpy as np import pickle model = pickle.load(open("iris_model.pkl", "rb")) app = FastAPI() class PredictRequestBody(BaseModel): input: List[float] @app.post("/predict") async def iris(req: PredictRequestBody): to_predict = np.array(req.input) return { "output": int(model.predict([to_predict])[0]) } |
では、推論APIを呼び出してみます。学習時に使用しなかった「iris_datasets」の末尾の値を使います。
| iris_datasets.data[-1] # array([5.9, 3. , 5.1, 1.8]) iris_datasets.target[-1] # 2 |
curlで実行します。
| (environments) $ curl -X POST -H "Content-Type: application/json" -d '{"input": [5.9, 3.0, 5.1, 1.8]}' http://localhost:8000/predict {"output":2} |
結果を受け取ることができました。予測値も2(virginica)と期待通りの予測結果となりました。
推論APIを公開する
最後に、作成した推論APIを公開して実行できるようにします。今回は簡単のために、利用制限(eg: 認証)をしませんが、実際に自身のAPIを公開される場合はセキュリティを考慮した設計が必要になります。
APIの公開にはGCP(GoogleCloudPlatform)のCloudRunを使用します。
GCP: CloudRunについて
コンテナ化されたアプリケーションをデプロイ可能なサービスです。コンテナの作成には主にDockerが候補に上がります。インフラの構築が必要なく、料金は従量課金で使った分だけ料金が発生するという「ちょっと試してみたい!」という今回のケースにはぴったりです。
Cloud Run: コンテナを秒単位で本番環境にデプロイ | Google Cloud
gcloudコマンドでのデプロイ
作成したサーバーをDockerを使ってコンテナ化します。そのために以下の3つのファイルを用意します。
- Dockerfile
- requirements.txt
- .dockerignore
Dockerfile
|
FROM python:3.9.0-slim RUN apt-get update \ |
requirements.txt
| scikit-learn fastapi uvicorn |
.dockerignore
作成した仮想環境のフォルダを無視するようにします。
| /environments |
これでファイルの用意は整いました。次に作成したDockerfileからイメージをビルドします。
| (environments) $ docker build -t fastapi-predict . |
補足ですがビルドをM1 macで行うと、CloudRunにdeployした際に以下のエラーが表示されました。
| Application failed to start: Failed to create init process: failed to load /bin/sh: exec format error |
ビルドをした際には何のエラーも発生しないので、注意が必要です。
M1 macでビルドをする時はプラットフォームを指定して実行する必要があります。
| docker build -t fastapi-predict --platform linux/amd64 . |
ビルドが完了したら、タグを付与してGCPのContainer Registryにビルドしたイメージをアップロード(push)します。
この際にContainer Registry APIが有効になっている必要があります。またCloud Run APIも有効化しておく必要があるので、この時点で上記2つのAPIが有効になっているかを確認しておきましょう。
| (environments) $ docker tag fastapi-predict asia.gcr.io/プロジェクトID/fastapi-predict:v1 |
タグ付けされたことを確認します。
| (environments) $ docker images | grep "asia.gcr.io" asia.gcr.io/プロジェクトID/fastapi-predict v1 3413694272bb 8 hours ago 653MB |
タグを利用して、Container Registoryにイメージをプッシュします。
| (environments) $ docker push asia.gcr.io/プロジェクトID/fastapi-predict:v1 |

最後にアップロードしたイメージを指定して、ClourRunをサービスをデプロイします。
| (environments) $ gcloud run deploy fastapi-predict --image asia.gcr.io/プロジェクトID/fastapi-predict:v1 --region asia-east1 --platform managed --allow-unauthenticated |
これで、APIの公開が完了しました。
APIを呼び出してみる
デプロイ後、CloudRunの画面を見てみると発行されたサービスのホストが記載されています。
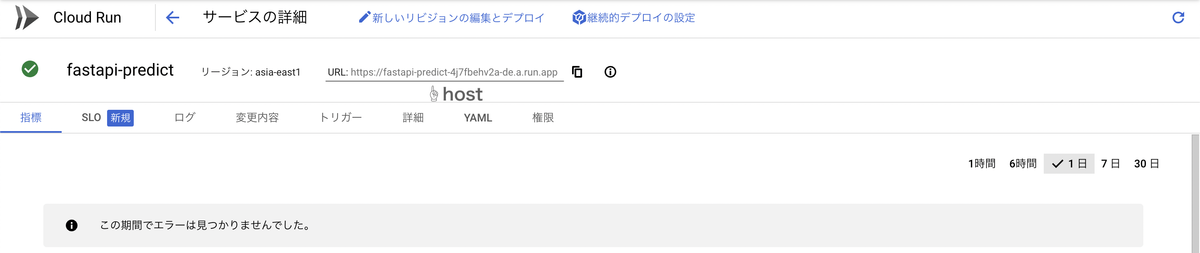 このホストを使って、先ほどlocal環境でcurlを呼び出した際と同じようにデプロイしたAPIを呼び出ししてみましょう。
このホストを使って、先ほどlocal環境でcurlを呼び出した際と同じようにデプロイしたAPIを呼び出ししてみましょう。
| (environments) $ curl -X POST -H "Content-Type: application/json" -d '{"input": [5.9, 3.0, 5.1, 1.8]}' https://fastapi-predict-xxxxxxxxx.a.run.app/predict {"output":2} |
無事、レスポンスを受け取ることが出来ました!!
まとめ
今回は現在、大人気のFastAPIについて紹介とAPIの公開までを行いました。FastAPIは非常に手軽で高速なAPIを作成することが出来る上に、SwaggerUIでのドキュメントの自動生成までも行ってくれます。
実際にはエンドポイントに対応する関数をデコレーターを用いて作成するだけでAPIが作成されました。
また、CloudRunにデプロイしてAPIを公開することも簡単に行うことが出来ました。皆さんもぜひFastAPIを使ってみて下さい。
参考文献
- https://fastapi.tiangolo.com/ja/
- https://www.uvicorn.org/
- https://qiita.com/bee2/items/0ad260ab9835a2087dae
- https://okiyasi.hatenablog.com/entry/2020/08/10/211804
- https://cloud.google.com/run/docs/quickstarts/build-and-deploy?hl=ja#python
