
こんにちは!nakamura(@naka957)です。本記事では、TensorFlowの拡張機能であるTensorFlow Data Validationを用いたデータセット検証を行う方法をご紹介します。
データセット検証とは、機械学習モデルの構築時に使う訓練データと運用データの間の違いを調べることです。訓練データと運用データの性質に違いが存在すると、モデル精度の悪化に繋がります。そのため、構築したモデルの精度監視だけでなく、より前工程となるデータセット時点での検証も非常に重要になります。特に、データセットサイズが大きくなるほど、手作業での検証が困難となるため、効率的で自動化された検証方法が求められてきます。
データセット検証を行うライブラリは様々ありますが、今回は機械学習の実装フレームワークとして特に有名なTensorFlow系のライブラリを用いて行います。
では、早速始めていきます。
TFDVとは
TensorFlow Data Validation(TFDV)は機械学習用のデータセット検証を目的に開発されたPythonライブラリです。Google社が開発しているTensorFlow Extended(TFX)の一部で、TFXは機械学習モデルを運用する本番環境を構築するためのプラットフォームです。
TFDVの機能としては、次が挙げられます。
- Jupyter Notebook環境でも使用可能
- データセットの統計量を計算
- データセットと特徴量ごとに統計量と分布を可視化し、比較が可能
- 訓練データと運用データ間での異常検知やドリフト(drift)・歪度(skew)の検知が設定可能
また、TensorFlowの拡張機能のため、スケーラブルな計算が実行可能です。TFDVに実装されている代表的な手法は公開論文に説明があります。興味がある読者の方は適宜参考にしてみてください。
TFDVでデータセット検証を行う全体像は下図になります。データセット検証は基準としたデータセットと比較することで行います。そのため、最初に基準とする訓練データの統計量を算出し、schema(データセットの特性)を定義します。次に、比較対象となる運用データの統計量を算出し、訓練データのschemaと比較することでデータセット検証を行います。詳細は以降の説で説明していきます。

ライブラリのインストール
以降で紹介するコード例は、Jupyter NotebookもしくはGoogle Colab上での実行を想定しています。また、本記事のサンプルコードではTensorFlowとTFDVが次のバージョンで動作確認をしています。
tensorflow==2.8.0 tensorflow_data_validation==1.7.0
TFDVのインストールが未実施の人は、事前にインストールが必要です。ただし、インストール方法は、ローカル環境とGoogle Colab上で推奨されている方法が異なることに注意してください。
ローカル環境
$ pip install tensorflow-data-validation # バージョンを指定する場合 $ pip install tensorflow-data-validation==1.7.0
Google Colab
!pip install --upgrade pip !pip install --upgrade 'tensorflow_data_validation[visualization]<2'
ライブラリの読み込み
使用するライブラリを事前に読み込んでおきます。
まず、TensorFlowとTFDVを読み込みます。Google Colab上でimportエラーが出た際は、再起動を実行後に再度importしてみてください。
import tensorflow as tf import tensorflow_data_validation as tfdv
次に、残りのライブラリも読み込みます。
import requests import zipfile import io import pandas as pd
データセット準備
今回は自転車シェアリングのデータセットを使用します。このデータセットは、機械学習用のオープンソースのデータセットを数多く収録するUCI Machine Learning Repositoryに収録されています。
なお、Evidentlyの記事で同じデータセットを用いたデータドリフト検知の方法を紹介しています。本記事でも紹介しますが、データドリフト検知もデータセット検証の1つで、紹介した別記事ではEvidentlyのPythonライブラリを用いて実装しています。興味がある方は確認してみてください。
では、データセットをコード上でUCIサイトから直接ダウンロードし、pandasのDataFrameで取得します。ただし、事前にダウンロードし、ローカル環境から直接読み込む場合は、変数dataset_pathにファイル名を含めたCSVファイルのPATHを指定してください。
# ローカル環境から読み込む場合は、ファイルのPATHを指定 dataset_path = None # データセットの取得 if dataset_path == None: url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00275/Bike-Sharing-Dataset.zip" content = requests.get(url).content with zipfile.ZipFile(io.BytesIO(content)) as arc: df = pd.read_csv(arc.open("day.csv"), header=0, sep=',', parse_dates=['dteday'], index_col='dteday') else: df = pd.read_csv(dataset_path) df.head()

目的変数は変数cntで、レンタル回数を表します。また、データセットには2年分の1日ごとのデータが含まれています。期間は2011年1月1日から2012年12月31日です。
データセットは訓練と検証、運用時用の3つに分割します。ただし、運用データには目的変数cntは含まれないため、削除しておきましょう。
# 運用データ - 最後から1ヶ月分 serve_df = df['2012-12-01':'2012-12-31'].drop(columns=['cnt']) # 検証データ - 運用データを除いた、最後から3ヶ月分 val_df = df['2012-09-01':'2012-11-30'] # 訓練データ - 運用・検証データを除いた分 train_df = df[:'2012-08-31']
データセット検証の準備
データセット検証を行う前に、訓練データのschemaを定義する必要があります。schemaとはメタデータに近い概念で、データ特性に相当します。例えば、データ型や値範囲などです。データセット検証は、運用データを訓練データのschemaと比較し、想定した性質のデータか判断する形で行います。
統計量の算出
まず、schemaの定義に必要となる特徴量ごとの記述統計量を算出します。算出後は、可視化して確認してみます。TFDVで対応しているデータセット形式は3種類です。1つ目はpandasのDataFrame型で、残りの2つはファイル形式(CSVとTFRecord)になります。それぞれの形式に応じて使用する機能は以下の通りです。
- tfdv.generate_statistics_from_dataframe(): pandasのDataFrame
- tfdv.generate_statistics_from_csv(): CSVファイル(.csv)
- tfdv.generate_statistics_from_tfrecord(): TFRecordファイル(.tfrecord)
今回はpandasのDataFrame型の変数から算出するため、tfdv.generate_statistics_from_dataframe()を使用します。では、訓練データの統計量を算出しましょう。
# 訓練データの記述統計量を算出
train_stats = tfdv.generate_statistics_from_dataframe(train_df)
算出した各特徴量の統計量の情報は変数train_statsに格納されています。tfdv.visualize_statistics()を用いれば、簡単に可視化できます。
# 訓練データの統計量を可視化
tfdv.visualize_statistics(train_stats)

(注: 一部省略)
上図の通り、特徴量ごとに統計量とその分布が描画されてます。また、欠損値とゼロ値の割合は赤字で示され、視覚的に認識しやすくなっています。
可視化された結果は、変数のタイプ(カテゴリカル・数値型)による特徴量の選択、レイアウト変更(統計量分布の拡大)やグラフ縦軸を対数スケールへ変更することも可能です。下図の赤枠で変更できます。
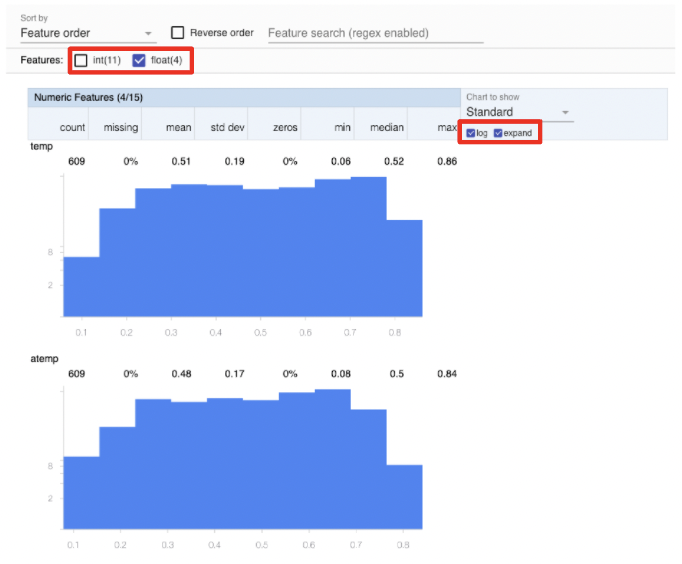
(注: 一部省略)
また、異なるデータセット同士を比較することも可能です。訓練データと検証データを比較してみます。訓練および検証データの統計量と表示される名称をtfdv.visualize_statistics()の引数にそれぞれ指定します。
引数の説明
- lhs_statistics: 対象データの統計量
- rhs_statistics: 比較データの統計量
- lhs_name: 対象データの表示名称
- rhs_name: 比較データの表示名称
ただし、検証データの統計量はまだ算出していないため、先に計算しておく必要があります。下記コードの実行で、訓練および検証データを比較した可視化が実行されます。
# 検証データの記述統計量を算出 val_stats = tfdv.generate_statistics_from_dataframe(val_df) # 訓練および検証データの統計量を比較して可視化 tfdv.visualize_statistics( lhs_statistics=val_stats, rhs_statistics=train_stats, lhs_name='val', rhs_name='train', )

(注: 一部省略)
上図右側のデータ分布では、一見、訓練データ(オレンジ色)と検証データ(青色)間で分布の性質が大きく異なるようにみえます。これは縦軸が出現回数のため、データ数の違いで見え方が異なるためです。統計的な性質の違いは、平均値や分散、欠損値の比率などで判断が必要です。
schemaの定義
schemaとは、簡単に説明すると、データの標準的な特性に相当します。例えば、データ型や値の範囲などです。
schemaを定義する理由は、データセット検証を訓練データのschemaを基準とし、検証データや運用データとの比較で行うためです。上記の理由から、schemaは訓練データで定義する必要があります。
データセットのschemaはtfdv.infer_schema()で簡単に推測できます。
# 訓練データのschemaを推測 schema = tfdv.infer_schema(statistics=train_stats) # 訓練データのschemaを表示 tfdv.display_schema(schema)
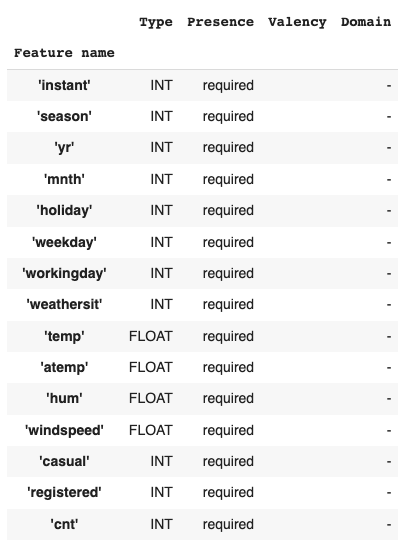
まず、変数のDomain情報を追加してみます。Domain情報とは、数値変数の場合は変数の取りうる範囲で、カテゴリカル変数の場合は値の種類(ex. 文字列など)に相当します。
例として、変数seasonにDomain情報を追加してみます。変数seasonは1~4の値を取り、それぞれが春から冬までに対応しています。そのため、1~4以外の数値の場合はデータが誤りとなり、異常検知される必要があります。Domain情報を追加するには、tfdv.set_domain()とTensorFlow MetaDataのschema_pb2の機能を用いると便利です。次のように値を1~4へ設定ができます。
from tensorflow_metadata.proto import schema_pb2 # 'season'列の想定する値範囲を1 ~ 4に設定 tfdv.set_domain(schema, 'season', schema_pb2.IntDomain(name='season', min=1, max=4)) # 変更後の訓練データのschemaを表示 tfdv.display_schema(schema)

変数Typeの修正は変数schemaの内部要素を直接書き換えます。内部要素はtfdv.get_feature()で参照できます。
まず、目的変数cntを例に、schemaの内部要素を確認してみます。
print(tfdv.get_feature(schema, 'cnt'))

変数名の’name’、変数型の’type’、想定されるデータの数・割合の’presence’、データ形状のshapeが含まれています。
練習のため、typeをINTからFLOATへ変更してみます。まず、typeを参照し、確認してみます。
print(tfdv.get_feature(schema, 'cnt').type) # >> 2
出力結果はINTではなく、数字の2となりました。実は、2がINTを表しています。FLOATは3で表され、下記でINTからFLOATへ変更できます。
""" Type: 1: BYTES 2: INT 3: FLOAT 4: STRUCT """ tfdv.get_feature(schema, 'cnt').type = 3 print(tfdv.get_feature(schema, 'cnt'))

上記の結果から、変数cntのtypeがFLOATへ変更されたことが確認できます。このように、修正は逐次内部要素を直接書き換える必要があります。
ここまでで、訓練データの統計量の算出とschema(データ特性)の定義が完了しました。以降では、データセット検証である、異常検知やドリフトと歪度の検知を行っていきます。
データセット検証
データセット検証は、訓練データで定義したschemaを用いて行います。まず、検証・運用データでデータセット検証を行います。次に、実際の運用時を想定し、不要な異常検知がされない形へschemaの修正をします。最後にデータドリフトと歪度の異常検知も追加します。
schemaに基づく異常検知
データセット検証の最初として、異常検知を行います。検知基準は、訓練データのschemaからのズレで判断します。ただし、各特徴量ごとのズレの閾値は運用者が判断して設定する必要があります。
閾値の決め方には決まったルールはなく、個々の問題に依存します。機械学習モデルの効果的な運用を目指して、閾値を試行錯誤しながら決める場合が多いです。
まず、検証データを対象に異常検知を実施してみます。
# 異常検知の実行 anomalies = tfdv.validate_statistics( statistics=val_stats, schema=schema, ) # 異常検知結果の表示 tfdv.display_anomalies(anomalies)

異常は検知されない結果となりました。
次に、運用データを対象に異常検知を実施します。ただし、運用データの統計量はここまでで未算出のため、事前に計算が必要です。
# 運用データの記述統計量を算出 serve_stats = tfdv.generate_statistics_from_dataframe(serve_df) # 異常検知の実行 anomalies = tfdv.validate_statistics( statistics=serve_stats, schema=schema, ) # 異常検知結果の表示 tfdv.display_anomalies(anomalies)

今回は異常が検知されました。「運用データに変数cntが存在しない」と警告がでています。
schemaの修正
前節で、「運用データで目的変数cntが存在しない」と異常検知されました。一方で、実際の運用時では訓練時と異なり目的変数は含まれません。目的変数がないことが異常とみなされると不都合なため、schemaを修正することで対応する必要があります。
修正はschema環境の設定で実施できます。次の手順で設定できます。
- 訓練・検証・運用データの環境を全ての変数を含む形でそれぞれ定義する
- 運用データの場合のみ目的変数cntを除外する
# デフォルトで全ての特徴量を含め定義 schema.default_environment.append('train') schema.default_environment.append('val') schema.default_environment.append('serve') # 運用データのみ目的変数'cnt'を除外 tfdv.get_feature(schema, 'cnt').not_in_environment.append('serve')
以上で、schemaの環境設定が完了しました。再び、運用データを対象に異常検知を実施しましょう。問題なく設定されていれば、異常が検知されない結果となります。ただし、運用データのschema環境を指定するために、引数environmentに’serve’を渡すことに注意してください。
# 再度、異常検知を実行 anomalies = tfdv.validate_statistics( statistics=serve_stats, schema=schema, environment='serve', # 運用データの場合のschemaを指定 ) # 異常検知結果の表示 tfdv.display_anomalies(anomalies)

データドリフト(drift)と歪度(skew)の追加
データセット検証として、次にドリフト(drift)と歪度(skew)の検知を行います。ただし、TFDVは歪度に関しては、3種類に分けて検知します。
- schema skew: 比較するデータ間のschemaの違い。例えば、訓練データに存在しないラベルが運用データに含まれている場合など。
- Feature skew: データ値に関わる違い。例えば、運用データでスケール変換が未実施の場合など。
- Distribution skew: データ間の分布の性質の違い。
TFDVでは閾値の指標として、カテゴリカル変数にはL-infinity distanceが、数値変数にはJensen-Shannon divergenceが用意されています。特量量それぞれに閾値を設定することで、閾値を超えた際に警告を受け取ることが可能となります。
ここでは、変数workingdayにデータドリフトの閾値を、変数windspeedに歪度の閾値を指定してみます。
# 変数'registered'に対して、データドリフトの閾値を指定 workingday = tfdv.get_feature(schema, 'workingday') workingday.drift_comparator.jensen_shannon_divergence.threshold = 0.0001 # 変数'windspeed'に対して、歪度の閾値を指定 windspeed = tfdv.get_feature(schema, 'windspeed') windspeed.skew_comparator.jensen_shannon_divergence.threshold = 0.01
異常検知を実行してみます。閾値を指定した変数については、データドリフトと歪度についても異常検知が実施されます。
# 指定した変数のデータドリフトと歪度を考慮した異常検知を実行 skew_drift_anomalies = tfdv.validate_statistics( train_stats, schema, previous_statistics=val_stats, serving_statistics=serve_stats, ) # 結果の可視化 tfdv.display_anomalies(skew_drift_anomalies)

変数workingdayとwindspeedの両方で異常検知がされた結果となりました。また、変数cntでFLOAT型が想定されている一方で、INT型が検出されたとでています。これは、記事内でschemaを意図的に修正したためです。
実際の運用では、結果をもとに予測への影響を調査し、適切な閾値の設定に繋げることが重要になってきます。この工程を試行錯誤することで適切な閾値の設定に繋げ、機械学習モデルの効果的な運用に役立てることが可能です。
まとめ
TFDVによるデータセット検証の方法をご紹介しました。機械学習モデルの構築で用いる訓練データを基準に、検証および運用データの検証を行いました。
それぞれの記述統計量を算出し、可視化と比較を簡単に行うことができました。また、データドリフトや歪度を含めた異常検知も実施しました。
TFDVは機械学習モデルを実際に運用する段階で役立つPythonライブラリです。是非試してみてください。
参考文献
- https://github.com/tensorflow/data-validation
- https://github.com/tensorflow/data-validation/blob/master/g3doc/get_started.md
- https://mlsys.org/Conferences/2019/doc/2019/167.pdf
- https://www.tensorflow.org/tfx
