
こんにちは!nakamura(@naka957)です。今回は、教師なし学習をご説明します。
機械学習では、学習データに正解情報が含まれている教師あり学習への注目が多いかもしれません。一方で、学習データに正解情報を含まない教師なし学習も存在します。教師なし学習は学習データに正解情報なしで、データ自身のパターンを推測する手法です。
皆さんの手元にあるデータも、正解情報がなくとも、教師なし学習の活用で新しいパターンが見えてくるかもしれません。
本記事では、教師なし学習とその主要な手法の概要を理解することを目指します。
では、早速始めましょう。
教師なし学習とは
機械学習はデータに潜む関係性を推定する方法です。
教師あり学習は、入力データ(説明変数)と予測対象(目的変数)の関係性をデータから推定する手法です。学習データに説明変数と目的変数(正解情報)を両方含む点が特徴です。学習データから推定した関係性を用いて、未知データの説明変数から目的変数を予測する形で活用します。
教師なし学習は、入力データ(説明変数)のみでデータに潜む関係性を推測する手法です。学習データに正解情報が含まれない点が大きな特徴であり、教師あり学習と異なる点です。説明変数内の関係性を抽出し、類似性や情報縮約などを行う形で活用します。
教師あり学習との違い
教師あり学習との違いを具体的な例で説明します。ここでは、犬と猫の絵を判別する状況を考えてみます。
教師あり学習では、絵と正解ラベルのデータから関係性を推測し、新しい絵の正解ラベルを予測します。下図のように、絵の説明変数x1とx2および正解ラベル(猫と犬)の情報から関係式(図中の紫色線)を推定し、関係式に基づき未知の絵(紫色の円)を予測します。
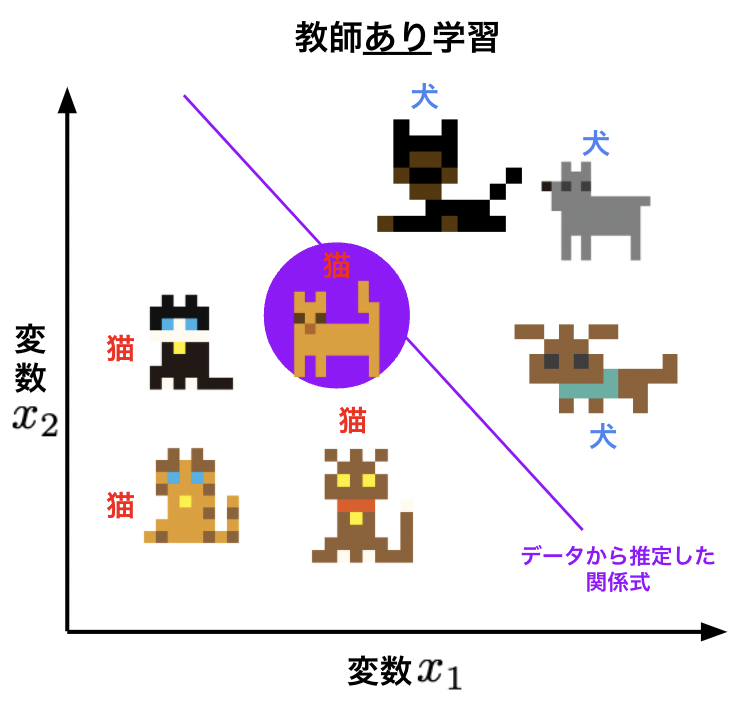
猫と犬の絵は前田デザイン室 DOTOWNを使用
https://dotown.maeda-design-room.net/
教師なし学習では、正解ラベルがない絵のみでモデルを学習します。それぞれの絵から類似性や情報縮約により情報を抽出します。下図では、抽出した類似性に基づき、グループA(猫)とグループB(犬)にグループ化した場合を表しています。
未知の絵(紫色の円)に関しても、算出した類似性からグループAに分類されています。類似性の算出方法は、後述のクラスタリング節で登場するk-means法が代表的な手法です。

猫と犬の絵は前田デザイン室 DOTOWNを使用
https://dotown.maeda-design-room.net/
教師なし学習の手法
主要な手法は次の2つです。
- クラスタリング
- 主成分分析
クラスタリングはデータを類似性に基づき、グループ化する手法です。主成分分析は、多数の特徴量の情報を少数の特徴量に縮約する手法です。高次元データを次元圧縮する手法として有名です。
データ分析の現場では、クラスタリングや主成分分析が頻繁に登場します。以降の節で、2つの手法の詳細をご説明しますので、特に機械学習の初心者は概要の理解を目指してみてください。きっと役立つはずです。
クラスタリング
クラスタリングはデータから類似性を抽出し、類似のグループへ分類する手法です。グループのことをクラスターと呼びます。類似性を算出する方法は色々と考えられますが、代表的な方法としてk-means法をご紹介します。
k-means法は、データの重心点を設定し、重心点からの距離を類似度とみなす手法です。距離が近いほど類似度が高くなります。クラスタリングは、クラスター数に応じた重心点を設定し、距離に基づきグループ化することで行われます。
教師なし学習と言えども、クラスター数や重心点の定義(ex. 平均値や中央値)は分析者自身が決める必要があります。
k-means法によるクラスタリング(グループ化)の手順は、以下の手順を繰り返す形になります。
- 各点を重心との距離が最も近いクラスターに所属させる
- 各クラスターの重心位置を再計算する
- 新しい重点位置を用いて、各点の所属クラスターを再計算する
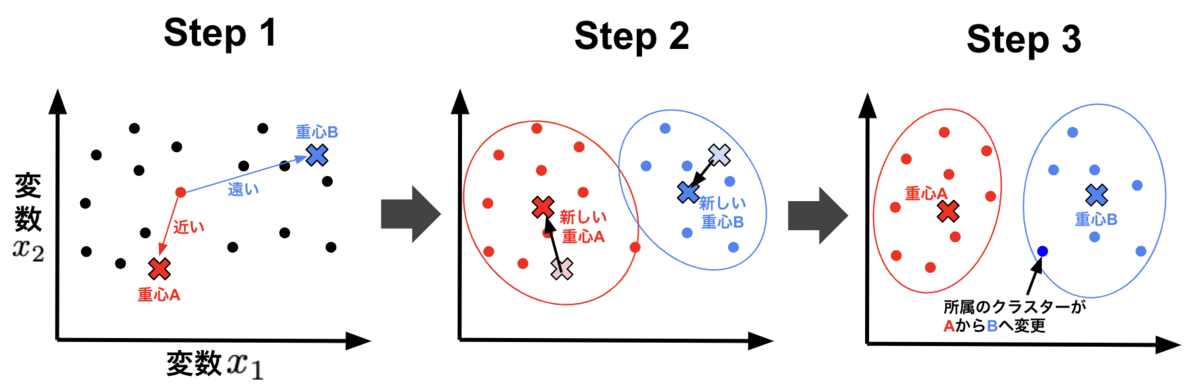
各クラスターの重心点の初期位置はランダムに設定する場合が一般的です。そして、上記のStep 1–3の手順を、各点の所属クラスターの変化がなくなるまで繰り返します。最終的に所属したクラスターが得られた分類結果となります。
一見、単純な方法ですが、データ自身に構造が潜んでいる場合には有効な場合がしばしばあります。特に重要な特徴量を用いてクラスタリングした場合では、猫と犬のような分類がみえる場合があります。
主成分分析
主成分分析は、多数の特徴量のデータセットを少数の特徴量で表現することを指します。そのため、高次元データを次元圧縮する手法として有名です。
具体的には、データを表現する軸(ex. x-y座標軸)を取り直すことに相当し、次の手順で主成分の軸方向を決めていきます。
- データのばらつきが最も大きい方向に第1主成分の軸を定義
- 第2主成分を第1主成分軸と直交し、ばらつきが最も大きくなる方向に定義
- 第3主成分以降も同様に、定義済みの主成分軸と直交方向かつデータばらつきが最大の方向に定義
2次元データの例を下図に示します。第1主成分の軸方向は赤色矢印で、第2主成分の軸方向が青色矢印で表されています。第1主成分(赤色)方向が最もデータのばらつきが大きいことがわかります。言い換えれば、第1主成分軸は良くデータを表現できることに相当します。

データのばらつきが大きい方向に軸を取り直す理由は、ばらつきが大きいデータほど情報が多いとみなせるからです。
簡単な例で考えてみます。例えば、ある町の年齢分布と性別を調査した場合を考えます。極端ですが、ある町の住民全員の年齢が20代で、男女比率が同程度の結果であった場合、情報量が多いと言えるでしょうか?その傾向が、他の年齢層で同じかどうかの判断ができません。
一方で、10代や20代では男女比率が同程度だが、70代や80代では女性の比率が大きくなる場合では、情報量はより多いとみなせます。年齢層が上がることで、男女比率が変化する原因があるかもしれません。
データの可視化は、データセットの理解を深めるために非常に有用です。しかしながら、人間は3次元までしか視覚的に認知できないため、高次元データの理解は難しくなります。
主成分分析は、高次元データを低次元で表現できるため、高次元データを可視化し、全体の傾向を把握したい際に威力を発揮します。例えば、第1主成分と第2主成分を用いて可視化することが顕著な例です。
活用事例
最後に教師なし学習の活用事例をご紹介します。
手書き数字画像
手書き数字の画像データセットで有名なMNISTを題材にします。MNISTは0から9までの手書き画像のデータセットで、無料で公開されています。

今回は簡単のため、数字が0, 1, 2の画像のみを対象とし、教師なし学習を適用した結果をご紹介します。
実施した分析手順は次の通りです。
- MNISTに主成分分析を適用し、画像データを次元縮約
- 次元縮約後の第1および第2主成分に対して、k-means法でクラスタリング
- 横軸と縦軸をそれぞれ第1・第2主成分とし、ラベルをクラスタリング結果で可視化
下図の左側がクラスタリング後の結果になります。クラスリング結果のラベルで色分けし描画しています。また参考のため、右図に正解ラベルで色分けした結果を描画しています。

いかがでしょうか。正解情報なしでも、それなりの精度で分類できています!データに潜む構造を反映できているとも言えます。
以上が、教師なし学習でデータに隠れた構造を推定した例でした。データの構造を明らかにすることは、その後の教師あり学習を実施する際にも有効になります!
まとめ
ここまで教師なし学習の概念を説明してきました。
教師なし学習は正解情報なしで行うデータ分析手法で、代表的な手法にクラスタリングや主成分分析があります。クラスタリングはデータから類似性を抽出し、類似のグループへ分類する手法です。主成分分析は、高次元データを次元圧縮する手法です。
データに潜む構造を推定する方法として教師なし学習は有効です。具体的な分析手法を別の記事でご紹介しますので、是非そちらも参考にしてみてください。
参考
- https://dotown.maeda-design-room.net/
- https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
