
こんにちは、DATAFLUCTのSaiです。
今回は機械学習には欠かせないデータについて解説します。
データにはどんな種類があるかということと、
機械学習する際にデータをどのように扱う必要があるかを一緒に見ていきましょう。
データの種類
データには次の4種類があります。
1.数値データ
項目と数値のみで、機械学習で最も扱いやすいデータになります。
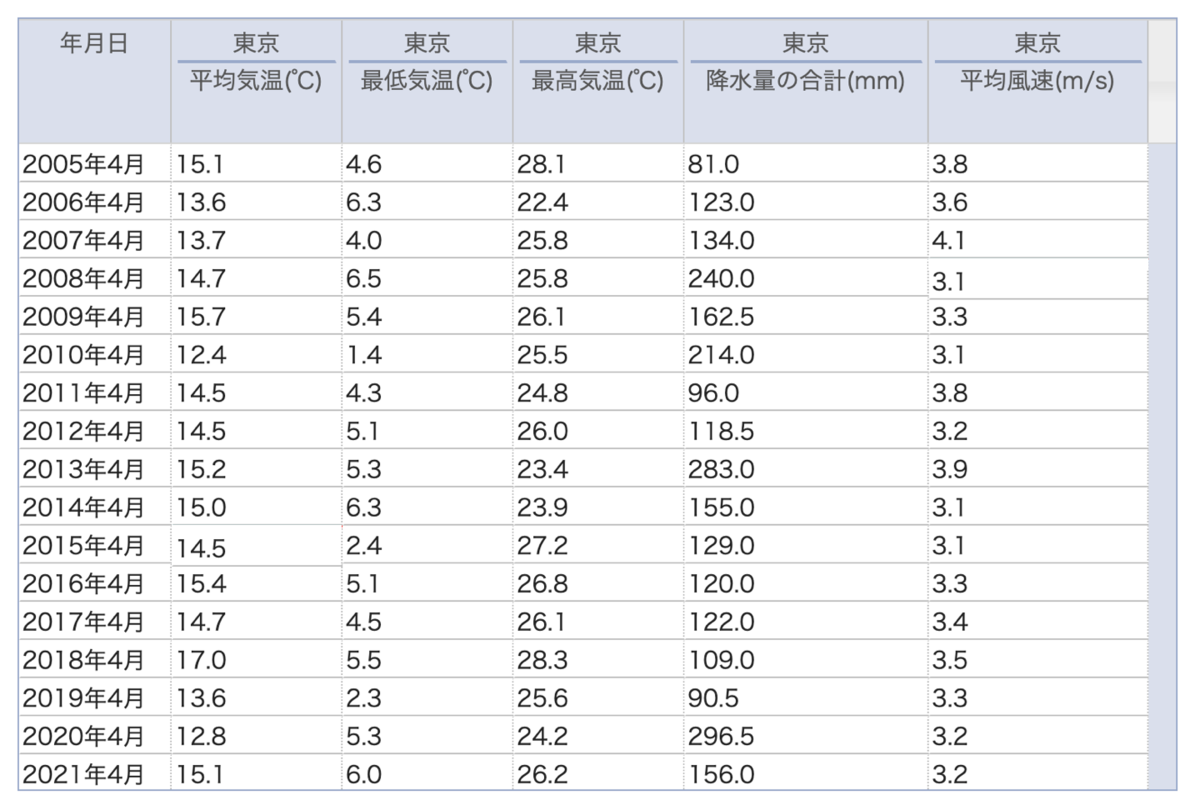
例えば、右は東京の2005~2021年の4月の気象データになりますが、この過去の気象データをもとに将来の数値つまり2022年4月の平均気温や降水量を機械学習で予測したりできます。
2.画像データ
写真や動画といったものが画像データになります。右の猫の写真を使った場合、機械学習で画像解析することで何が写っているか(答えは猫)、猫が何匹いるかを予測することができます。

3.音声データ
日本語や英語といった話し言葉や、音楽なども音声データになります。機械学習では右のサンプルの音声を、例えば女性のような高い声に変換したり、話している内容を要約することができます。
4.テキストデータ
日本語や英語といった書き言葉になります。文章を機械学習では要約したり、たくさん学習すれば作家のオリジナル作品に似た小説を書いたりもできます。もっと身近なものですと、ある程度パターンが決まっているチャットボットで自動に返信することができます。
青空文庫「坊ちゃん」 より
坊っちゃん
夏目漱石親譲《おやゆず》りの無鉄砲《むてっぽう》で小供の時から損ばかりしている。小学校に居る時分学校の二階から飛び降りて一週間ほど腰《こし》を抜《ぬ》かした事がある。なぜそんな無闇《むやみ》をしたと聞く人があるかも知れぬ。別段深い理由でもない。新築の二階から首を出していたら、同級生の一人が冗談《じょうだん》に、いくら威張《いば》っても、そこから飛び降りる事は出来まい。弱虫やーい。と囃《はや》したからである。小使《こづかい》に負ぶさって帰って来た時、おやじが大きな眼《め》をして二階ぐらいから飛び降りて腰を抜かす奴《やつ》があるかと云《い》ったから、この次は抜かさずに飛んで見せますと答えた。
...
小まとめ
これら4種類のデータは私たちの周りにはあふれています。
普段使っているスマホやテレビ、パソコンでは画像や動画、音声、テキストといったものばかりで、普通に生活していればデータに関わらない人はまずいないかと思います。その中でも数値データでイメージできるものは意外と少ないです。例えばネットショッピングの購買履歴も「いつ」「何を」「いくつ」「いくらで」買ったかのデータも数値データです。企業はこれまで数値データを保存して使ってきましたが、もっとビジネスを発展させるために、例えば商品の画像データも積極的に使う必要が出てきているのです。(フリマサイトの海賊品検出などがその一例になります)
さて、実は画像や音声、テキストといったデータを機械学習でも使っていくことになるのですが、これらのことを非構造化データと言います。それに対して、数値データのような、いわゆる表で表せるデータのことを構造化データと言います。これらについては次で見ていきましょう。
構造化データと非構造化データについて
- 構造化データ
- 数値データ
- 非構造化データ
- 画像データ
- 音声データ
- テキスト(自然言語)データ
構造化データというのは、次のような表として表現できるものを言います。
「降水量」や「気温」という項目名と実際に記録した「降水量」や「気温」の数値は、表としてまとめることができ、これを構造化データと言います。機械学習ではそのまま扱うことができるのがポイントです。
一方、画像や音声といった非構造化データは数値ではありませんし、表として表現することができません。機械学習ではそのまま扱うことができないため、何らかのデータ変換処理をしてあげる必要があります。
画像、音声、テキストはそれぞれ異なるデータ変換をするのですが、次ではテキストのデータ変換を例として見てみましょう。
非構造化データのデータ変換
非構造化データを機械学習が扱えるようにデータ変換するのを、試しに夏目漱石の「坊ちゃん」のテキストでやってみます。
| 親譲りの無鉄砲で小供の時から損ばかりしている。小学校に居る時分学校の二階から飛び降りて一週間ほど腰を抜かした事がある。 |
このままではコンピュータは読めないので、まず単語ごとに区切ることをします。
(これを専門的には形態素解析と言います)
| 親譲り / の / 無鉄砲 / で / 小供 / の / 時 / から / 損 / ばかり / して / いる / 。 / 小学校 / に / 居る / 時分 / 学校 / の / 二階 / から / 飛び降り / て / 一週間 / ほど / 腰 / を / 抜かした / 事 / が / ある。 |
このように、各単語ごとに区切りました。次に単語ごとにIDを振っていきます。
| 0 / 1 / 2 / 3 / 4 / 1 / 5 / 6 / ... |
単語は前から順に0からIDを振っていき、同じ単語は同じIDにします。
ここでは、2番目の単語「の」と6番目の「の」は同じID「1」を振ることになります。
全ての文章を最後まで単語ごとに区切り、IDという数値を振ることでコンピュータは処理できるようになるのです。
最後に
ここまで、データについての種類と構造化・非構造データについて説明してきました。非構造化データについてはそのままでは機械学習することができないので変換する必要があることも理解できたかと思います。
機械学習を学ぶ上で「前処理」という言葉が出てきますが、この変換をする一連の工程を(学習する前にという意味で)「前処理」と言います。機械学習はこの「前処理」をしてあげる必要があるということがイメージできたのではないかと思います。ただし、「前処理」では非構造化データの変換だけでなく、構造化データの加工も行いますので、詳しくは今後の記事で述べたいと思います。
さいごに、非構造化データも変換してあげることで機械学習できるようになるということでしたが、毎回学習する度に「前処理」で変換するものなのか?に疑問を感じる人がいましたら、素晴らしい疑問点になります!
実はデータを溜める時点で何らかの変換処理も行ってから溜めるようなデータ基盤こそが、もっと機械学習を便利に効果的に利用することにつながります。こちらについて、DATAFLUCTでは高い技術力を持って本質的なデータ活用を推進していく組織ですので、データ基盤のプロダクトに力も入れており、興味を感じましたら弊社のプロダクトをチェックしてみてください。
またデータ基盤についての記事も鋭意執筆中ですのでご期待ください。
▼DATAFLUCTのプロダクトについてはこちら
プロダクト情報
