
こんにちは!nakamura(@naka957)です。今回は機械学習モデルの運用時で特に問題となるドリフトを検知するOSSをご紹介します。
本番環境のモデル精度が低下する現象をドリフトと呼びます。特にデータ由来をデータドリフトと呼びます。
機械学習はデータから入力情報と予測対象の関係性を推定する手法です。そのため、前提となる入力情報の性質が変化すると(データドリフト)、予測精度が低下します。
データドリフトの検知は機械学習のサービスを運用する上で非常に重要ですが、ドリフト検知を含まない機械学習プロジェクトも多いのではないでしょうか。
本記事では、ドリフト検知が簡単にできるPythonライブラリのEvidentlyをご紹介します。Evidentlyを使えば、簡単にドリフト検知が可能です。
では、本題に入っていきましょう。
データドリフトとは
収集されるデータの性質が変化することをデータドリフトと呼びます。
データの性質の変化は、定量的には統計量(平均や標準偏差)で評価できます。直感的には、データ分布の形状が変化することを想像してください。下図のように、分布のピーク数が訓練と本番データ間で異なれば、データドリフトが発生したとみなせます。機械学習では入力データと予測対象の関係性を訓練データから推定するため、予測時点で訓練データと性質が異なると、上手く予測できなくなります。

Evidently
Evidentlyはドリフト検知を簡単に行えるPythonライブラリです。オープンソースのため、誰でも無料で使用できます。
本番環境へデプロイした機械学習モデルについて、大きく次の3つの項目を評価する機能があります。ただし、Evidentlyは現在も精力的に開発が行われているため、将来的には更なる機能拡張がされるかもしれません。
- データドリフト
- ターゲットドリフト
- モデル評価
これらの機能を用いて、本番環境モデルのモニタリングを簡単に行えます。なお、本記事ではデータドリフトの実装例をご紹介します。
一般的な機械学習プロジェクトの全体ワークフローは、下図の緑色四角の項目で構成された、データ準備・前処理と特徴量抽出・モデル訓練・精度評価・本番環境へのデプロイの流れになります。これに加えて、赤色四角の項目で示す、本番環境での運用とドリフト検知も含めることが本記事の目的です。この結果、精度維持のための再学習の機会を定量的に判断することが可能となります。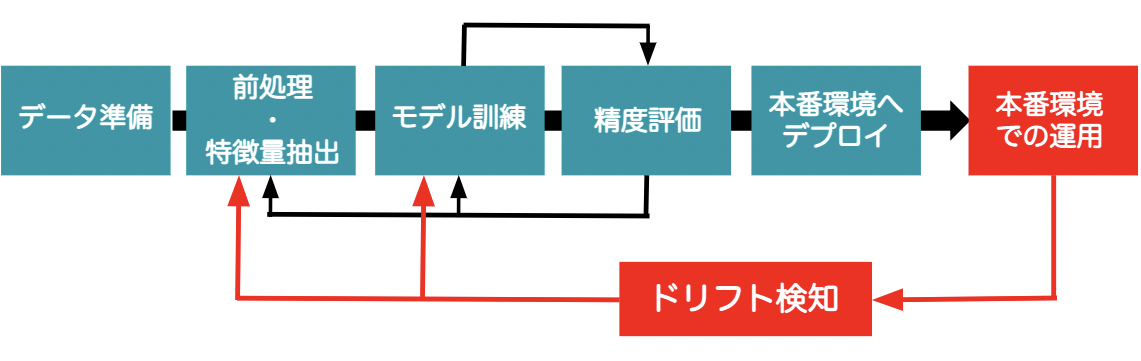
では、Evidentlyを実際に使用し、データドリフト検知を行ってみましょう!
データセットとモデルの準備
最初にデータセットを準備します。今回は自転車シェアリングのデータセットを使用します。このデータセットは、機械学習用のオープンソースのデータセットを数多く収録するUCI Machine Learning Repositoryに収録されています。
UCIサイトから直接ダウンロードし、pandasのDataFrameで取得します。
import requests import zipfile import io import pandas as pd content = requests.get("https://archive.ics.uci.edu/ml/machine-learning-databases/00275/Bike-Sharing-Dataset.zip").content with zipfile.ZipFile(io.BytesIO(content)) as arc: raw_data = pd.read_csv(arc.open("day.csv"), header=0, sep=',', parse_dates=['dteday'], index_col='dteday') raw_data.head()

目的変数は’cnt’で、レンタル回数を意味します。
target = 'cnt'
また、モデルの学習で使用する説明変数を指定しておきます。
features = [
'season',
'holiday',
'workingday',
'weathersit',
'temp',
'atemp',
'hum',
'windspeed',
'weekday',
]
そして、データセットを参照データ(訓練用)と検知対象データ(本番用)に分けておきます。ただし、今回のデータセットは時系列データです。ランダムにデータ順を入れ替えた分割では、時系列を考慮した分析ができなくなります。そのため、データ順で2分割することで時系列順を反映した分割にします。
ref_data = raw_data[:350] # 参照データ prod_data = raw_data[350:] # 検知対象データ
以上で、データセットの準備は整いました。
次に、機械学習モデルを作成します。今回はランダムフォレストを使用します。モデルインスタンスを作成後、データセットを渡し、訓練させます。
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(random_state = 0) model.fit(ref_data[features], ref_data[target])
これで学習済みの機械学習モデルが準備できました!
次から、本題のデータドリフト検知を行っていきます。
データドリフトのレポート出力
参照データと検知対象データ間のデータドリフト検知を行っていきます。Evidentlyを用いれば簡単にレポート結果を出力することができます。
Evidentlyをインストールしていない方は、pipもしくはcondaコマンドでインストールできます。
$ pip install evidently
レポート出力までは、以下のステップで行います。
- Columns mappingの指定
- Dashboardの定義
- 検知の実行
- レポートの出力
Columns mappingの指定
特定の役割の変数を指定します。例えば、目的変数・予測結果・時系列情報などが該当します。
ColumnMappingモジュールで指定します。引数の説明は次の通りです。
- id: ID列として扱う列名
- datetime: 時系列(年月日時)として扱う列名
- target: 目的変数の列名
- prediction: 予測結果の列名
- numerical_features: 数値変数の列名。リスト型で指定。
- categorical_features: カテゴリカル変数の列名。リスト型で指定。
データドリフトの場合、id・target・predictionの列は必要ありません。そのため、指定することでレポート結果から自動的に除外されます。一方で、datetimeはどちらでも構わないため、指定した場合のみレポート結果に含まれます。
今回は、目的変数(target)・数値変数(numerical_features)・カテゴリカル変数(categorical_features)を指定します。
from evidently.pipeline.column_mapping import ColumnMapping # 数値変数 numerical_features = ['temp', 'atemp', 'hum', 'windspeed', 'weekday'] # カテゴリカル変数 categorical_features = ['season', 'holiday', 'workingday', 'weathersit'] # Column mapping column_mapping = ColumnMapping( target = 'cnt', numerical_features = numerical_features, categorical_features = categorical_features, )
ここで注意点を1点述べます。ドリフト検知は数値以外の変数(ex. 文字列など)では行われません。そのため、カテゴリカル変数でドリフト検知を行う場合は、事前に数値型へ変換が必要です。代表的な処理方法としては、OneHotEncodingやLabel encodingが挙げられます。
Dashboardの定義
ドリフト検知の実行とレポート結果は、Dashboardを通じて作成・出力します。
Dashboardモジュールの引数tabsには、レポート種類を指定します。引数tabsへ渡す、Dashboardの種類は次の通りです。
- DataDriftTab: データドリフト
- NumTargetDriftTab: 回帰問題のターゲットドリフト
- CatTargetDriftTab: 分類問題のターゲットドリフト
- RegressionPerformanceTab: 回帰モデルのパフォーマンス結果
- ClassificationPerformanceTab: 分類モデルのパフォーマンス結果
- ProbClassificationPerformanceTab: 確率的識別モデルのパフォーマンス結果
今回はデータドリフト検知が目的のため、DataDriftTabを指定します。また、引数のverboseは出力レベルの詳細指定で、0が簡略出力モード、1がフル出力モードです。
from evidently.dashboard import Dashboard from evidently.dashboard.tabs import DataDriftTab # Dashboardの作成 drift_dashboard = Dashboard( tabs = [DataDriftTab(verbose_level=1)] )
検知の実行
作成したdashboardのcalculateメソッドに、参照データと検知対象データ、column mappingを渡すことで、データドリフト検知が実行できます。
# 実行
drift_dashboard.calculate(
ref_data,
prod_data,
column_mapping = column_mapping,
)
レポートの出力
最後にデータドリフトの検知結果をレポート出力します。showメソッドで出力できます。
# レポート出力 drift_dashboard.show(mode='inline')
次のように説明変数ごとの結果が得られます!
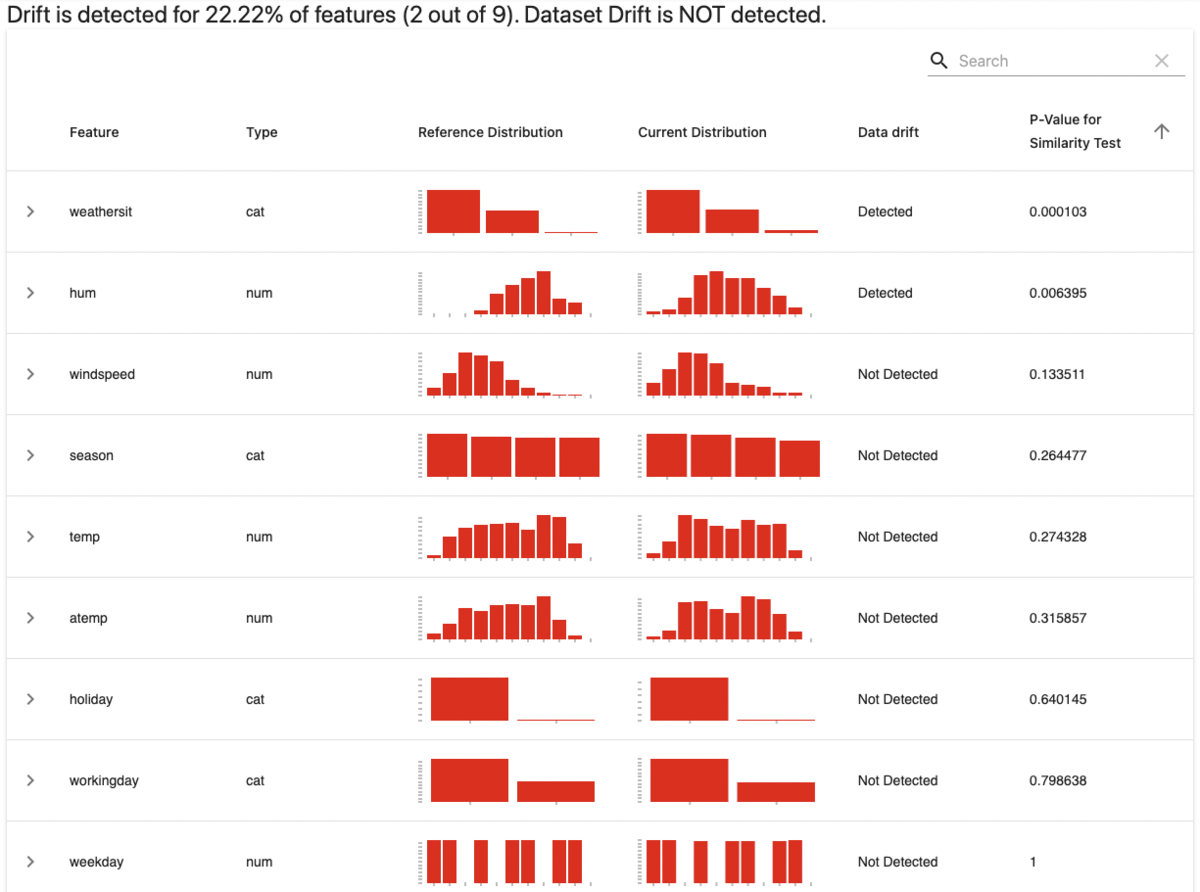
レポートの表上のメッセージとData drift列から、2つの説明変数(weathersit, hum)でデータドリフトが検知されたことがわかります。一方で、データセット全体としてはデータドリフト検知に至らない結果となりました。
ただし、Evidentlyはデータドリフト有無を提案してくれますが、実際の運用上では分析結果をもとに最終的に人が判断することが重要です。例えば、収集データに間違いが発生している場合は、小さなドリフトでも修正が必要です。一方で、ある程度のドリフトでもモデル精度の低下が小さければ、再学習は必要ない場合もあります。最終的には、機械学習モデルの活用目的に応じた判断が必要になってきます。
レポートの内容確認
データドリフトが検知された2つの変数(weathersit, hum)について、レポート内容を確認してみます。
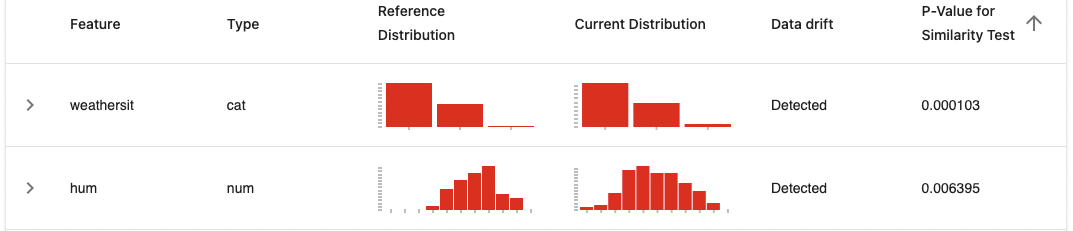
各特徴量をクリックすると、出力結果の詳細を確認できます。
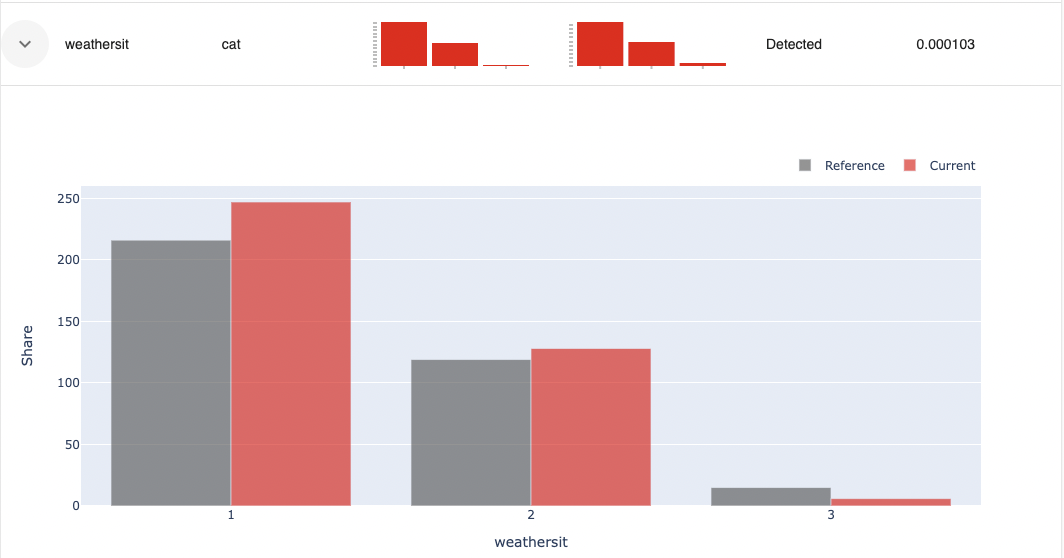
まず、変数weathersitを確認します。変数タイプがカテゴリカル(cat)の場合、レポート内容はカテゴリごとの頻度分布になります。灰色が参照データで、朱色が検知対象データを表します。
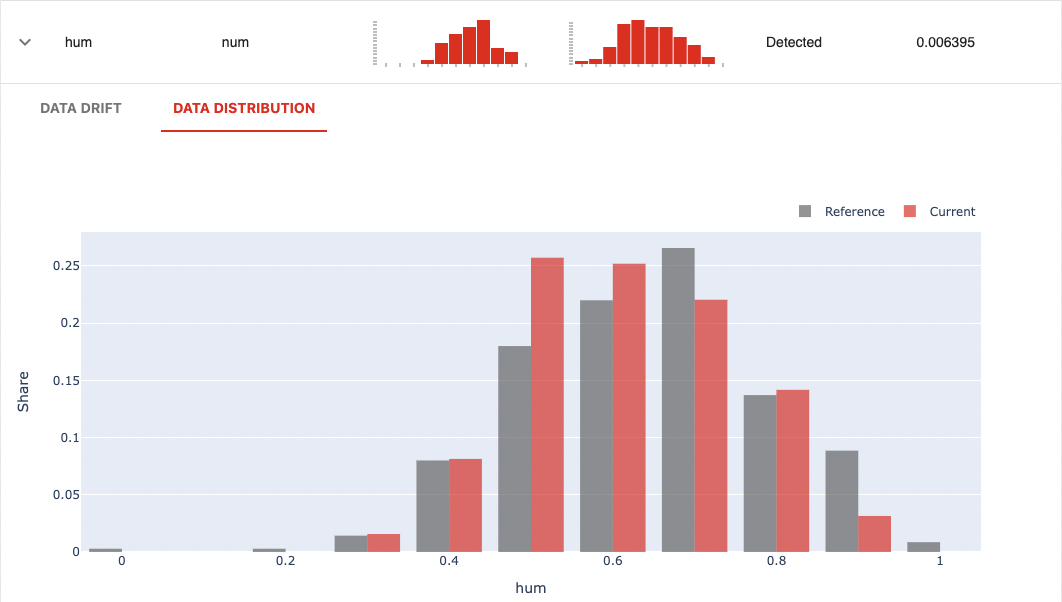
次に、変数humを確認します。変数タイプが数値型(num)のため、レポート内容はデータドリフトとデータ分布の2種類が出力されます。
データドリフト
緑色太線が参照データの平均値を示し、緑色領域が平均値から標準偏差の範囲を表しています。Currentで示される検知対象データは、それなりのデータ数で標準偏差を超えるばらつきが確認されます。
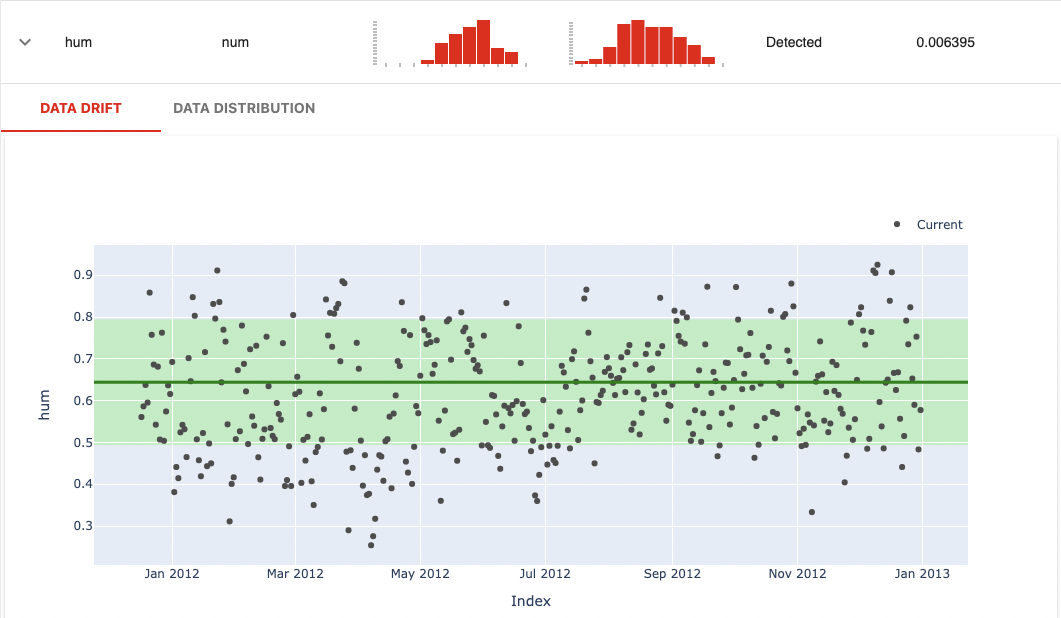
データ分布
ヒストグラム形式の頻度分布です。灰色が参照データで、朱色が検知対象データを表します。分布から形状に変化(ピーク位置など)がみられており、データドリフトの傾向が確認できます。
以上が、Evidentlyを用いたデータドリフトのレポート内容確認でした!
大きな特徴として、レポート結果から視覚的にデータドリフトの傾向を確認できる点が挙げられます。他の説明変数も同様に確認できますので、是非確認してみてください。
まとめ
Evidentlyでデータドリフト検知を行いました。とても簡単に行えることを実感頂けたでしょうか。
データドリフト以外にも、ターゲットドリフトやモデルパフォーマンスも同様に行うことができます。そのため、機械学習サービスにドリフト検知の仕組みを簡単に整備することができます。
是非色々なデータセットで試してみてください。
参考文献
- https://github.com/evidentlyai/evidently
- https://docs.evidentlyai.com/
- https://archive.ics.uci.edu/ml/datasets/bike+sharing+dataset
