
こんにちは!
皆さんは機械学習モデルを作ろうとした時にデータが少なくても、思ったような精度が出ずに困ったことはないでしょうか。
筆者は機械学習を用いたプロジェクトで、「やりたいことはあるけど....データがない...ッ!」といつも困っていました。
今回は少ないデータでも精度の良いモデルが作れるかもしれない転移学習について解説をしていきます。
転移学習とはなにか
機械学習の分野で用いられる研究のテーマの1つで、意外と歴史は長く、1976年にステボ・ボジノフスキーとアンティ・フルゴシによって転移学習を用いた論文が初めて発表されました。
元々は心理学の分野で研究されており、機械学習の分野に応用をさせたものが、転移学習(Trasfer Learning)と呼ばれています。
転移学習というのは一言で言えば、「別の問題で得た知識を用いて、問題を解決するために知識を活用すること」になります。
イメージがしやすいように具体例をあげて考えてみます。
ピアノを10年やっていたAさんがいるとしましょう。Aさんは新しくギターを始めました。なかなか思うように指は動いてはくれませんが、音階やコードなどピアノで学んだ知識を活用して、ギターの知識をすぐに吸収してメキメキと上達しました。

この状態はまさに、先ほど紹介した転移学習の一例になります。
「別の問題で得た知識(ピアノ)を用いて、問題を解決(ギター)するために知識(ピアノの知識)を活用すること」
他にも例はたくさんあります。皆さんもぜひ身近な例を考えてみてください。
なぜ転移学習は注目されるのか
意外と歴史が長い転移学習ですが、特に注目されるようになったのは機械学習の権威であるアンドリュー・ウンが2016年にNIPSにて行った機械学習に関するチュートリアルの中で、「転移学習(Transfer Learning)は今後、非常に重要となる」という旨の内容を語った以降と言われています。

引用元: https://youtu.be/wjqaz6m42wU?t=5766
(動画の1:36:06から1:39:40秒まで転移学習(Transfer Learning)の重要性について語っている)
こちらのチュートリアルの内容は以下のページで詳細を確認できます。
https://ruder.io/transfer-learning/index.html
転移学習が注目されているのには大きく2つの理由があります。それぞれ順に解説していきます。
少ないデータでも高精度なモデルを構築可能
機械学習、特に深層学習を用いて問題解決をするためには必ずと言ってよいほど、大量のデータが必要になります。データ量が少なくても、高い精度を実現出来るモデルや創意工夫はあるでしょうが、一般的には精度を高くするのは難しいでしょう。
実際に企業や個人で機械学習を検討をする時に、データが大量にあることの方が稀です。世の中には有志の方がデータセットを公開している場合もありますが、目的にあったデータセットがあることも非常に稀です。
そんなデータ量が少ない状態でも転移学習であれば、精度の高いモデルを作れる可能性があります。
例えば、CNNを用いた画像分類の学習済みモデルは、画像についてどのように注目すれば良いのかを学習していると言われています。以下の記事ではCAM(Class Activation Mapping)という方法を用いて、CNNが画像のどこに注目しているのかをヒートマップで可視化したものになります。

引用元: https://github.com/jacobgil/pytorch-grad-cam
どうでしょうか。CNNを用いた犬と猫の画像分類の学習をさせたモデルがすでに画像どこに着目すれば良いのかを学習している様子がわかります。
例えば、この学習済みモデルを用いることで、少ないデータ量であっても、画像に対してどのように着目すれば良いのかをすでに習得している場合があります。そのため、高い精度のモデルを構築できる可能性があります。
(どのように画像に着目すれば良いのかだけでなく、その他にも学習している内容は考えられます)
短い時間で学習が可能
大量のデータを用いてモデルを学習させようとすると一般的には長い時間が必要になります。
高性能なマシンでGPUやTPUをガンガン使うことが出来るのあれば話は別ですが、金銭的な問題は避けることは難しいでしょう。ましてや機械学習を用いて上手くいくか分からない問題には予算の上限があることが多いです。
となると短い時間でモデルを学習させられないかと考えるわけですが、まさに転移学習の出番です。(学習時間が短い軽量のモデルを選択するという方法もあります)
転移学習では少ないデータでも高い精度のモデルを作れる可能性があります。データ量が少ないということは学習時間も短く済みます。これは…! まさにウィンウィンですね。
学習時間が短ければ、ハイパーパラメーターやデータの前処理などモデルの精度を向上させるためのに様々な方法を何度も試すことが出来ます。
転移学習の実装方法
転移学習では他のデータセットで学習済みのモデルを使用します。学習済みのモデルというのは各レイヤーの重みがすでにデータセットによって調整されている状態です。
この学習済みのモデルの末端に学習可能な重みを持つ層を追加します。この層は解決したい問題によって分類、回帰など任意の層と出力形式を選択します。
Nクラスの分類問題の場合
| base_model = tf.keras.applications.mobilenet_v2.MobileNetV2(...) # 学習済みモデルの重みは更新させない base_model.trainable = False model = tf.keras.Sequential([ base_model, tf.keras.layers.Dense(N, activation='softmax') ]) |
転移学習で実際に学習が行われるのは末端の層(tf.keras.layers.Dense)のみで、学習済みモデルの重みは更新しません。
別にファインチューニングという手法があり、そちらでは学習済みモデルの各層の重みを更新します。ファインチューニングについては改めて別の記事で解説します。
実際に転移学習をさせてみた
解説はここまでにして、実際に転移学習を用いることで精度が高いモデルを作ることが出来るのか試してみましょう。また転移学習を用いずに学習をしたモデルとの比較も行います。
今回、検証のために使用するのはkaggleで公開されているshoe-datasetです。画像にラベルが付与されており、画像に写っている靴が以下6種類のどれに該当するのかを予測するものです。
- boots(ブーツ)
- flip_flops(ビーチサンダル)
- loafers(ローファー)
- sandals(サンダル)
- sneakers(スニーカー)
- soccer_schoes(サッカー用のスパイク)
|
DATASET_DIR = "shoeTypeClassifierDataset" # 予想する6つのクラス |
2022年3月時点で、学習用のディレクトリにはそれぞれ249枚、合計1494枚の画像が用意されていました。
この内の90%(1344枚)を学習に使用し、残りの10%(150枚)は精度確認のために使用しました。
画像に対しては特別な前処理は行っておりません。単純なカラーのまま(rgb)、読み込みモデル入力のためにサイズを160x160に変換しました。
- 実装: tensorflow(tensorflow.keras)
- ImageNetを用いた学習済みモデルを使用
- 学習率: 0.0001
- エポック数: 50
- 最適化関数: tf.keras.optimizers.RMSpropを使用
- 損失関数: sparse_categorical_crossentropyを使用
※上記の設定はtensorflowの転移学習のチュートリアルを参考に設定しております。
転移学習: 学習済みvgg19
まずはvgg19を使って転移学習をさせてみます。vgg19は非常に多くの層と重みを持っており、自前で学習を行うのには骨が折れるモデルですが、転移学習なら簡単に試すことが出来ます。
| # define vgg model inputs = tf.keras.Input(shape=(160, 160, 3)) x = tf.keras.layers.Lambda(tf.keras.applications.vgg19.preprocess_input)(inputs) base_model = tf.keras.applications.vgg19.VGG19( weights='imagenet', input_tensor=x, input_shape=(160, 160, 3), include_top=False, pooling='avg' ) base_model.trainable = False model = tf.keras.Sequential([ base_model, tf.keras.layers.Dense(len(classes), activation='softmax') ]) model.summary() |

summaryの出力結果からモデルの構成を確認することが出来ます。ここで重要なのは下部にある3つの項目です。
- Total params: 全体の合計パラム数
- Trainable params: 学習されるパラム数
- Non-trainable params: 学習しても更新されないパラム数
続いてモデルをコンパイルします。設定はどのモデルも共通なので、以降、こちらの処理は割愛します。
| model.compile( optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.0001), loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) |
この時点でテストデータを用いて、精度を確認したところ約14%でした。ほぼ当てずっぽうですね。。
|
model.evaluate(test_images, test_labels, verbose=0) # [12.907177925109863, 0.14000000059604645] |
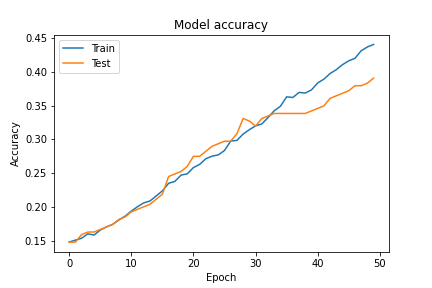
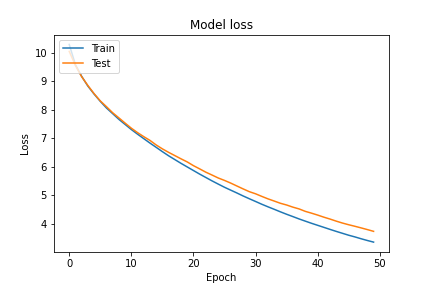
loss値も徐々に差下がり、エポックを増す毎に精度も向上していきました。学習時の最終的な精度は45%で、テストデータでの学習後の精度は約40%でした。まずまずの結果です。
| model.evaluate(test_images, test_labels, verbose=0) # [3.892406702041626, 0.4000000059604645] |
転移学習: 学習済みMobileNet V2
次は軽量で学習の早さに定評のあるMobileNetV2を試してみます。条件は先ほどのvgg19と全く同じです。
| inputs = tf.keras.Input(shape=(160, 160, 3)) x = tf.keras.layers.Lambda(tf.keras.applications.mobilenet_v2.preprocess_input)(inputs) base_model = tf.keras.applications.mobilenet_v2.MobileNetV2( weights='imagenet', input_tensor=x, input_shape=(160, 160, 3), include_top=False, pooling='avg' ) base_model.trainable = False model = tf.keras.Sequential([ base_model, tf.keras.layers.Dense(len(classes), activation='softmax') ]) model.summary() |
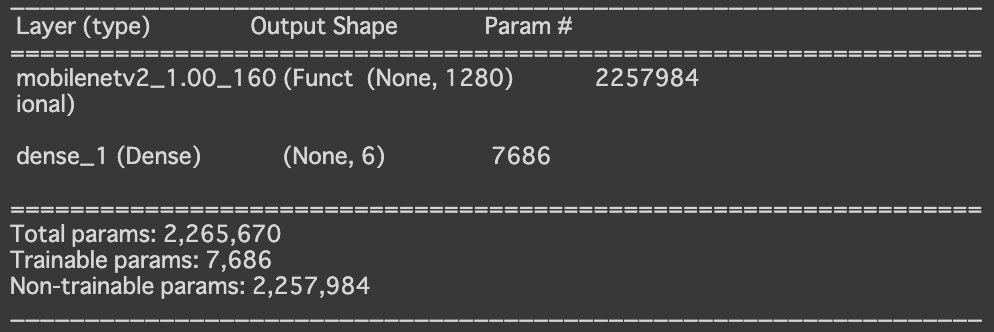
paramの値をvggと比べてみると一目瞭然ですが、vggでは20024384、MobileNetV2では2257984と1桁違うパラム数です。しかし、学習されるパラム数は 7686とvgg(3078)よりも多いので何やら期待が湧いてきます。
テストデータを用いた学習前の精度は約19%とvggよりいい感じです。
| model.evaluate(test_images, test_labels, verbose=0) # [2.3137614727020264, 0.19333332777023315] |
さて転移学習の結果はどうでしょうか。
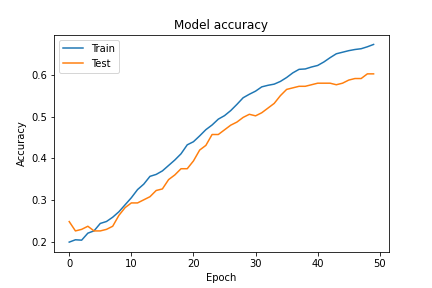
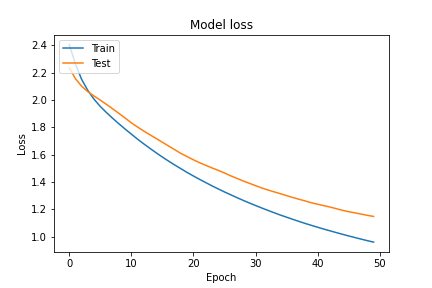
学習は順調に進んでいそうです。最終的には約67%まで精度が向上しました。テストデータでも確認してみます。
| model.evaluate(test_images, test_labels, verbose=0) # [1.078682780265808, 0.6200000047683716] |
同じ条件で学習をさせましたが、約62%とvggよりも良い結果を得ることが出来ました。
転移学習なし: MobileNetV2
MobileNetV2を用いて転移学習をしたら約62%という結果を得ることが出来ました。もし転移学習をしなかった場合と精度と学習時間にどれだけの差が出るのかが非常に気になります!
次は先ほど精度の良かったMobileNetV2について、転移学習をしなかった場合とどれだけ変わるものか検証してみましょう。データ数をはじめとした学習する条件は全く同じで学習をさせてみました。
| # 以下を削除するだけで全ての重みを学習させることが可能 base_model.trainable = False : model.summary() |
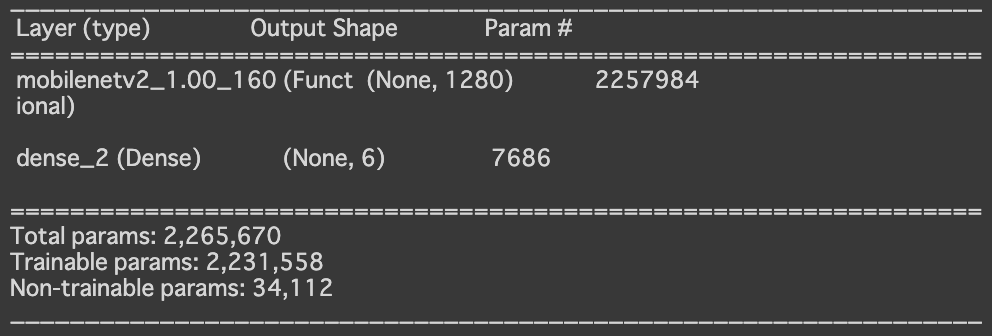
学習するパラム数が先ほどの7686から2231558に増えています。これは全ての層で重みを更新するためです。学習前のテストデータでの精度は約18%と、そこそこのスタートです。さっそくですが、転移学習の結果を見てみましょう。
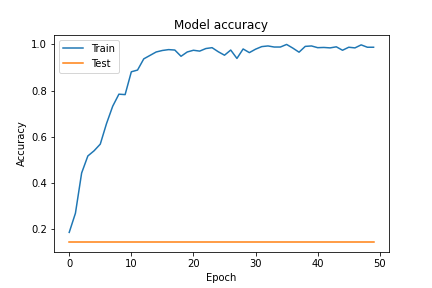
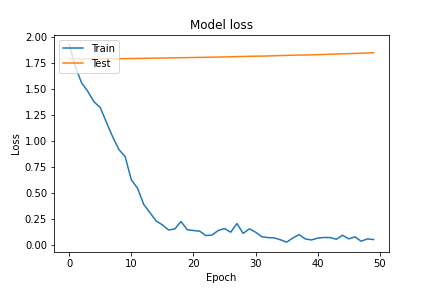
先ほどまでとは様子が違い、Trainでは高い精度、loss値の低下が成されていますが、Testでは散々な結果となっています。これは典型的な過学習の様子を表しています。
学習後のテストデータの精度はどうでしょうか。なんと約13%というほぼ当てずっぽうの精度となってしまいました。
| model.evaluate(test_images, test_labels, verbose=0) # [1.836161494255066, 0.13333334028720856] |
学習時間の比較
続いて、学習時間はどうでしょうか。先ほどMobileNetV2を転移学習で用いた際の経過時間は以下のようになりました。
| Epoch 1/50 5/5 [==============================] - 8s 625ms/step - loss: 2.2059 - accuracy: 0.1665 - val_loss: 2.1772 - val_accuracy: 0.1784 Epoch 2/50 5/5 [==============================] - 2s 379ms/step - loss: 2.1334 - accuracy: 0.1833 - val_loss: 2.1174 - val_accuracy: 0.1673 |
Epoch2以降は2s~3sあたりで落ち着いていたので、省略しました。
続いて、転移学習をしていないMobileNetV2の経過時間です。
| Epoch 1/50 5/5 [==============================] - 25s 2s/step - loss: 1.9747 - accuracy: 0.1712 - val_loss: 1.7918 - val_accuracy: 0.1784 Epoch 2/50 5/5 [==============================] - 6s 1s/step - loss: 1.6910 - accuracy: 0.2884 - val_loss: 1.7919 - val_accuracy: 0.1784 |
こちらもEpoch2以降は同じ理由で省略しています。Epoch1では転移学習をした場合は約8秒に対して、転移学習をしていない場合は約25秒という結果になりました。およそ3倍の速さで学習が行われているということが分かります。
以上より、転移学習を用いた場合には転移学習を用いていない場合と比較して、精度と学習時間の短さの2点で優れているということが確認出来ました。
| ※注意点: この結果は一例であり、全ての問題で同じ現象が発生するとは限りません。転移学習をしないと精度が出ないというわけではなく、データ量が少ない場合や適切なチューニングを行えば精度は向上する可能性があります。 |
まとめ
今回は転移学習について解説をしました。
転移学習とは「別の問題で得た知識を用いて、問題を解決するために知識を活用すること」です。ピアノを長年やっていた人はギターの習得も早いという例を挙げて解説しました。
転移学習が注目されているのは、データが少なくても精度の高いモデルを作れる可能性がある、学習時間が短くて済むという2つの利点があるためです。実装時には、学習済みモデルの重みは更新せずに、末端に新たに学習可能な重みを持つ層を追加させます。
今回は転移学習を用いることで、少ないデータ数でも60%を超える精度を実現することが出来ました。便利な転移学習ですが、どのケースでも必ず上手くいくというわけではないということには注意が必要です。
参考文献
- https://www.kaggle.com/noobyogi0100/shoe-dataset
- https://child-programmer.com/ai/cnn-originaldataset-samplecode/
- https://note.nkmk.me/python-tensorflow-keras-transfer-learning-fine-tuning/
- https://github.com/jacobgil/pytorch-grad-cam
- https://www.analyticsvidhya.com/blog/2021/06/how-to-load-kaggle-datasets-directly-into-google-colab/
- https://keras.io/ja/visualization/
- https://www.tensorflow.org/tutorials/images/transfer_learning?hl=ja
- https://www.tensorflow.org/api_docs/python/tf/keras/applications/mobilenet_v2/MobileNetV2
