 こんにちは!nakamura(@naka957)です。前回記事に引き続き、機械学習を少ないコードで実装できるPyCaretをご紹介します。
こんにちは!nakamura(@naka957)です。前回記事に引き続き、機械学習を少ないコードで実装できるPyCaretをご紹介します。
【前回の記事】AutoMLライブラリPyCaretを使ってみた〜モデル実装から予測まで〜
PyCaretとは
PyCaretはAutoML(Auto Machine Learning)を簡単に行えるPythonライブラリです。オープンソースのため誰でも無料で利用できます。
大きな特徴として、少ないコード行数で多数の機械学習アルゴリズムを比較できることが挙げられます。そのため、この機能を用いて最適な機械学習アルゴリズムの検討・選択・実装のサイクルを簡単かつ迅速に行うことが可能です。
本記事ではPyCaretで実装した機械学習モデルを用いて、結果の描画方法をご紹介します。機械学習モデルの実装や予測については前回記事を参考にしてみてください。
また、以降で紹介するコードはJupyter Notebook上での実行を想定しています。また、PyCaretはバージョン 2.3.6で実装しています。
では早速、本題に入っていきましょう。
(復習) 機械学習モデルの実装
前回記事でご紹介した、機械学習モデルの実装を簡単にご説明します。詳細は前回記事を参照ください。
機械学習モデルの実装までのプロセスは次のステップで行いました。
- データセットの準備
- 実験環境の設定
- 機械学習モデルの比較・定義
- ハイパーパラメーター調整
また、実装コードは次の通りです。ただし、前回記事から一部簡略化してあります。
# ライブラリーの読み込み from pycaret.regression import * from pycaret.datasets import get_data # データセットの準備 dataset = get_data('diamond') # データセットの分割(訓練と検証用) train_df = dataset.sample(frac=0.9, random_state=0) test_df = dataset.drop(train_df.index) # indexを再設定 train_df.reset_index(drop=True, inplace=True) test_df.reset_index(drop=True, inplace=True) # 実験環境の設定 s = setup(data=train_df, target='Price', session_id=0) # モデルの比較 compare_models() # モデル定義 et = create_model( 'et', # アルゴリズム名を指定 cross_validation=True, # CVの実施有無 fold=4, # CVのfold数 ) # ハイパーパラメーター調整 tuned_model = tune_model( et, # モデルインスタンスを指定 optimize='RMSE', # 評価指標 fold=4, # CVのfold数 )
以上が、データセット準備から、モデル比較と定義、ハイパーパラメーター調整による機械学習モデルの実装になります。
ここから、結果の描画方法をご紹介していきます!
結果の描画
作成したモデルの結果を確認しましょう。plot_model関数を使用します。最初の引数にモデルインスタンスを渡し、引数plotで描画種類を指定します。
以下で、代表的な描画方法をご紹介していきます。
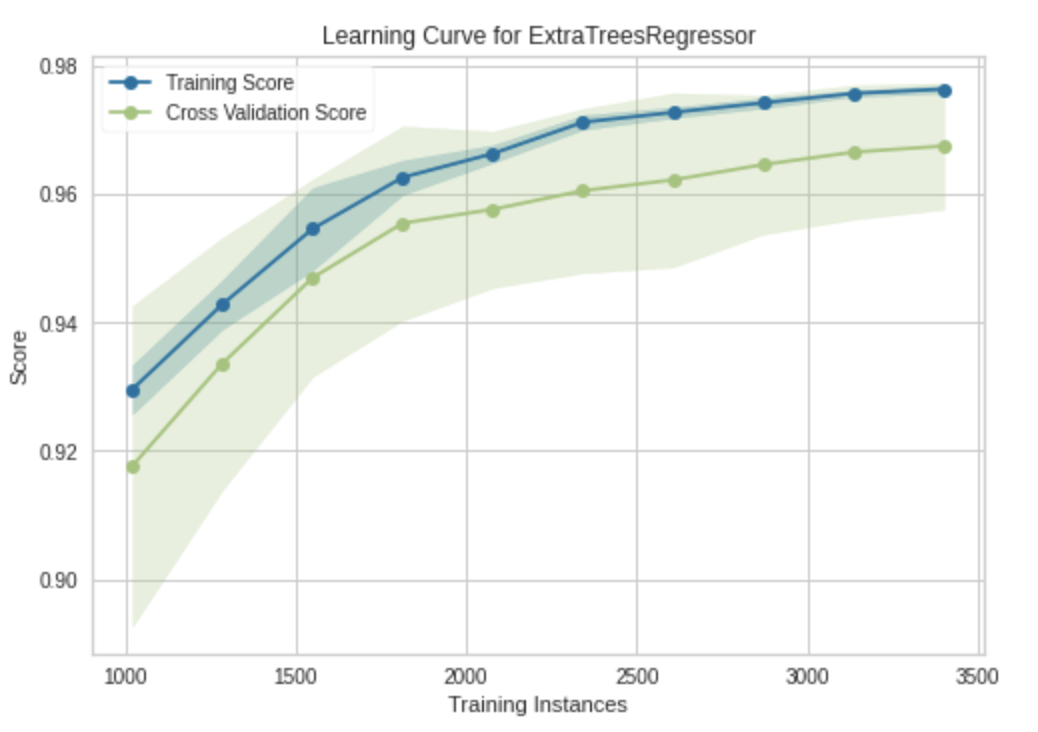
学習曲線
plot_model(tuned_model, plot = 'learning')
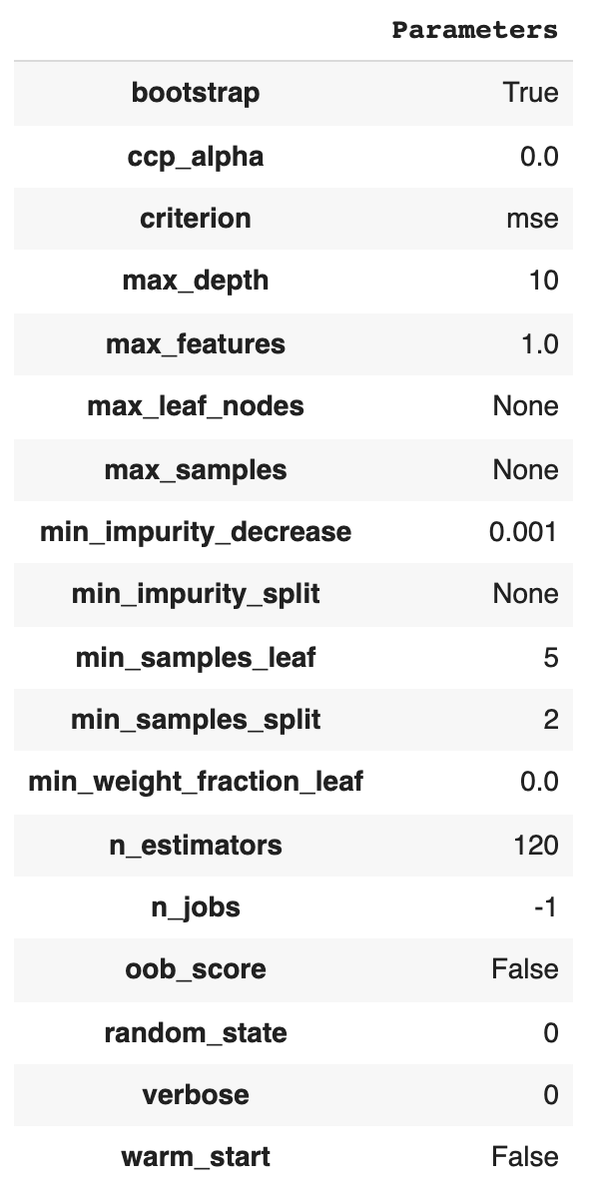
ハイパーパラメーター
plot_model(tuned_model, plot = 'parameter')
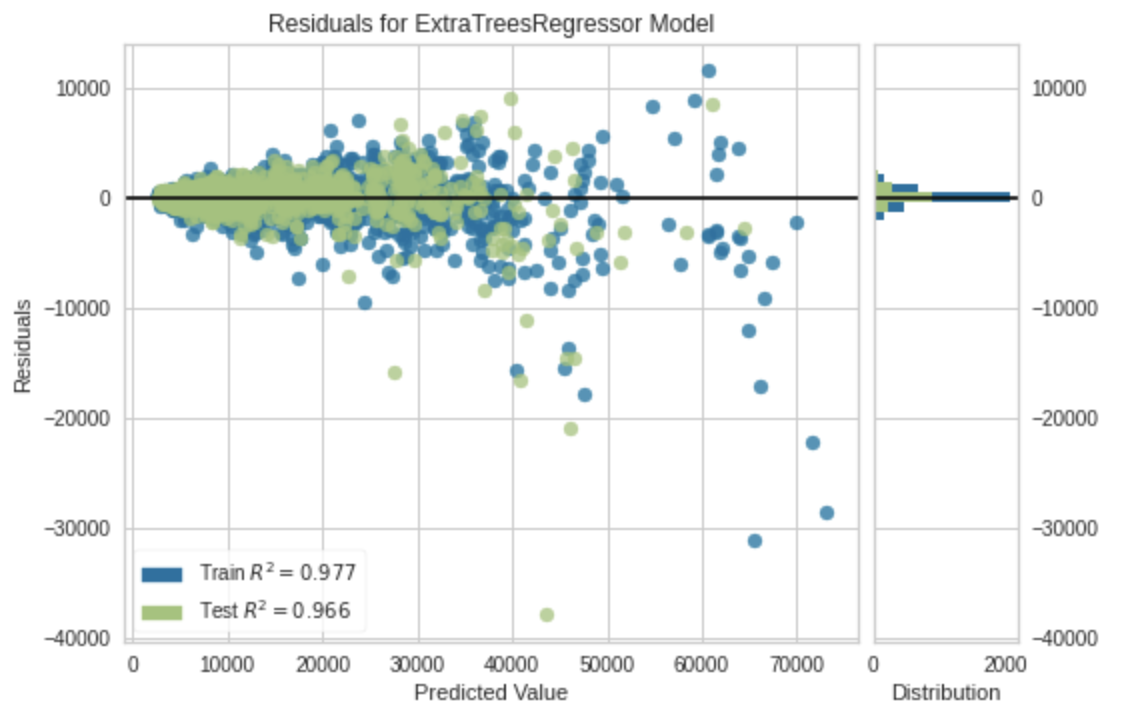
残差プロット
plot_model(tuned_model, plot = 'residuals')
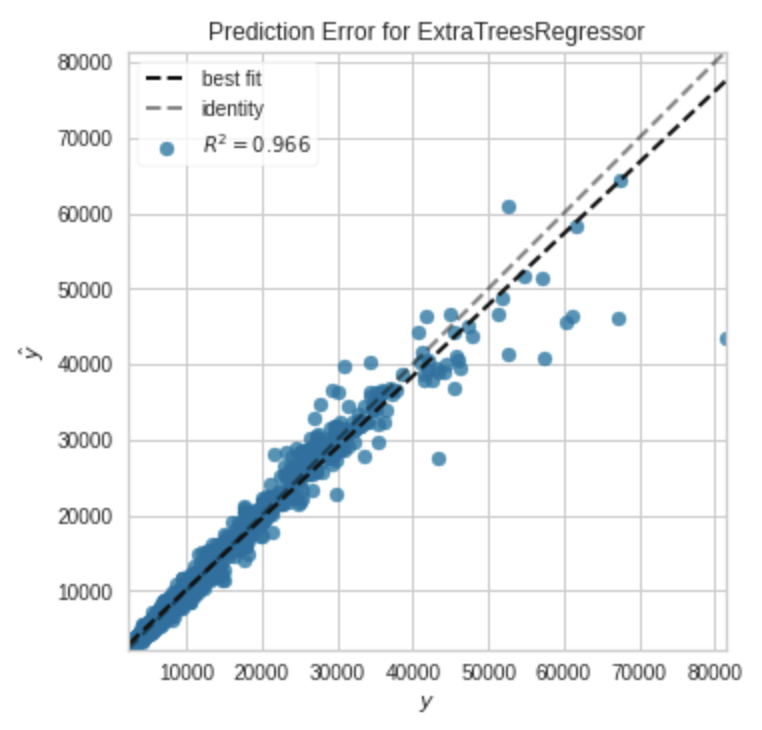
予測結果 vs 教師データ
plot_model(tuned_model, plot = 'error')
特徴量(入力変数)の重要度
plot_model(tuned_model, plot = 'feature')
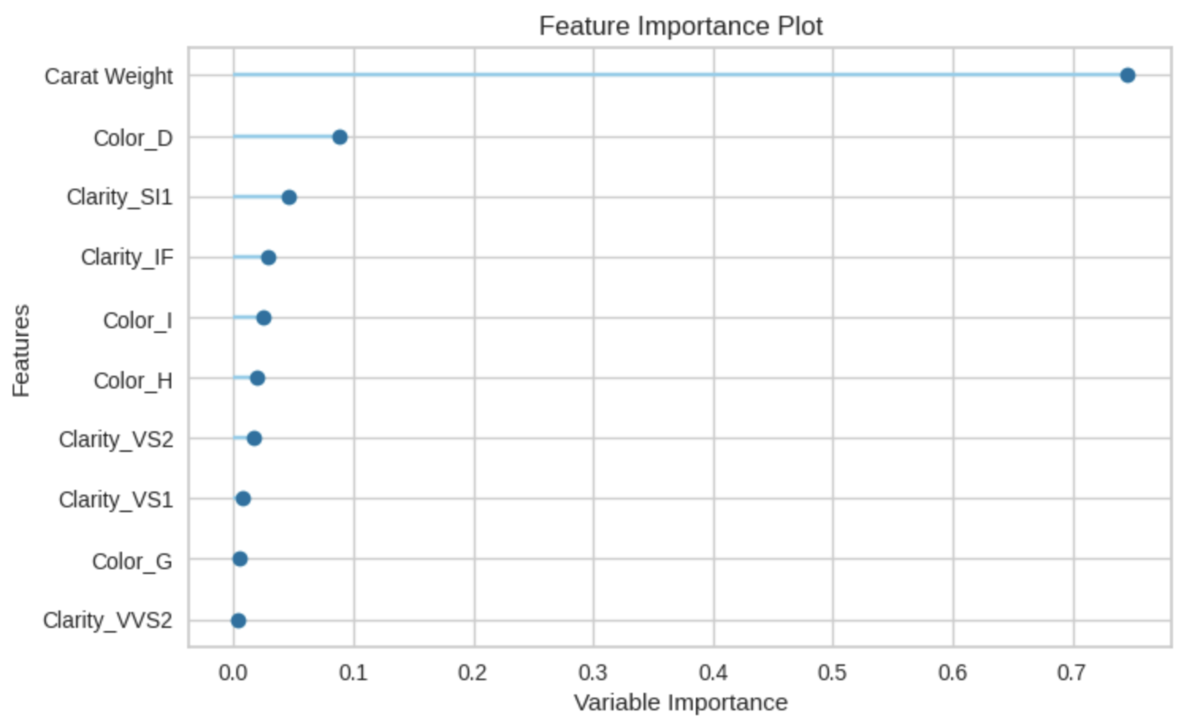
特徴量の重要度はSHAP(SHapley Additive exPlanations)の指標でも可視化できます。その場合は、plot_model関数でなく、interpret_model関数を使用します。
ただし、事前にshapライブラリのインストールが必要です。
$ pip install shap
SHAP
interpret_model(tuned_model)
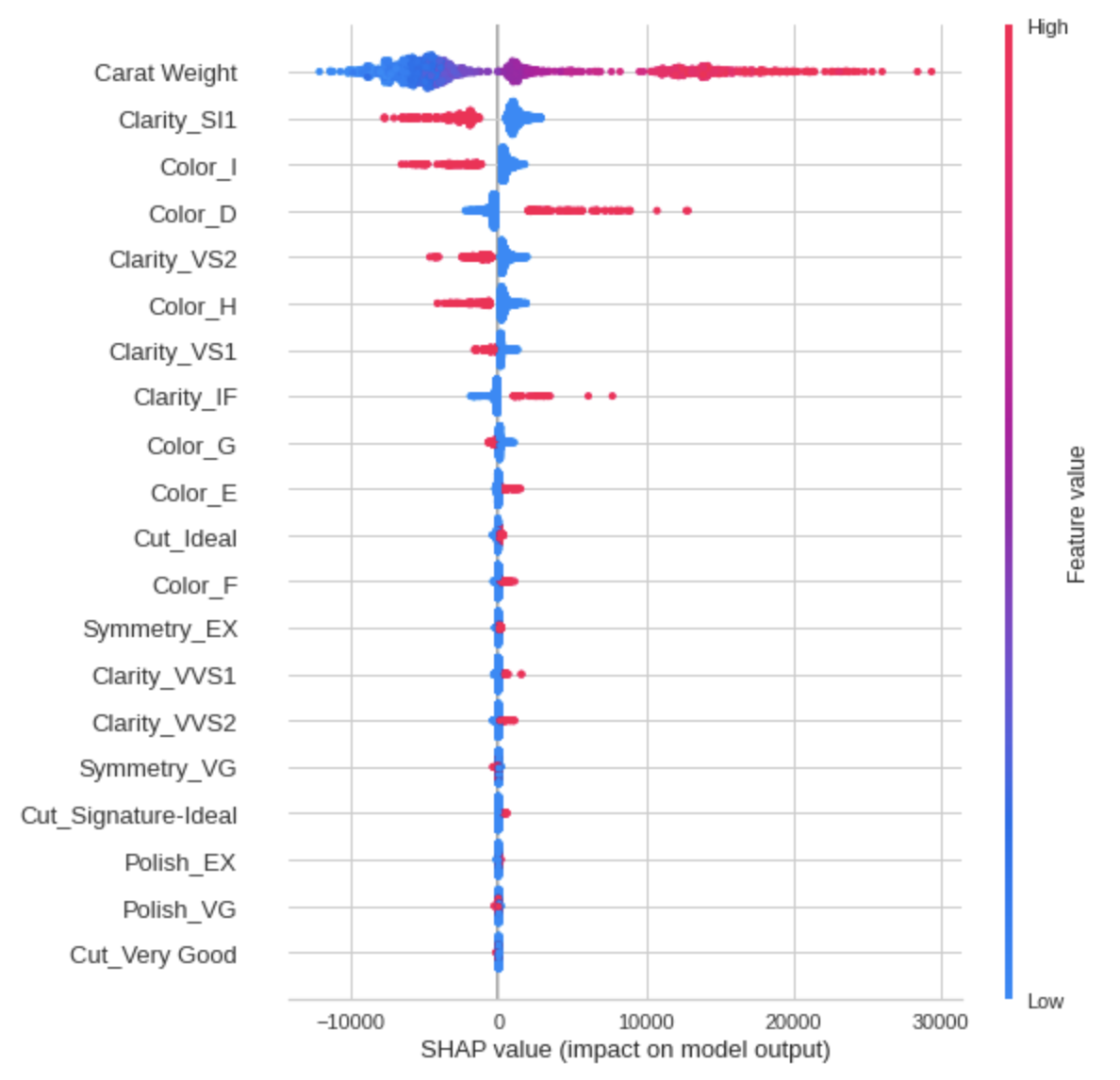
描画方法の紹介は以上です。これらの機能を用いることで、様々な角度からデータ分析を行えます。
最後に、作成したモデルの保存と読み込み方法をご紹介します。
モデルの保存・読み込み
作成したモデルはsave_model関数で保存できます。引数には、モデルインスタンスと保存ファイル名を渡します。
save_name = 'pycaret_model'
save_model(final_model, save_name)
また、保存したモデルを読み込む場合は、loaded_model関数を使用します。引数に保存ファイル名を渡します。
loaded_model = load_model(save_name)
まとめ
PyCaretで作成したモデルを用いて、結果の描画を行いました。機械学習モデルの実装だけでなく、様々な種類の描画を行うことができます。
今回は回帰分析を例にご紹介しましたが、他にもPyCaretには分類問題、クラスタリング、異常検知、自然言語処理といった様々な機能が実装されています。是非、使ってみてください!
参考文献
- Introduction to Regression in Python with PyCaret (https://towardsdatascience.com/introduction-to-regression-in-python-with-pycaret-d6150b540fc4)
- PyCaret 101 — for beginners (https://medium.com/analytics-vidhya/pycaret-101-for-beginners-27d9aefd34c5)
(おまけ) PyCaretのインストール
PyCaretのインストールはpipもしくはcondaコマンドで簡単にインストールできます。
pip環境の場合
$ pip install pycaret
conda環境の場合
$ conda install pycaret
バージョンを指定したい場合は、次のように指定することも可能です。
$ pip install pycaret==2.3.6
